spark pipeline原理学习和记录
概念
MLlib提供标准的机器学习算法API,能够方便的将不同的算法组合成一个独立的管道,或者叫工作流。
• DataFrame:ML API使用Sark SQL中的DataFrme作为机器学习数据集,可容纳各种类型的数据,如DataFrame可能是存储文本的不同列,特征向量,真正的标签或者预测。
• 转换器:Transformer是一种算法,可以将一个DataFrame转换成另一个DataFrame。如机器学习模型是一个转换器,可以将特征向量的DataFrame转换成预测结果的DataFrame。
• 预测器:一个预测是一个算法,可以基于DataFrame产出一个转换器。如机器学习算法是一种预测,训练DataFrame并产生一个模型。
• 管道/工作流:管道链接多个转换器和预测器生成一个机器学习工作流。
• 参数:所有的转换器和预测器共享一个通用的API指定参数。
MLlib standardizes APIs for machine learning algorithms to make it easier to combine multiple algorithms into a single pipeline, or workflow. This section covers the key concepts introduced by the Pipelines API, where the pipeline concept is mostly inspired by the scikit-learn project.
• DataFrame: This ML API uses DataFrame from Spark SQL as an ML dataset, which can hold a variety of data types. E.g., a DataFrame could have different columns storing text, feature vectors, true labels, and predictions.
• Transformer: A Transformer is an algorithm which can transform one DataFrame into another DataFrame. E.g., an ML model is a Transformer which transforms a DataFrame with features into a DataFrame with predictions.
• Estimator: An Estimator is an algorithm which can be fit on a DataFrame to produce a Transformer. E.g., a learning algorithm is an Estimator which trains on a DataFrame and produces a model.
• Pipeline: A Pipeline chains multiple Transformers and Estimators together to specify an ML workflow.
• Parameter: All Transformers and Estimators now share a common API for specifying parameters.
DataFrame
机器学习可以处理多种类型的数据,比如矢量/文本/图像和结构化数据,这里DataFrame API源于Spark SQL,主要用来处理各种类型的数据。
DataFrame支持简单的和结构化类型,同时支持ML中常用的vector,可以从规则的RDD中显示或者隐式的构建。
Machine learning can be applied to a wide variety of data types, such as vectors, text, images, and structured data. This API adopts the DataFrame from Spark SQL in order to support a variety of data types.
DataFrame supports many basic and structured types; see the Spark SQL datatype reference for a list of supported types. In addition to the types listed in the Spark SQL guide, DataFrame can use ML Vector types.
A DataFrame can be created either implicitly or explicitly from a regular RDD. See the code examples below and the Spark SQL programming guide for examples.
Columns in a DataFrame are named. The code examples below use names such as “text,” “features,” and “label.”
Pipeline components
PipeLine组件
1.转换器
转换器是一个抽象概念,他包括特征转换和模型学习,继承transform方法,这个方法可以将一个DataFrame转换成另一个,通常为添加一列或者多个列。如
(1) 一个特征转换对于DataFrame的操作可能为,读取一个列,将他映射成为一个新的列,然后输出一个新的DataFrame。
(2) 一个模型学习对于DataFrame的操作可能为,读取包含一组特征的列,然后预测结果,最后将添加预测结果的新数据输出为一个DataFrame。
Transformers
A Transformer is an abstraction that includes feature transformers and learned models. Technically, a Transformer,implements a method transform(), which converts one DataFrame into another, generally by appending one or more columns. For example:
• A feature transformer might take a DataFrame, read a column (e.g., text), map it into a new column (e.g., feature vectors), and output a new DataFrame with the mapped column appended.
• A learning model might take a DataFrame, read the column containing feature vectors, predict the label for each feature vector, and output a new DataFrame with predicted labels appended as a column.
2.预测器
Estimators
预测器是学习算法或者其他算法的抽象,用来训练数据。预测器继承fit方法,可以接收一个DataFrame输入,然后产出一个模型。例如,像逻辑回归算法是一种预测,调用fit方法来训练一个逻辑回归模型。
An Estimator abstracts the concept of a learning algorithm or any algorithm that fits or trains on data. Technically, an Estimator implements a method fit(), which accepts a DataFrame and produces a Model, which is a Transformer. For example, a learning algorithm such as LogisticRegression is an Estimator, and calling fit() trains a LogisticRegressionModel, which is a Model and hence a Transformer.
Properties of pipeline components
Pipleline组件的属性
Transformer.transform()和 Estimator.fit()都是无状态的。在将来,可能会被有状态的算法替代。每个转换器和预测器都有一个唯一的ID,这在参数调节中很有用处。
Transformer.transform()s and Estimator.fit()s are both stateless. In the future, stateful algorithms may be supported via alternative concepts.
Each instance of a Transformer or Estimator has a unique ID, which is useful in specifying parameters (discussed below).
Pipeline
在机器学习中,很常见的一种现象就是运行一系列的算法来学习数据。例如一个简单的文本执行可能包括以下几步:
(1) 文档分词
(2) 每个词转成向量
(3) 使用向量和标签学习一个预测模型
In machine learning, it is common to run a sequence of algorithms to process and learn from data. E.g., a simple text document processing workflow might include several stages:
• Split each document’s text into words.
• Convert each document’s words into a numerical feature vector.
• Learn a prediction model using the feature vectors and labels.
MLlib represents such a workflow as a Pipeline, which consists of a sequence of PipelineStages (Transformers and Estimators) to be run in a specific order. We will use this simple workflow as a running example in this section.
How it works
管道被指定为一系列阶段,每个阶段是一个转换器或一个预测器。这些阶段按顺序运行,输入DataFrame每个通过每个阶段时进行转换。对于转换阶段,transform方法作用在DataFrame上。预测阶段,调用fit()方法并产出一个Transformer(PipelneModel的一部分)。
通过文档分析的工作流来解释pipleline。
A Pipeline is specified as a sequence of stages, and each stage is either a Transformer or an Estimator. These stages are run in order, and the input DataFrame is transformed as it passes through each stage. For Transformer stages, the transform() method is called on the DataFrame. For Estimator stages, the fit() method is called to produce a Transformer(which becomes part of the PipelineModel, or fitted Pipeline), and that Transformer’s transform() method is called on the DataFrame.
We illustrate this for the simple text document workflow. The figure below is for the training time usage of a Pipeline.
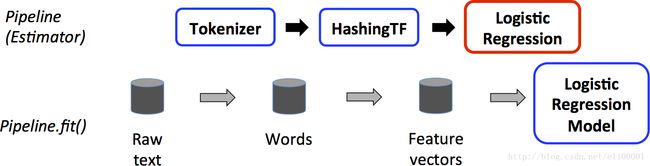
上图中,第一行表示一个Pipleline,包含三个阶段。其中Tokenizer和HashingTF是转换,第三个LogiticRegression逻辑回归是预测。下面一行表示数据流向,(1)对于Raw text文本数据和标签生成DataFrame,然后调用Pipeline的fit接口;(2)调用Tokenizer的transform接口将文本进行分词,并将分词添加到DataFrame;(3)pipleline调用LogiticRegression.fit产出一个LogiticRegressionModel。
一个pipeline是一个预测,fit方法执行之后,产出一个PipeLineModel,这是一个转换器,可以用在测试中。
Above, the top row represents a Pipeline with three stages. The first two (Tokenizer and HashingTF) are Transformers (blue), and the third (LogisticRegression) is an Estimator (red). The bottom row represents data flowing through the pipeline, where cylinders indicate DataFrames. The Pipeline.fit() method is called on the original DataFrame, which has raw text documents and labels. The Tokenizer.transform() method splits the raw text documents into words, adding a new column with words to the DataFrame. The HashingTF.transform() method converts the words column into feature vectors, adding a new column with those vectors to the DataFrame. Now, since LogisticRegression is an Estimator, the Pipeline first calls LogisticRegression.fit() to produce a LogisticRegressionModel. If the Pipeline had more stages, it would call the LogisticRegressionModel’s transform() method on the DataFrame before passing the DataFrame to the next stage.
A Pipeline is an Estimator. Thus, after a Pipeline’s fit() method runs, it produces a PipelineModel, which is a Transformer. This PipelineModel is used at test time; the figure below illustrates this usage.

在上图中,PipelineModel和原始工作流有相同数量的阶段,但在原来的管道中的预测已成为转换。当PipelineModel在测试数据集上调用transform接口时,这些数据是按照顺序通过管道。每个阶段的transform方法更新数据并将其传递到下一个阶段。
管道和PipelineModels有助于确保训练和测试数据经过相同的处理步骤。
In the figure above, the PipelineModel has the same number of stages as the original Pipeline, but all Estimators in the original Pipeline have become Transformers. When the PipelineModel’s transform() method is called on a test dataset, the data are passed through the fitted pipeline in order. Each stage’s transform() method updates the dataset and passes it to the next stage.
Pipelines and PipelineModels help to ensure that training and test data go through identical feature processing steps.
DAG
DAG管道:管道的阶段被指定为一个有序数组。这里给出的示例都是线性管道,即每个阶段使用前一个阶段产生的数据。也可以创建非线性管道,数据流图形成一个有向无环图(DAG)。这张图是目前隐式地指定每个阶段输入和输出列的名称(通常指定为参数)。如果管道形成DAG,那么必须指定拓扑秩序。
运行时检查:由于管道可以操作不同类型的DataFrames,不能在编译时检查出错误类型。管道和PipelineModels在管道实际运行之前检查,使用DataFrame的schema模式检查,这个模式就是DataFrame中的列的数据类型。
唯一的管道阶段:管道的阶段应该是唯一的实例。如,相同的实例myHashingTF不应该插入管道两次,因为管道阶段必须有唯一的id。然而,不同实例myHashingTF1和myHashingTF2(都是HashingTF型)可以放在相同的管道,因为不同的实例在创建时是不同的id。
DAG Pipelines: A Pipeline’s stages are specified as an ordered array. The examples given here are all for linear Pipelines, i.e., Pipelines in which each stage uses data produced by the previous stage. It is possible to create non-linear Pipelines as long as the data flow graph forms a Directed Acyclic Graph (DAG). This graph is currently specified implicitly based on the input and output column names of each stage (generally specified as parameters). If the Pipeline forms a DAG, then the stages must be specified in topological order.
Runtime checking: Since Pipelines can operate on DataFrames with varied types, they cannot use compile-time type checking. Pipelines and PipelineModels instead do runtime checking before actually running the Pipeline. This type checking is done using the DataFrame schema, a description of the data types of columns in the DataFrame.
Unique Pipeline stages: A Pipeline’s stages should be unique instances. E.g., the same instance myHashingTF should not be inserted into the Pipeline twice since Pipeline stages must have unique IDs. However, different instances myHashingTF1 and myHashingTF2 (both of type HashingTF) can be put into the same Pipeline since different instances will be created with different IDs.
Parameters
MLlib的预测和转换使用统一的API来指定参数。一个参数是一个包含参数属性值的属性名称,一个ParamMap由一组(参数名称,值)这样的对组成。
有两种传参的方法:
(1) 为实例设置参数。
(2) 将参数封装到ParamMap,然后解析ParamMap为fit和transform传递参数。ParamMap的参数将覆盖原始的参数。
MLlib Estimators and Transformers use a uniform API for specifying parameters.
A Param is a named parameter with self-contained documentation. A ParamMap is a set of (parameter, value) pairs.
There are two main ways to pass parameters to an algorithm:
1. Set parameters for an instance. E.g., if lr is an instance of LogisticRegression, one could call lr.setMaxIter(10) to make lr.fit() use at most 10 iterations. This API resembles the API used in spark.mllib package.
2. Pass a ParamMap to fit() or transform(). Any parameters in the ParamMap will override parameters previously specified via setter methods.
Parameters belong to specific instances of Estimators and Transformers. For example, if we have two LogisticRegressioninstances lr1 and lr2, then we can build a ParamMap with both maxIter parameters specified: ParamMap(lr1.maxIter -> 10, lr2.maxIter -> 20). This is useful if there are two algorithms with the maxIter parameter in a Pipeline.
Saving and Loading Pipelines
通常保存一个模型或工作流到磁盘供以后使用。一个模型导入/导出功能添加到管道API。支持最基本的转换以及一些更基本的ML模型。请参考算法的API文档确认保存和加载是否支持。
Often times it is worth it to save a model or a pipeline to disk for later use. In Spark 1.6, a model import/export functionality was added to the Pipeline API. Most basic transformers are supported as well as some of the more basic ML models. Please refer to the algorithm’s API documentation to see if saving and loading is supported.