python爬取网易云音乐歌曲评论信息
首先,我们打开网易云音乐的网页版:https://music.163.com/,随便选择一首歌曲,如林志炫版本的《烟花易冷》:https://music.163.com/#/song?id=25723157。透过网址很容易发现每首歌都有一个对应的id。所以原则上我们只要搜素对应歌曲进到播放页,就能得到每首歌的网址还有其id号。换言之,只要我们能爬一首歌的评论内容,原则上就可以轻易做成循环,爬取多首歌的所有评论了。
进入网页的“最新评论区”,我们每点击底下的“下一页”,网站的url并没有任何变化,说明整个评论区的内容都是通过Ajax异步请求技术得到的。打开浏览器F12,进入开发者工具,选择Network,在凌乱的数据包中,我们选择XHR(XmlHttpRequest)就可以筛选出Ajax的请求包:
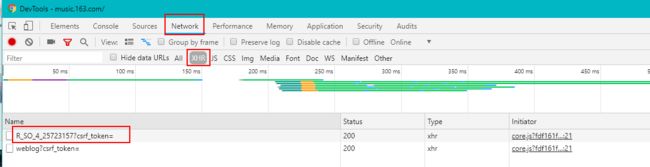
根据上图的Initiator字段,我们很容易知道这个url请求的触发js文件-core.js和对应地址:https://s3.music.126.net/web/s/core.js?fdf161fd0a1799f7c23ec9c48ada5d1f.我们姑且将它在浏览器下打开,右键save as保存到本地。
根据name字段,很容易发现"R_SO_4_"后面紧跟的25723157正是歌曲的id。我们双击第一个name进入,界面右边清晰显示,此处请求的url为:
https://music.163.com/weapi/v1/resource/comments/R_SO_4_25723157?csrf_token=
界面如下:
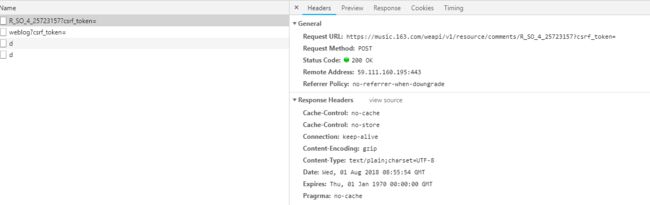
通过General下Request Method:字段,清晰看到这是一个post请求。我们可以根据页面信息清晰构造请求url以及请求头headers,至于data字段:params:以及encSecKey:杂乱,看不出什么规律:
-
params:
hF0h1ltDyC7QxVba4h3X9QDPlcV1PlskubPgFA5I7raqfLal7mCSoDkfsx5E9ljZxENaLhbVJEAPSuOT4j6jV+uJ70/rt5EoehnZTVy4PrcFlbuIOXg6n8HLKRRVpaZVDrDLkLanUn9kr9U2+93M9MZzIpObtFWlY4eqJ1/2BQ+VEnyJ8wnAMYBvYv1ctvKV
-
encSecKey:
86ea0c77d5ab69f26f3f24638bc80758ebba86c0a28b8024db2065b21d4e885816ee463aa3020378007d90a83f83e81bea5f09dfc3433e0df46d82488124127af220dfef0d5c71d0029de68e7b8c836e9f4dc3162a662bcfd2af1fac98bf12dbe6e4a6be7e1b48b4fcee1ee7970cbd0149c33d3a78cc11956345b6b50a8f5ad8
我们不停点击网页评论区下一页,进行抓包,发现每一页对应的form data中params以及encSecKey字段内容都是不一样的,所以如果不能找到规律,我们就只能爬取第一页的热门评论和最新评论,做不到翻页爬取所有评论。
还好知乎上热心的大神“平胸小仙女”已经完成了探索并还原了整个加密过程,附上参考信息:https://www.zhihu.com/question/36081767,感兴趣的可以参考其讲解。
这里需要分析前文拿到的core.js文件,由于该js文件非常庞大,我们可以根据关键词encSecKey检索,定位到关键代码段,也就有了下面提到的几个重要加密函数:
仔细分析这段函数,并在浏览器F12控制台下运算,发现a(16)每次都是随机生成一段长度为16的随机字符串。
> function a(a){var d,e,b="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789",c="";for(d=0;a>d;d+=1)e=Math.random()*b.length,e=Math.floor(e),c+=b.charAt(e);return c}
< undefined
> a(16)
< "WugFoWvqBro7YomO"
> a(16)
< "TNIMHadoojG3O1yJ"function b(a,b){
var c=CryptoJS.enc.Utf8.parse(b),
d=CryptoJS.enc.Utf8.parse("0102030405060708"),
e=CryptoJS.enc.Utf8.parse(a),
f=CryptoJS.AES.encrypt(e,c,{iv:d,mode:CryptoJS.mode.CBC});
return f.toString()
}function e(a,b,d,e){
var f={};
return f.encText=c(a+e,b,d),f
}
function c(a,b,c){var d,e;return setMaxDigits(131),d=new RSAKeyPair(b,"",c),e=encryptedString(d,a)}
观察function b 函数,可以看到密钥偏移量iv是0102030405060708,模式是CBC,加密方法是AES。
观察function a函数,由于其随机性,我们可以假定i=a(16)=F*16,化繁为简,不会影响加密过程。
function d(d,e,f,g){
var h={},
i=a(16);
return h.encText=b(d,g),
h.encText=b(h.encText,i),
h.encSecKey=c(i,e,f),h
}至此算是拿到了加密算法,下面就可以愉快的爬取了
'''
想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载!
'''
import sys
import codecs
import requests,json,os
import base64
import Crypto
from Crypto.Cipher import AES
class Spider():
def __init__(self,idNum):
#user-Agent字段直接从浏览器中复制过来即可,请求头中其他字段非必须项,也可以从浏览器中找到所有字段都放到Request Headers
self.header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0',
'Referer': 'http://music.163.com/'}
self.url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_'+idNum+'?csrf_token=' #每一次的base_url只有歌曲id不同,构造url即可。
def __get_jsons(self,url,page):
# 获取两个参数
music = WangYiYun()
text = music.create_random_16()
params = music.get_params(text,page)
encSecKey = music.get_encSEcKey(text)
fromdata = {'params' : params,'encSecKey' : encSecKey}
jsons = requests.post(url, data=fromdata, headers=self.header)
#print(jsons.raise_for_status())
# 打印返回来的内容,是个json格式的
#print(jsons.content)
return jsons.text
def json2list(self,jsons):
'''把json转成字典,并把他重要的信息获取出来存入列表'''
# 可以用json.loads()把它转成字典
#print(json.loads(jsons.text))
users = json.loads(jsons)
comments = []
for user in users['comments']:
# print(user['user']['nickname']+' : '+user['content']+' 点赞数:'+str(user['likedCount']))
name = user['user']['nickname']
content = user['content']
# 点赞数
likedCount = user['likedCount']
#提取所需json中所需的字段构造字典
user_dict = {'name': name, 'content': content, 'likedCount': likedCount}
#将提取的字典信息追加到列表中
comments.append(user_dict)
return comments
def run(self,idNum):
self.page = 1
while True:
jsons = self.__get_jsons(self.url,self.page)
comments = self.json2list(jsons)
non_bmp_map = dict.fromkeys(range(0x10000, sys.maxunicode + 1), 0xfffd)
## print(str(comments[0]).translate(non_bmp_map))
print('self.page = '+str(self.page)) #控制台打印正在爬取的页码数
print(idNum) #打印正在爬取的歌曲id
#在该脚本同级目录下生成“comments”文件夹
dirName = u'{}'.format('comments')
if not os.path.exists(dirName):
os.makedirs(dirName)
with open(".\comments\\"+idNum+".txt","a",encoding='utf-8') as f: #结果写入txt文件
## print(len(comments))
for ii in range(len(comments)):
f.write(str(comments[ii]).translate(non_bmp_map))
f.write('\n')
## print(ii)
f.close()
# 当这一页的评论数少于20条时,证明已经获取完
## self.write2sql(comments)
if len(comments) < 100 : #当limits设置为100时,默认每次服务器请求结果100条comments,当小于此数,意味爬到最后一页。
print('评论已经获取完')
break
self.page +=1
# 找出post的两个参数params和encSecKey
class WangYiYun():
def __init__(self):
# 在网易云获取的三个参数
self.second_param = '010001'
self.third_param = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
self.fourth_param = '0CoJUm6Qyw8W8jud'
def create_random_16(self):
'''获取随机十六个字母拼接成的字符串'''
return (''.join(map(lambda xx: (hex(ord(xx))[2:]), str(os.urandom(16)))))[0:16]
def aesEncrypt(self, text, key):
# 偏移量
iv = '0102030405060708'
# 文本
pad = 16 - len(text) % 16
text = text + pad * chr(pad) #补齐文本长度
encryptor = AES.new(bytearray(key,'utf-8'), AES.MODE_CBC, bytearray(iv,'utf-8'))
# encryptor = AES.new(key, 2, iv)
ciphertext = encryptor.encrypt(bytearray(text,'utf-8'))
## print(bytearray(key,'utf-8'))
ciphertext = base64.b64encode(ciphertext)
return ciphertext
def get_params(self,text,page):
'''获取网易云第一个参数'''
# 第一个参数
if page == 1:
self.first_param = '{rid: "", offset: "0", total: "true", limit: "100", csrf_token: ""}'
#rid: "R_SO_4_557581284",经测试该值可以置空,不影响结果的执行。
else:
self.first_param = '{rid: "", offset:%s, total: "false", limit: "100", csrf_token: ""}'%str((page-1)*20) #limit参数可以灵活设置,默认为20,设置为100,爬取效率可以提高
params = self.aesEncrypt(self.first_param, self.fourth_param).decode('utf-8')
params = self.aesEncrypt(params, text)
return params
def rsaEncrypt(self, pubKey, text, modulus):
'''进行rsa加密'''
text = text[::-1]
rs = int(codecs.encode(text.encode('utf-8'), 'hex_codec'), 16) ** int(pubKey, 16) % int(modulus, 16)
return format(rs, 'x').zfill(256)
def get_encSEcKey(self,text):
'''获取第二个参数'''
pubKey = self.second_param
moudulus = self.third_param
encSecKey = self.rsaEncrypt(pubKey, text, moudulus)
return encSecKey
def main():
idPs = ['557581284','32019002'] #花粥《纸短情长》以及Zedd / Jon Bellion的《beautiful now》,可根据需要在网易云音乐查找歌曲ID后替换,列表元素越多,爬取的循环次数越多
for jj in range(len(idPs)):
idNum = idPs[jj]
spider = Spider(idNum) #根据Spider类实例化spider对象
spider.run(idNum) #调用spider对象的run方法
if __name__ == '__main__':
main()