简书博客列表爬取
最近在学习使用xpath解析网页!就尝试对简书的博客爬取!首先是单个用户的博客文章爬取!之后便继续尝试爬取简书网站中用户列表前100页的用户的文章!
首先是单个用户文章信息的爬取,主要信息包括:标题、文章链接、摘要、beta、阅读量、评论数、喜爱数、以及发布时间。
废话不多说,先上代码:
import requests
from lxml import etree
import os
#/html/body/div[1]/div/div[1]/div[1]/div[2]/ul/li[3]/div/a/p
def getResponse(url):
#伪装浏览器
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0',
'Connection': 'close'}
try:
r = requests.get(url, headers=header, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r
except:
return 0
def ResponseParse(r, alist):
if r:
dom = etree.HTML(r.text)
bate_site = 'https://www.jianshu.com'
# print(str(dom.xpath('/html/body/div[1]/div/div[1]/div[2]/ul/li[4]/div/div/span[3]/text()')))
li_path = './/div[@id="list-container"]/ul/li'
title_path = './/a[@class="title"]/text()'
href_path = './/a/@href'
abstract_path = './/div/p[@class="abstract"]/text()'
beta_path = './/div/div/span[@class="jsd-meta"]/i[@class="iconfont ic-paid1"]'
read_path = './/div/div/a/i[@class="iconfont ic-list-read"]'
comment_path = './/div/div/a/i[@class="iconfont ic-list-comments"]'
love_path = './/div/div/span/i[@class="iconfont ic-list-like"]'
time_path = './/div/div/span[@class="time"]/@data-shared-at'
lis = dom.xpath(li_path)
for li in lis:
article_lsit = []
# print(etree.tostring(li, method='html', encoding='utf-8'))
title = li.xpath(title_path)[0]
href = li.xpath(href_path)[0]
abstract = li.xpath(abstract_path)[0]
link = bate_site + href
if title:
article_lsit.append(title)
print("标题:" + str(title))
else:
article_lsit.append("无")
if link:
print("链接:" + link)
article_lsit.append(link)
else:
article_lsit.append("None")
if abstract:
print("摘要:" + abstract.strip().replace("\n", ""))
article_lsit.append(abstract.strip().replace("\n", ""))
else:
print("摘要:" + "无")
article_lsit.append("无")
betas_ = li.xpath(beta_path)
if betas_:
betas = betas_[0].xpath('../text()')
print("beta:", str(betas[1]).strip().replace("\n", ""))
article_lsit.append(str(betas[1]).strip().replace("\n", ""))
else:
print("beta:", 0)
article_lsit.append("0")
reads_ = li.xpath(read_path)
if reads_:
reads = reads_[0].xpath('../text()')
print("阅读量:", str(reads[1]).strip().replace("\n", ""))
article_lsit.append(str(reads[1]).strip().replace("\n", ""))
else:
print("阅读量:", 0)
article_lsit.append("0")
comments_ = li.xpath(comment_path)
if comments_:
comments = comments_[0].xpath('../text()')
print("评论数:", str(comments[1]).strip().replace("\n", ""))
article_lsit.append(str(comments[1]).strip().replace("\n", ""))
else:
print("评论数:", 0)
article_lsit.append("0")
likes_ = li.xpath(love_path)
if likes_:
likes = likes_[0].xpath('../text()')
print("喜爱数:", str(likes[0]).strip().replace("\n", ""))
article_lsit.append(str(likes[0]).strip().replace("\n", ""))
else:
print("喜爱数:", 0)
article_lsit.append("0")
time = li.xpath(time_path)
print("发布时间:" + str(time)[2:-8])
article_lsit.append(str(time)[2:-8])
print('\n')
alist.append(article_lsit)
return len(lis)
else:
print("爬取失败!")
def Get_Total_Article(url):
r = getResponse(url)
dom = etree.HTML(r.text)
article_num = int(dom.xpath('//div[@class="info"]//li[3]//p/text()')[0].strip())
return article_num
def Get_author_name(url):
#/html/body/div[1]/div/div[1]/div[1]/div[1]/a
r = getResponse(url)
dom = etree.HTML(r.text)
author_name = dom.xpath('.//div[@class="main-top"]/div[@class="title"]/a[@class="name"]/text()')[0].strip()
return author_name
def WriteTxt(alist, name):
save_dir = '文章列表'
save_dir = os.path.join(os.getcwd(), save_dir)
if not os.path.exists(save_dir):
os.mkdir(save_dir)
save_name = os.path.join(save_dir, name)
out = "标题:{0:{8}<10}\n链接:{1:{8}<10}\n摘要:{2:{8}<20}\nbeta:{3:{8}<10}\n阅读量:{4:{8}<10}\n评论数:{5:{8}<10}\n喜爱数:{6:{8}<10}\n发布时间:{7:{8}<10}\n"
with open(save_name, 'w', encoding="utf-8") as f:
for i in range(len(alist)):
f.write(out.format(alist[i][0], alist[i][1], alist[i][2], alist[i][3], alist[i][4], alist[i][5], alist[i][6], alist[i][7], chr(12288)))
f.write("\n")
f.close()
print("数据成功写入:"+save_name)
def main():
url = url_ + "?order_by=shared_at&page={}"
print(url)
author_name = Get_author_name(url.format(1))
save_name = author_name + ".txt"
article_total_count = Get_Total_Article(url.format(1))
if article_total_count%9 == 0:
spider_num = int(article_total_count/9)
else:
spider_num = int(article_total_count/9) + 1
article_count = 0
# print(article_total_count/9)
artile_list = []
for i in range(spider_num):
spider_url = url.format(str(i + 1))
r = getResponse(spider_url)
article_count += ResponseParse(r, artile_list)
WriteTxt(artile_list, save_name)
print("作者:" + author_name + "共爬取了:" + str(article_count) + "篇文章!")
if __name__ == '__main__':
main()
程序解释
接下来对程序中的几个重要方法进行解释。
getResponse(url)用于获取链接对应的响应,简书的反爬措施相对简单,只需要将headers伪装成浏览器即可。
程序的重头戏便是对获取的响应进行解析。该功能在ResponseParse(r, alist)中实现,其中参数alist用于存储文章信息。
以https://www.jianshu.com/u/cbe095ae3d58为例,我们查看网页的源代码(f12)
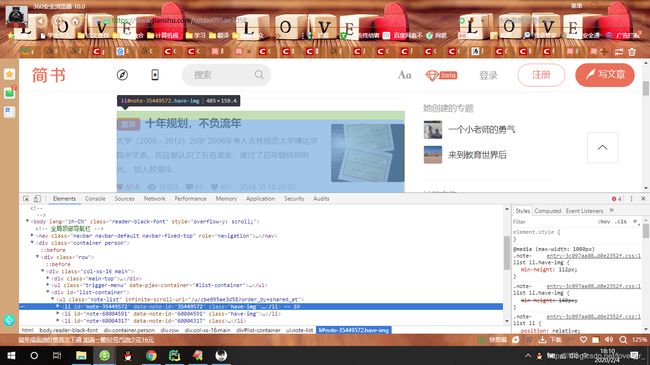
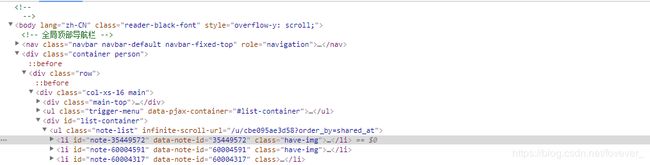
我们可以清晰的看到在个人主页中所有的文章列表信息位于标签中,于是我们写出标签的xpath信息
li_path = './/div[@id="list-container"]/ul/li'
用于获取所有的标签。进一步查看源代码,从而找到我们所需信息相对于标签的相对路径。
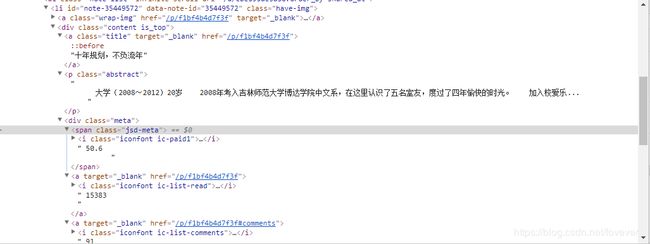
根据观察到的源代码信息,能够写出所有所需信息的的xpath:
title_path = './/a[@class="title"]/text()'
href_path = './/a/@href'
abstract_path = './/div/p[@class="abstract"]/text()'
beta_path = './/div/div/span[@class="jsd-meta"]/i[@class="iconfont ic-paid1"]'
read_path = './/div/div/a/i[@class="iconfont ic-list-read"]'
comment_path = './/div/div/a/i[@class="iconfont ic-list-comments"]'
love_path = './/div/div/span/i[@class="iconfont ic-list-like"]'
time_path = './/div/div/span[@class="time"]/@data-shared-at'
值得注意的是,在写beta、阅读量、评论数、喜爱数的xpath路径时,一直写到了所需标签的下一级标签,这主要是因为在调试程序的时候发现有的文章有beta信息,有的确没有,而有的文章却有赞赏的信息。他们都位于标签中,如果按顺序列举标签就会出现错乱的情况。所以使用下一级标签来定位所需信息所在的标签。当我们需要当前信息时则使用“..”回退到上一级标签并获取其中包含的文本信息。
在获取发布时间时也遇到了问题,如果使用.//div/div/span[@class="time"]/text()'便无法获取其中的时间信息,所以只能想办法获取其data-shared-at属性值。
在解析文本时也对获取的数据进行了清洗,当获取的信息不存在时,则人为为其赋值。
本文的数据结构是将每一篇文章的信息构造一个列表,然后每获取一篇信息就将其增加到alist列表中。
当我们需要获取某一个标签或者元素的xpath路径时可以在源代码中选中改元素,然后右键再点击copy,选择copy xpath
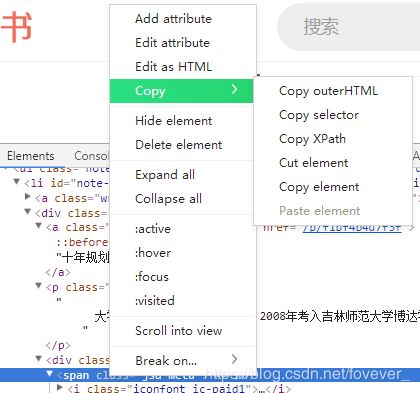
另外每个人构造的xpath不一定相同,所以可以自己尝试按照自己的理解构造xpath
其实在对网页进行解析之后差不多完成了爬虫的功能,但是为了消除下拉加载对我们的爬虫造成的影响。进一步观察网页的url,发现https://www.jianshu.com/u/cbe095ae3d58?order_by=shared_at&page=1
链接中page的值能够控制网页的显示,而且每一个page对应9篇文章信息发现了这个规律,便可以计算出每一位作者需要爬虫爬取的url的次数。
因此需要获取作者文章的总数。于是有写了Get_Total_Article(url):方法,其实就是对网页进行解析,获得对应路径处的文本。
至此,爬虫便能循环爬取文章信息,直至将某一作者所有文章信息爬取完毕。
当我们想将爬取的信息保存到本地时,我们便需要在写一个保存数据的方法,为了唯一标识保存作者信息的文档,以作者主页的昵称命名文档,所以我们有写了Get_author_name(url)方法。
于是乎爬虫便能自动爬取简书中某一作者的所有文章信息。
效果如图:

之后在爬取某一作者的文章信息的基础上便尝试爬取简书网站大部分作者的文章信息边保存。简书全网爬取文章信息的介绍将在一篇博客中介绍。