【信息抽取】如何使用卷积神经网络进行关系抽取
事物、概念之间的关系是人类知识中非常重要的一个部分,但是他们通常隐藏在海量的非结构文本中。为了从文本中抽取这些关系事实,从早期的模式匹配到近年的神经网络,大量的研究在多年前就已经展开。
然而,随着互联网的爆炸发展,人类的知识也随之飞速的增长,因而对关系抽取(Relation Extraction, RE)提出了更高的要求,需要一个有效的RE系统,能够利用更多的数据;有效的获取更多的关系;高效的处理更多复杂的文本;具有较好的扩展性,能够迁移到更多的领域。
本文首先介绍一种基于卷积神经网络的关系抽取方法。
作者&编辑 | 小Dream哥
1 导论
在引入深度学习之前,在NLP领域,关系抽取最优的方法是基于机器学习的方法。机器学习的方法依赖手动提取特征,手动提取的特征通常依赖于其他的NLP系统(一些NLP工具),这些工具不免会带入错误,这些错误就会在关系抽取的任务中进行传播。
因此,基于机器学习的关系抽取方法代价大且效果不佳。这里介绍一种比较早的应用深度卷积神经网络进行关系抽取的方法,由神经网络进行特征抽取,避免了手动的特征提取,实现了端到端的关系抽取。
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classifification via convolutional deep neural network. In Proceedings of COLING, pages 2335–2344.
2 网络结构
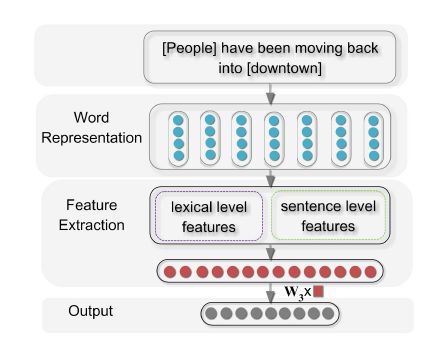
如上图所示是该基于深度卷积神经网络的模型框架图,从图中可知,模型的输入是一段话,并指明了句子中的2个实体;输出为一个特征向量,表征了这两个实体的关系。该结构主要分为3个部分:词嵌入、特征抽取以及输出。
1)词嵌入(Word Representation)
词嵌入就是目前NLP领域最普通的词嵌入,每一个输入词语转化成一个固定维度的向量。这个向量是从预先训练好的词向量字典中查找得到,这份词向量字典中的词向量表征了词之间的语义关系。
2) 特征抽取层
鉴于关系分类是一个复杂的任务,模型需要学习实体的词语级特征和整个句子的语义级别的特征,才能完成关系的分类。
因此模型的特征抽取包括两个部分,词语级特征抽取和句子级特征抽取。词语级的特征抽取提取局部的词语级的信息,句子级的特征抽取提取全局的语义信息,二者结合提高模型的准确性。
1.词语级特征抽取(Lexical Level Features)
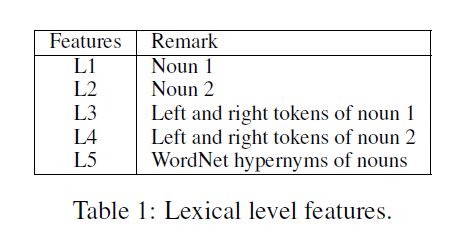
如上图所示,词语级特征包括3个部分,
第一部分是词语(待分类的实体)本身;
第二部分是词语左右的词;
第三部分是词语的上位词,通过wordNet获取得到。
这三个部分的通过词嵌入之后,拼接在一起就构成了词语级的特征。
2.句子级特征抽取(Sentence Level Features)
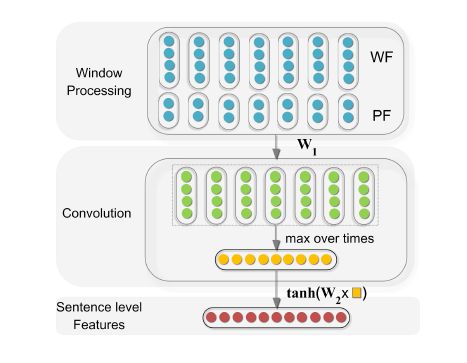
词向量虽然能够一点程度的表征词语之间的关系及相似度,但是在关系抽取任务中,通常需要在当前语境的关系下学习两个词之间的关系。有时候两个词语之间的距离还会比较远,这就需要模型要能够表征长距离的特征及语义特征。
为此,模型设计了一个Convolution层,用于句子级的语义特征抽取。
首先,Convolution层的输入包括两个部分,Word Feature和Position feature。
Word Feature是由一定大小的窗口,拼接起来的特征。假设,输入序列经过词嵌入之后的序列为(X1,X2,...Xn),假设窗口的大小为3,则Word Feature构建成这样:
{[Xs,X1,X2],[X1,X2,X3],...[Xn-1,Xn,Xe]}
通过这种方式,能够一定程度的提取句子的局部特征。但是全局特征,仍需要其他模块来提取。
模型中的Position feature是相对距离,记录的是当前词与两个待预测实体之间的相对距离,PF=[d1, d2],并且初始化成一定维度的向量。
最后将两种特征拼接起来X=[WF,PF]构成句子级特征抽取的输入。
随后的Convolution层非常的简单,主要包括如下的3步:
第一步,线性变换:

第二步,最大层池化:
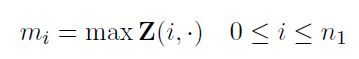
池化的维度是序列延展的方向。通过最大层池化,提取出最有效的特征。
第三步,激活函数:
![]()
3) 输出层
将词语级特征和句子级特征拼接起来,[Y,g],接一个全连接层,获得模型的特征向量O,最后再接一个softmax层,输出两个词属于预定义关系类别的概率。
模型训练采用常用的随机梯度下降和方向传播算法,这里就不再赘述。
总结
本文介绍了一种基于深度学习的关系抽取的方法,这是用深度学习处理关系抽取任务最早的工作之一了,避免了早期用机器学习方法的人工特征提取,取得了当时最好的效果。
用现在的眼光来看这个模型,可能觉得稍显“粗陋”,例如,局部特征和全局特征分开抽取,简陋的卷积网络、最大池化的操作值得商榷。但看看早期的工作能够更好的理解目前的NLP工作,更深刻的理解目前的BERT等新工作的做法。
下期预告:基于循环神经网络的关系抽取
知识星球推荐

扫描上面的二维码,就可以加入我们的星球,助你成长为一名合格的自然语言处理算法工程师。
知识星球主要有以下内容:
(1) 聊天机器人。
(2) 知识图谱。
(3) NLP预训练模型。
转载文章请后台联系
侵权必究


往期精选
【完结】 12篇文章带你完全进入NLP领域,掌握核心技术
【年终总结】2019年有三AI NLP做了什么,明年要做什么?
【NLP-词向量】词向量的由来及本质
【NLP-词向量】从模型结构到损失函数详解word2vec
【NLP-NER】什么是命名实体识别?
【NLP-NER】命名实体识别中最常用的两种深度学习模型
【NLP-NER】如何使用BERT来做命名实体识别
【NLP-ChatBot】我们熟悉的聊天机器人都有哪几类?
【NLP-ChatBot】搜索引擎的最终形态之问答系统(FAQ)详述
【NLP-ChatBot】能干活的聊天机器人-对话系统概述
【知识图谱】人工智能技术最重要基础设施之一,知识图谱你该学习的东西
【知识图谱】知识表示:知识图谱如何表示结构化的知识?
【知识图谱】如何构建知识体系:知识图谱搭建的第一步
【知识图谱】获取到知识后,如何进行存储和便捷的检索?
【知识图谱】知识推理,知识图谱里最“人工智能”的一段
【文本信息抽取与结构化】目前NLP领域最有应用价值的子任务之一
【文本信息抽取与结构化】详聊文本的结构化【上】
【文本信息抽取与结构化】详聊文本的结构化【下】
【信息抽取】NLP中关系抽取的概念,发展及其展望
【NLP实战】tensorflow词向量训练实战
【NLP实战系列】朴素贝叶斯文本分类实战
【NLP实战系列】Tensorflow命名实体识别实战
【NLP实战】如何基于Tensorflow搭建一个聊天机器人
【NLP实战】基于ALBERT的文本相似度计算
【每周NLP论文推荐】从预训练模型掌握NLP的基本发展脉络
【每周NLP论文推荐】 NLP中命名实体识别从机器学习到深度学习的代表性研究
【每周NLP论文推荐】 介绍语义匹配中的经典文章
【每周NLP论文推荐】 对话管理中的标志性论文介绍
【每周NLP论文推荐】 开发聊天机器人必读的重要论文
【每周NLP论文推荐】 掌握实体关系抽取必读的文章
【每周NLP论文推荐】 生成式聊天机器人论文介绍
【每周NLP论文推荐】 知识图谱重要论文介绍
【NLP预训练模型】你finetune BERT的姿势可能不对哦?