【实例分割_SOLOv1】SOLO: Segmenting Objects by Locations_2019
文章目录
- 一、背景
- 二、本文方法
- 三、本文方法的具体做法
- 3.1 问题定义
- 3.1.1 Semantic category
- 3.1.2 Instance Mask
- 3.2 Network Architecture
- 3.3 SOLO learning
- 3.3.1 Label Assignment
- 3.3.2 Loss Function
- 3.4 Inference
- 四、实验
- 4.1 主要结果
- 4.2 How SOLO works?
- 4.3 Ablation Experiments
- 4.4 SOLO-512
- 五、Decoupled SOLO
- 七、Conclusion

论文:https://arxiv.org/abs/1912.04488
代码:https://github.com/WXinlong/SOLO
一、背景
实例分割具有很大的挑战性,因为它需要正确分离图像中的所有对象,同时还需要在像素级对每个实例进行语义分割。图像中的对象属于一组固定的语义类别,但是实例的个数是未知的,所以,语义分割可以被看做是一个密集的分类问题(对每个像素进行分类),直接利用分类的方法来预测每个像素的类别是一个很大的挑战。
现有的方法是怎么做的:
- top-down:也就是“先检测,后分割”,先检测 bbox,后在每个bbox中进行mask的分割
- bottom-up:学习关系亲和场,给每个 pixel 分配一个嵌入式向量,将属于不同实例的 pixel 推远,把属于同一个实例的 pixel 拉近。之后,需要一个后处理来分开每个实例。
上述方法的特点: 分步实现 + indirect,前者很大程度上基于检测结果的准确性,后者很大程度上依赖于嵌入式向量的学习和 grouping prcessing.
二、本文方法
本文旨在于直接分割实例 mask。
作者提出的问题: 图像中实例的本质区别是什么?
解答:
以 MS COCO为例,验证集中有 36780 个目标
- 98.3% 的目标对儿的中心距离大于 30 pixels
- 1.7% 的目标对儿中,其中 40.5% 的大小之比大于 1.5x
总结:在大多数情况下,图像中的两个实例,要么中心位置不同,要么大小不同。
反思:是否可以通过中心位置和对象大小直接区分实例?
SOLO:Seperate Object instances by Location and sizes
在语义分割中,现在主流的方法是使用FCN来输出N个通道的密集预测,每个输出通道负责其中一个语义类别(包括背景),语义分割的目的是区分不同的语义范畴,在本文中,引入“实例类别”的概念来区分图像中的对象实例,即量化的中心位置和对象大小,这使得可以利用位置来分割对象,故名为“SOLO”。
Locations: 图像被分为 S × S S \times S S×S 的格子,得到 S 2 S^2 S2 个中心位置类别
根据目标中心,每个目标实例被分配到其中一个格子内,作为其中心位置的类别。本文将中心位置的类别编码成 channel axis,类似于语义分割中的语义类别。
每个输出通道都是对每个中心位置类别的响应,对应的 channel 的特征图可以预测属于该类别的实例的mask。所以,结构化的几何信息自然地保存在空间矩阵中。
实际上,实例类别近似于实例的对象中心位置,因此,通过将每个 pixel 分类到其实例类别中,就相当于使用回归方法从每个像素来预测对象中心。
将位置预测任务转化为分类而不是回归任务的原因在于: 使用分类时,更加直接,且更易于使用固定数量的通道对多个实例进行建模,同时不依赖于分组或学习嵌入式向量之类的后处理。
Sizes:使用 FPN 来区分不同大小的目标实例,以便将不同大小的对象分配给不同 level 的特征图,作为对象大小类别。
所有的实例都被规则的分配,使得能够通过 “instance categories” 来区分类别。
注意:FPN是本文的核心之一,因为它对分割性能有着很大的影响,尤其是对不同大小的物体。
SOLO效果:
- 端到端训练,且无后处理
- 只需要mask的标注信息,无需 bbox 标注信息,
- 在 COCO 上实现了和 Mask R-CNN 基本持平的效果
- SOLO 只需要解决两个像素级的分类问题,类似于语义分割,
- 本质上,SOLO 通过离散量化,将坐标回归转化为分类问题,可以避免启发式的坐标规范化和 log 变换,通常用于像 YOLO 这样的检测器中。
三、本文方法的具体做法
3.1 问题定义
给定一个任意的图像,实例分割系统需要确定是否有需要分割的实例, 如果有,则返回分割的 mask。
SOLO 的核心想法:将实例分割问题转化为两个问题:类别预测+实例 mask 生成
- 将输入图像分成格子 : S × S S\times S S×S
- 如果目标的中心落到格子里边,则这个格子要 输出实例类别(semantic category)+ 分割实例(segmenting instance)
3.1.1 Semantic category
对于每个 grid, SOLO 会预测 C 维的输出,分别代表每个类别的置信得分,C 为类别个数。把图像划分为 S × S S\times S S×S 个格子,输出就是 S × S × C S \times S \times C S×S×C,如图2_top所示。
该设计方法是基于一个假设:每个格子都只属于一个单独的实例。
推理阶段:C 维输出表示每个实例属于不同类别的概率
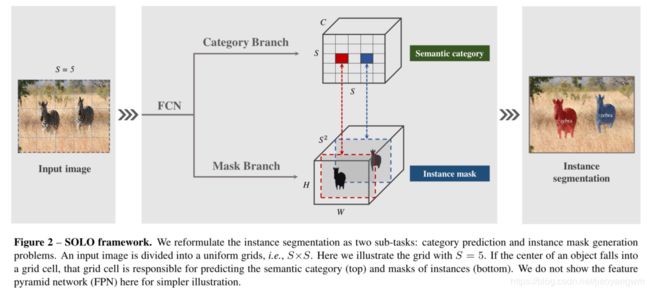
3.1.2 Instance Mask
和类别预测并列的分支是实例mask预测分支,该分支对每个 positive grid cell 产生一个对应的 instance mask。
对于输入图像 I I I,将其分为 S × S S\times S S×S 的格子,则最多会预测 S 2 S^2 S2 个格子,将这些 mask 编码成一个 3D 输出的tensor,输出有3维,也就是3个通道。则, instance mask 分支的输出维度为: H I × W I × S 2 H_I \times W_I \times S^2 HI×WI×S2。 k t h − c h a n n e l k_{th}-channel kth−channel 是对 ( i , j ) (i,j) (i,j) 位置的分割响应,其中 k = i × S + j k= i\times S + j k=i×S+j。最后,在 semantic category 和 class-agnostic mask 之间建立了一对一的对应关系(图2所示)。
现有的方法如何预测实例掩码: 采用 FCN
不足:传统的卷积在运算上具有空间不变性,图像分类需要空间不变性,但语义分割模型需要对空间变化敏感的模型,因为这个模型是以 grid cell 为条件的,所以必须由不同的特征通道来分开。
本文方法如何实现预测 mask: 网络开头的地方,直接给网络输入归一化后的 pixel 坐标(参考 CoordConv operator[14])。也就是建立一个和原始的输入尺寸相同的 tensor,这个 tensor 里边的 pixel 的坐标被归一化到 [-1,1]。之后,将该 tensor concat 到输入特征,并传递到之后的层。为了使得卷积能够访问其自己的输入坐标,本文将空域 functionality 加到 FCN 模型中。
假设原始特征 tensor 尺寸为 H × W × D H \times W \times D H×W×D,新的 tensor 尺寸为 H × W × ( D + 2 ) H \times W \times (D+2) H×W×(D+2),其中,最后的两个 channels 是 x − y x-y x−y pixel 坐标。
Forming Instance Segmentation: SOLO中,类别的预测和对应的 mask 可以很自然的使用其 grid cell 来联系起来, k = i ⋅ S + j k=i \cdot S + j k=i⋅S+j。基于此,可以直接对每个 grid 来建立最终的实例分割结果。
原始的实例分割结果是通过将所有 grid 的结果结合起来得到的,之后,使用 NMS 来获得最终的实例分割结果,没有其他后处理。
3.2 Network Architecture
SOLO 使用 FPN 作为 backbone,FPN 在每个 level 产生固定通道但不同大小的特征图(通道通常为256-d),这些特征图作为预测 head 的输入:semantic category head + instance mask head。同一个head的不同 level的参数是共享的。不同 level 的grid number 是不同的。另外,只有最后的 1x1 conv 的参数是没有共享的。
为了表明 SOLO 的通用性和高效性,作者使用了不同的 backbone 和 head 进行实验:
- backbone
- head
- loss 函数
3.3 SOLO learning
3.3.1 Label Assignment
类别预测分支: 网络需要给每个小格子预测目标类别概率。以 ( i , j ) (i,j) (i,j) 位置为例,如果该网格内落入了任何 gt mask 的中心区域,则被分为正例,否则被分为负例。中心点采样在现在的目标检测方法中是非常高效的,所以作者在mask 类别分类任务上使用了类似的方法。
给定 gt mask 的中心 ( c x , c y ) (c_x, c_y) (cx,cy),宽 w w w,高 h h h。中心区域的尺度控制因子是 ϵ : ( c x , c y , ϵ w , ϵ h ) \epsilon:(c_x, c_y, \epsilon w, \epsilon h) ϵ:(cx,cy,ϵw,ϵh)。
本文作者设定 ϵ = 0.2 \epsilon=0.2 ϵ=0.2,则每个 gt mask 平均有 3 个 正样本(positive samples)。
对每个 positive sample,都会设定一个二值分割 mask,此处共有 S 2 S^2 S2 个 grid,所有每个图像都会输出 S 2 S^2 S2 个 mask,对每个 positive sample,其对应的 binary mask 都会被标记。
注意: mask 的维度会影响 mask 预测分支,然而,作者展示了最简单的 row-major order 在本文方法都会有很好的效果。
3.3.2 Loss Function
训练的 loss function, λ = 3 \lambda=3 λ=3:
![]()
其中, L c a t e L_{cate} Lcate 是用于分类的 Focal loss, L m a s k L_{mask} Lmask 是用于 mask 预测的 loss:
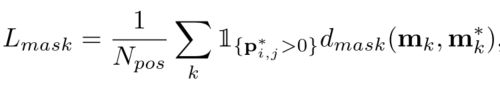
如果 grid 的索引(类别 label)是从左到右、从上到下排列的,则 i = ⌊ k / S ⌋ i=\lfloor k/S \rfloor i=⌊k/S⌋, j = k % S j=k \% S j=k%S, N p o s N_{pos} Npos 是 positive samples 的个数, p ∗ p^* p∗ 和 m ∗ m^* m∗ 分别是类别和mask。 1 1 1 是指示函数,如果 p i , j ∗ > 0 p_{i,j}^*>0 pi,j∗>0,则为1,否则为0。
d m a s k : d_{mask}: dmask: 本文中,作者对比了三种不同的 loss函数
- Binary Cross Entropy(BCE)
- Focal loss
- Dice loss
最终, Dice loss 以其高效性和稳定性赢得了作者的青睐

3.4 Inference
- 首先经过 FPN,得到 ( i , j ) (i,j) (i,j) 位置上的类别得分 p i , j p_{i,j} pi,j,和对应的 mask m k m_k mk,其中 k = i ⋅ S + j k=i \cdot S +j k=i⋅S+j。
- 使用阈值 0.1 来过滤掉低的类别得分
- 选择前 500 个得分对应的mask,并进行 NMS。
- 为了将预测的 soft mask 转化成 二值 mask,作者使用 0.5 的阈值将 soft mask 进行二值化。保留前100 个实例来进行评估。
四、实验
8GPU,SGD,batch_size:16,共 36 个epoch,初始 lr=0.01,分别在 27 和 33 个epoch处下降10倍。图像大小:短边随机采样到 640 ~ 800 pixel。
4.1 主要结果
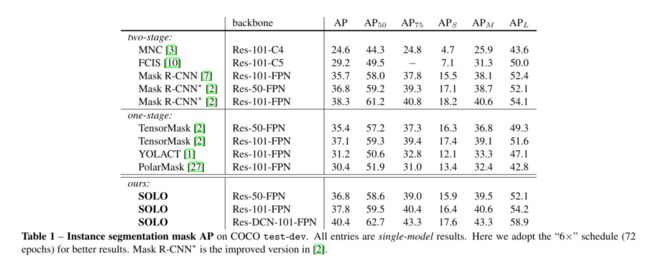
在 MS COCO test-dev上对比:如表1所示
- SOLO 和 ResNet-101 结合,得到 mask AP 37.8%
- SOLO 和 DCN-101 结合,得到 mask AP 40.4%
SOLO 输出如图8所示,在很多不同的场景都可以获得较好的效果。
4.2 How SOLO works?
S = 12 S=12 S=12 时的网络输出如图4所示,子图 ( i , j ) (i,j) (i,j) 表示由其对应的 mask 分支(经过 sigmoid)预测得到的 soft mask。
不同的实例是由不同的 mask 预测分支来响应的,通过在不同位置来分割实例,SOLO 将实例分割问题转化成了 position-aware 的分类问题。
每个 grid 仅仅会对一个实例响应,且一个实例可能会被相邻的 channel 都预测,在 inference 阶段,使用 NMS 来抑制多余的 mask。
4.3 Ablation Experiments
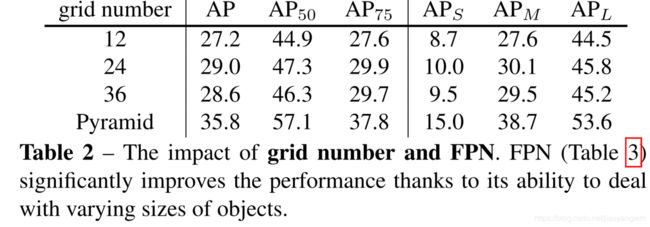
Grid number: 本文对比了不同的 grid number 带来的影响,如表2所示。
特征的生成是通过 merge ResNet(stride=8) 的 C3, C4, C5 的输出得到的。
S=12 时, SOLO 可以在 MS COCO 上得到 27.2 的 AP,当 S=24 时,提高到了 29.0 AP。

上述结果表明,单尺度的 SOLO 可以应用到目标尺寸差异不太多的场景中。
然而,单尺度的模型远远低于金字塔模型。
Multi-level Prediction: 作者使用 5 级 FPN 金字塔,来分割不同尺度的目标,如表3所示。gt mask 的尺寸被显式的用于分配它们去特定的金字塔 level。
基于上述多尺度方法,作者得到了 35.8 AP,大大的提升了效果。
CoordConv: 另外一个重要的组件是 spatially variant convolution(CoordConv)。如表4所示,标准的 conv 已经在一定程度上具有了空间可变性。当使得卷积能够访问自己的坐标时,可以提升3.6个AP。两个或更多的 CoordConv 会带来更多的提升,这说明,CoordConv 能够给预测输出带来空域变化或位置敏感性。

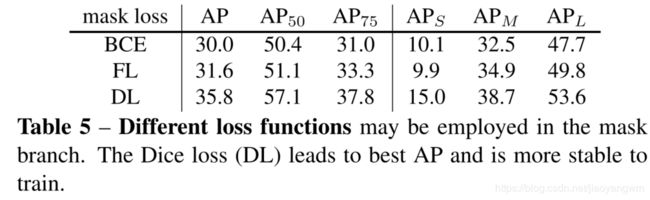
Loss function: 表5展示了不同的 loss function 给 mask 分支带来的影响,包括 BCE、FL、DL。
- BCE:对 positive samples,设置mask分支的 weight=10,pixel weight=2
- FL:mask 分支 weight=2
FL 损失更优,由于实例 mask 的大部分像素都在背景中, Focal loss 原本就是为了降低分类良好的样本的损失来缓解样本不平衡问题的。
- Dice Loss:在无需人工设定 loss 的权重超参数的情况下,得到了最好的效果。该 loss 函数将 pixels 视为一个 object,可以自动的在背景和前景像素间建立正确的平衡。
Alignment in category branch: 类别预测分支,必须将 H × W H\times W H×W 和 S × S S\times S S×S 的卷积特征进行匹配。作者对比了三个方法:
- interpolationg:直接双线性插值到需要的尺寸
- adaptive-pool:2 维 max-pool,从 H × W H\times W H×W 到 S × S S\times S S×S
- region-grid-interpolation:对每个网格,使用基于密集采样点的双线性插值,并将结果与均值进行聚合。
从结果来看,这些不同的方法并没有带来很大的性能差异,也就是说对齐的过程较为灵活。
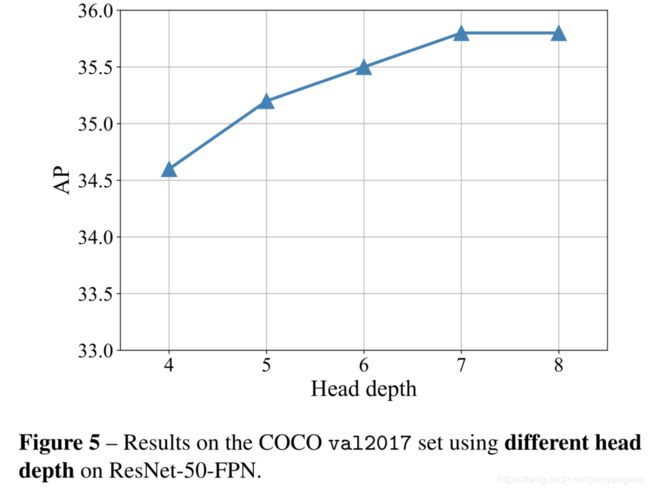
Different head depth: SOLO 中,实例分割是一个 pixel-to-pixel 的任务,作者使用 FCN 来探索 mask 的空间布局。如图5所示,作者对比了不同的 head 深度带来的影响。将 head 的深度从 4 提升到 7,获得了 1.2 的 AP 提升。当深度超过 7 时,性能趋于稳定。故本文中使用深度为 7。
为什么 SOLO 中 head 更深?
之前的工作,如 Mask R-CNN,通常在 head 使用 4 层卷积来进行 mask 的预测,在 SOLO 中,mask 是基于空间位置来调节的,所以作者将坐标附加到 head 开始的地方,mask head 必须由足够的特征表达能力来学习这种平移。对于类别分类分支,计算的开销可以胡烈,因为 S 2 < < H × W S^2 << H \times W S2<<H×W。
4.4 SOLO-512
作者还训练了小的版本,来突破实时语义分割的界限。作者使用的模型的输出具有较小的分辨率,较短的边为 512 而非 800。其他设置和 SOLO 相同。

SOLO 对于密集的、任意的实例预测任务来说,是一种通用的技术。

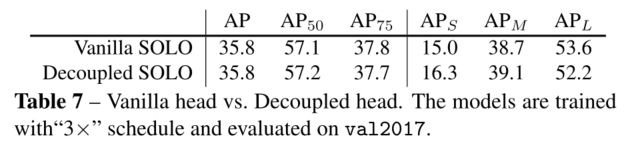
五、Decoupled SOLO
假设设定 S = 20 S=20 S=20, SOLO 的输出是 S 2 = 400 S^2=400 S2=400 个通道的 map,然而,这些预测在一般情况下是冗余的,因为目标是稀疏的。所以作者又在本节引入了 Decoupled SOLO,如图7所示。

Decoupled SOLO:
- 原始输出 tensor : M ∈ R H × W × S 2 M \in R^{H \times W \times S^2} M∈RH×W×S2
- 经过解耦之后的输出:分别对应于两个坐标的 tensor, X ∈ R H × W × S X \in R^{H \times W \times S} X∈RH×W×S 和 X ∈ Y H × W × S X \in Y^{H \times W \times S} X∈YH×W×S。
所以,输出空间从 H × W × S 2 H \times W \times S^2 H×W×S2 降到了 H × W × 2 S H \times W \times 2S H×W×2S 。
对于落到网格 ( i , j ) (i,j) (i,j) 中的目标:
- 原始SOLO 在输出 tensor M 的第 k 个通道分割其 mask, k = i ⋅ S + j k=i \cdot S + j k=i⋅S+j
- Decoupled SOLO,该对象的预测 mask 被定义为两个 channel map 的元素级别的相乘:

七、Conclusion
SOLO 是一个端到端的实例分割框架,与 mask r-cnn 相比,达到了竞争性的准确性。