基于CNN的自动化测试实践
基于CNN的自动化测试实践

ReLuQ
交叉学科就像交叉特征一样有趣
已关注
2 人赞同了该文章
写在开头:
本篇是笔者在公司的一个项目,主要与公司测试部一位经验丰富的老哥(曾在华为腾讯任职十年)合作完成,目前已经嵌入公司的专项测试流程,与OCR结合完成APP页面启动时长测试这一任务。
在上一篇中我们简单介绍了什么是卷积神经网络,那么本章就试试看做点东西出来~
这里只选取本项目的机器学习部分,更多细节和测试结果图片可以移步微信公众号:小赢技术团队 欢迎关注
UI自动化的痛
在软件测试中,自动化测试成为节省人力、验证成熟模块与功能的手段,但随着互联网产品的迭代越来越快、运营活动不断上线,测试人员会发现自动化测试维护成本往往需要投入比手工测试大得多,传统的图片识别方案OCR往往在自动化测试中以下的诟病:
1. 识别率忽高忽低:
通常OCR是通过对比两张图片的差异值来判断图片一致性从而来判断自动测试结果是否成功,但在测试中种千奇百怪的页面元素变动引起的差异值不稳定,导致测试脚本输出测试结果时会引起误报或取值不精确;
2. 外部因素干扰大:
通常OCR对比是通过全屏截屏后与目标图片对比,但全屏的图片像素包含手机通知栏诸多图标显示变化,会对图片差异值影响较大,导致对自动测试结果影响较大;
3. 运营活动是死敌:
运营活动常常会在应用界面进行弹窗,严重破坏测试界面的一致性,是自动测试的大敌,往往会导致大量测试的误报;
以上,都是传统自动化测试使用OCR判断测试结果的痛点,领悟了以后在机器学习满天飞的今天,尝试引入机器学习模型来改进优化图片识别这个关键节点的成功率与可维护性。
如何将机器学习嵌入UI测试
实现思路
APP启动时长自动化测试接入机器学习模型,主要以APP的三个页面(首页、登录、我的账户)为试点,主要分为以下3个步骤来进行:
- 采用基于浅层卷积神经网络算法的机器学习框架训练三个目标页面模型;
- 编写APP三个页面功能的自动化测速脚本各测试100次,调用机器学习模型接口,将实时截图与训练模型进行比对后,接口返回比对结果,同时也调用OCR接口进行比对,并将两者结果进行比对。
- 通过自动化测试脚本获取不同运营活动数据,观察识别成功
- 借助CI自动化测试平台,对应务场景用户量峰值时段进行自动化多次测试,获取当天不同时段性能趋势图并自动发邮件给相关人。
其中,step1中训练三个目标页面模型的具体步骤细分如下:
- 图像切分:对图像做一些列处理,是的其更适合作为数据集来进行分析
- 特征工程:将大量图片样本转化为计算机可以进行计算的矩阵或张量
- 建模:构建神经网络模型,
- 训练调参:训练模型,使其具有更好的表现效果,能够更加精准的判断页面属性
本次项目的具体流程为:
- 数据打标签并切分数据
- 输入数据并划分batch
- 确定模型架构
- 模型训练,存储,调用
图像切分
针对start,account,login三种场景,分别选定不通区域像素作为有空间特性的特征。
图片原始尺寸为1080 * 1920,使用原图片主要有两个问题:1.过多的像素点导致训练过程过大,效率慢 2.整张图片由于运营等原因,会不定时产生改变,使用严格对比可能导致超时效性误报
因此,针对不同场景特性,分别将其切分成更具有特征性的小块,并对小块进行分类。
特征工程
针对某一场景,依次读入正负样本并同时生成标签(label)矩阵,由于输入数据为png图片,属性上为4通道,而需求数据为3通道(R,G,B),使用PIL库进行转化,取R,G,B三个维度数据,之后读取所有样本并转化为(batch_size,width,height,channel)尺寸的tensor
建模
模型选取常用于图像识别分类的卷积神经网络,由于数据并不复杂,选择浅层网络即可。在模型选择上,卷积神经网络在图像识别方面具有着:1.训练效率较高,时间空间复杂度均较低;2.架构在各类图像数据集上的表现均具有较高的精准性;3.具有较成熟的开源开发环境,如TensorFlow,Caffe,Keras等对CNN的支持均十分良好。
由于本次项目数据集具有特征较为稀疏的特点,因此,选取较少层数的CNN作为主要模型而替代试验阶段选用的logistics regression,svm等机器学习模型,原因在于传统机器学习对于局部特征的敏感程度要远低于CNN而又容易受到局部小范围变化的影响。
卷积神经网络主要通过保持图片原有的空间结构,嗅探局部特征,低层次特征到高层次特征学习等方面来提高图像识别等任务的准确率。
具体神经网络架构:

我们参考了最经典的alexnet结构,因此加入了lrn层而不是使用dropout
建模代码
以下会介绍建模代码部分的工作,我们使用tensorflow来完成建模,tensorflow熟悉的朋友都知道是google出品的一款深度学习框架,基于计算图和张量进行数据处理和计算,对于其内部架构及原理笔者也了解不多,只是处于会用阶段(捂脸)
下面就是如何将设计好的模型结构转化成可用的代码:
第一层 卷积层:
- 卷积使用16个3*3滤波器,初始化采用随机正态分布抽样,padding类型选择SAME(在滑动越界时对图像边缘填充0元素)
- 之后对图像通过非线性激活函数RELU处理
- 对激活后矩阵做最大池化(max-pooling)处理,减少矩阵规模,提取局部特征
- 对池化后矩阵做侧抑制(LRN),提取反馈表现更大的区域(参考Alexnet)

第二层 卷积层:
- 卷积
- RELU激活
- LRN
- max-pooling

第三层 全连接层:
- 将前两层卷积得到的空间结构转化为以为向量,做为全连接的神经网络的输入层
- 对结果做RELU激活,输出结果相当于第一个隐藏层
- 对隐藏层做第二次全连接处理
- 对上述输出做RELU
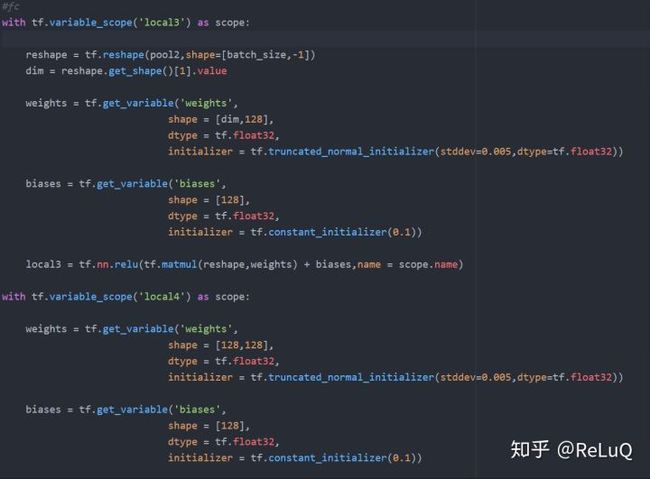
第四层 SOFTMAX层
- 对结果做SOFTMAX回归,并返回最终结果

总结
机器学习接入自动测试的过程也不是一番风顺的,过程中也不停的遇到困难解决困难,今后在实践的过程中也要不断遇到困难学习解决,才能在自动测试智能化的路上越走越远。
机器学习接入自动测试是一个新的尝试,现在在测试中仅仅利用了其在图片识别方面的功能,在将来的测试实践中,将会借力机器学习在大数据处理方面的优势在测试用例生成、测试环境部署与数据初始化等环节,更好的辅助自动化测试。
发布于 2019-03-10