《持续交付》(四)部署发布与基础架构管理
引言
本文是《持续交付》一书学习总结的第四篇。主要内容涉及部署发布和基础架构管理的实践。

部署和发布(一)
这次我们来看看软件持续交付的最后一个步骤:部署和发布。
在项目开始的时候,我们就要想好软件最终发布时要面临的问题,以此制定发布计划和策略。要考虑的问题包括但不限于:
- 确定部署需要的技术。比如基于Azure平台的应用,部署时就需要微软的Powershell脚本来实现自动化。
- 如何实现部署流水线。
- 监控应用程序的技术和策略。有了这些信息可以帮助我们掌握API等服务的实时状态。
- 与外界系统的集成。应用程序可能访问第三方的外部系统,这些在部署时需要考虑得当。
- 灾难恢复计划。一旦应用程序出现宕机等灾难情况,要有应急的计划。
- 问题修复和补丁的策略。
- 软件的升级和更新策略。
- 如何回退到某个历史版本。
- 如何对部署的环境进行冒烟测试。
除了上述技术性的关键问题外,软件的发布还需要一些商业上的考虑。比如,定价模式、软件许可(license)策略、版权信息、市场材料、用户手册和销售支持等信息。
在发布阶段,软件的第一次部署很重要。第一次部署要尽早开始,不能等到产品所有的特性都开发结束后再开始部署。一般可以挑选一系列优先级最高的用户需求加以实现,然后就可以开始部署第一个版本了。
第一次部署不一定就是生产环境,可以从一个类似生产环境的环境开始,比如staging和internal production。在部署时要思考,开发环境和生产环境的区别是什么?这个问题要涉及操作系统、软件工具和依赖、环境管理方式等方面。
软件从构建到发布可以建模为一个构件提升(promoting builds)的过程。通俗地讲,在构建阶段生成的build,要经过各个阶段测试的考验,逐渐提升至发布阶段,用于最后的部署,如下图。从中可以看到,每个菱形的区域代表一个质量门(quality gate),每一道质量门需要特定的人员(如QA)来批准通过。除了build,配置也需要有提升过程。如果配置不能跟随build提升,那么最后部署的环境可能就会缺少配置,导致部署失败。我们可以通过冒烟测试来检查配置是否正确。另外,对于微服务系统,每个服务或组件都要同时提升,尤其是不同组件有依赖关系时。
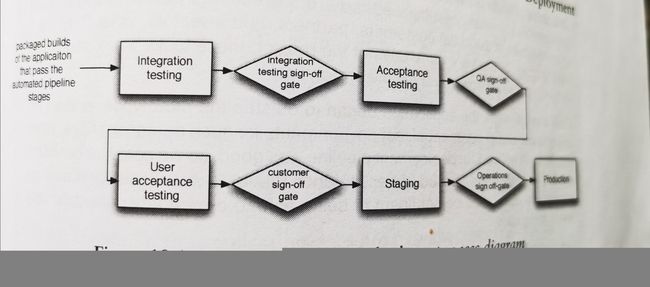
接下来我们来看发布的一些策略。
部署和发布(二)
下面我们来看一些部署和发布的具体实践。
可回滚部署(rolling back deployment):在部署前我们就要制定好计划,在部署后的环境出现问题时,如何回滚改动到正常版本。这里面有两个关键点:一是保证数据有备份,尤其是涉及到数据库的改动。二是系统的外部依赖。当回滚部署时,整个软件系统依赖的所有外部系统可能都要与之协调。一个好的习惯是,在部署前就对回滚操作进行演练,保证整个过程不出问题。
蓝-绿部署(Blue-Green Deployment):蓝绿部署的思路是维护两套生产环境,一个是蓝色环境,一个是绿色环境,同时只有一个环境是真正的生产环境。比如当前生产环境是蓝色,当我们要部署新的版本时,可以先部署到绿色环境上,我们可以进行一些冒烟测试,确保部署没有问题。再进行一些预热性的操作,让软件系统正常工作一段时间。在确保上述过程都没有问题后,我们再将生产环境从蓝色指向绿色,这个操作是很快的。如图。
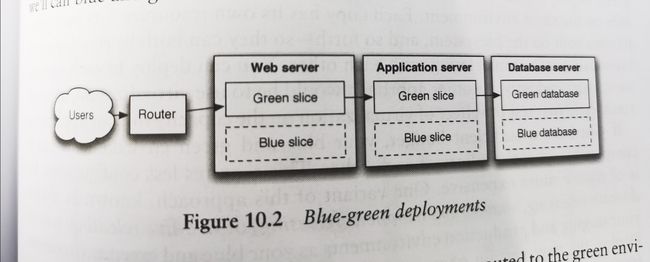
这里面有个数据同步的问题,两套环境的数据库的状态可能不一致。一种解决方案是,当我们要从蓝色切换到绿色之前,先把蓝色环境的数据库设置为只读,然后拷贝一份数据出来,导入绿色环境的数据库。再启动绿色环境,一切正常后再切换生产环境,并恢复数据库的可读可写状态。在部署流水线中关于数据管理的问题,后面有更多的分享。
金丝雀发布(canary release):有时在部署时,我们想看看用户的真实反馈,以及生产环境在采用新版本后的实时指标,但又不想影响大多数的用户,此时就可以采用金丝雀发布策略。它的思路是,将一部分用户访问的路由指向包含新版本的部署环境,经过一段时间的试用和反馈,再逐步扩大用户范围,直至100%。如图。在开始时,通常都是从一些内部开发者群体和用户开始,逐步扩展到外部的真实用户群体。在以前的煤矿工业中,为了检测矿井里有没有毒气释放,一般会放一些金丝雀进去,看看有没有中毒迹象,这就是金丝雀发布的由来。
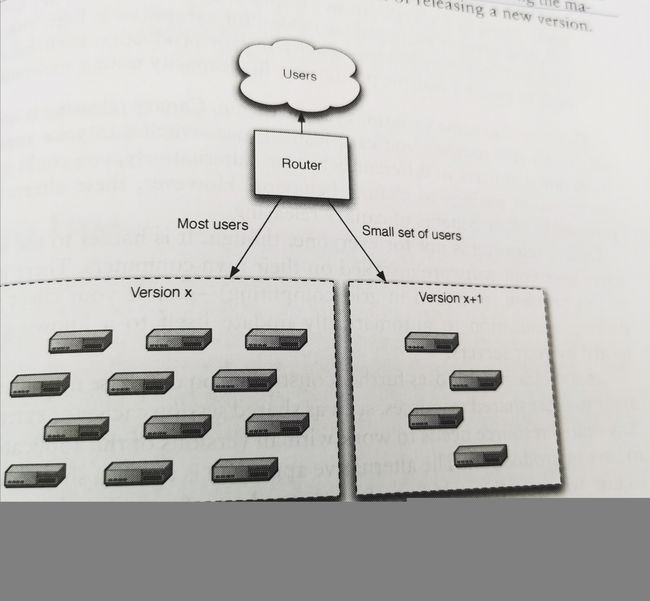
借助金丝雀发布,我们可以对新版本的产品做一些评估。比如看看新特性的用户使用率,以及一些新算法的效果,以此来辅助开发的决策。还可以检查系统的负载随着用户量逐步增大的变化趋势,避免同时有大量用户上线时,导致一些关于并发访问的严重问题。
还有一些好的实践和技巧如下:
- 对于紧急问题的修复,不能脱离部署流水线,更不能直接在生产环境上改动。脱离流水线意味着修复的改动得不到充分的测试,这可能引入新问题,而原来的问题反而没有修掉。
- 开发和运维人员在项目开始时就应该展开合作。在项目开始时,开发和运维团队就应该一起制定部署计划和发布方案,设计部署流水线,保持信息的同步。
- 对部署的每一步作日志。
- 不要删除旧的文件,而是移动到档案(archive)里。
- 为新部署设置预热阶段。新部署好的环境可能需要工作一段时间才会显现一些潜在的问题。比如,一些应用的内部缓存在一段时间后才会装满,由此导致性能问题,但是这在部署刚上线时是看不出来的。
以上就是部署和发布的一些学习收获。下面我们来具体看看部署流水线上的一些常见主题,就从基础架构(infrastructure)管理开始。
基础架构管理(一)
这次我们来看看在持续交付中关于基础架构(Infrastructure)管理的问题。所谓基础架构,通常是指软件系统运行的硬件和软件的底层环境,比如操作系统、虚拟机以及网络拓扑等等。下图展示了常见的用于部署的而服务器和配置。对于小型项目,运维人员的手工操作就可以搞定大部分用于部署的基础架构,但随着项目规模增大,手工搭建和配置环境的缺点就立刻显现。

首先,人工配置工作量极大且容易出错。如果软件系统需要一个分布式的集群,那么集群中每个结点的硬件配置和软件栈,以及结点之间的网络通信配置等,都需要手工完成,这对于大规模的项目来说是不可想象的。而且,配置过程容易出错却不易发觉。
其次,搭建和配置环境的动作没有记录。这让环境的回滚很难实现,引入风险,不利于持续交付的目标。另外,当环境出问题时,也不好定位是谁的操作引入的。
因此,良好的基础架构管理一般有以下实践。
- 正确运行的配置状态应该保存到版本控制系统中(比如Git)。这样在遇到问题时,就能迅速找到一个正确的可用的环境配置。
- 自动化环境搭建和配置。目前主流的平台提供商(比如微软的Azure云平台)都支持脚本化的环境搭建和部署。所有的操作尽量让脚本自动完成,不要手动干预。
- 设置监控(monitoring)机制。时刻关注基础架构的部署和运行状态是否正常。
下面来看看开发团队和运维团队的关系。在很多公司中,生产环境的搭建、部署和配置等操作,有专门的运维团队(Ops或者DevOps)负责。在持续交付的实践中,开发团队的目标是尽可能让新特性上线,而运维团队的目标是尽可能让生产环境保持稳定。这二者的目标有时候是冲突的。如果关系处理不好,就可能出现这样的情况,生产环境遇到问题,大家不是忙着解决问题,而是花大量时间来确定这个问题是哪个组的人引入的,以此来区分责任。为了解决这个问题,除了管理层需要协调外,还可以通过一些流程上的改进来避免人为问题的发生。比如:
- 可以当环境的配置需要改动时,通过ticket系统提交请求,通过审核后再由专业的人进行操作。
- 所有的改动都遵守相同的管理流程。比如,不能这一次配置通过自动化脚本完成,下一次就直接登录到机器上完成。
- 设置关键环境(如production)的管理权限。这一点不仅仅针对团队外部人员,也要限制运维团队内部成员。因为一旦生产环境出错,内部人员也产生会急于修正的心态,从而忽视流程,可能会引入更多问题。
- 一些关键的改动要有日志,方便日后审计。
- 在改动基础架构的配置前,需要在类生产环境(production-like,staging)上进行测试,以防止意料外的问题。
- 所有的改动都要进行版本控制。这一点之前说过了。
另外,部署和配置的脚本要具有幂等性(idempotence)。这一点要求无论环境和系统在改动前处于什么状态,也无论你部署和改动多少次,最终期望的结果始终是一致的。这样做的目的是,如果一旦环境除了问题,我们可以尽快让环境进入我们期望的状态,而不取决于环境出问题时的具体状态。
接下来我们来看看基础架构中常用的云计算(Cloud Computing)和虚拟化(Virtualization)技术实践。
基础架构管理(二)
这次我们来看看虚拟化和云计算相关的基础架构管理实践。
虚拟化的好处总体来看有:1. 降低部署时间。2. 降低风险。
具体来看有但不限于:
- 快速响应变动需求。当需要新的机器时,或者需要重新部署环境时,在虚拟机上操作,要比寻找一台新的物理机快的多。
- 标准化硬件。来自用一个物理机的虚拟机的底层硬件特点是相同的,这就控制了环境中的一些变量,便于分析问题。
- 容易维护基线(baseline)。维护环境的基线有几个好处。首先,很多系统配置和软件依赖可以通过快照(snapshot)的方式直接拷贝和恢复,而不需要重新安装。目前广泛使用的容器(container)技术也是类似的虚拟化思想。第二,当环境遇到问题时,能快速回退到可用的稳定状态。
- 快速并行测试。当测试的case很多时,可以多起几台虚拟机进行并行测试,提高效率。
为了方便,我们通常会依据正常运行的虚拟机创建一些模板,用于后续各类开发机或服务器的创建和配置,如图所示。对于部署流水线来说,虚拟机模板的好处还体现在,在每一个阶段(开发、验收测试、部署、回退部署),可以采用完全相同的环境配置完成,防止由于环境的变化引入新的问题。
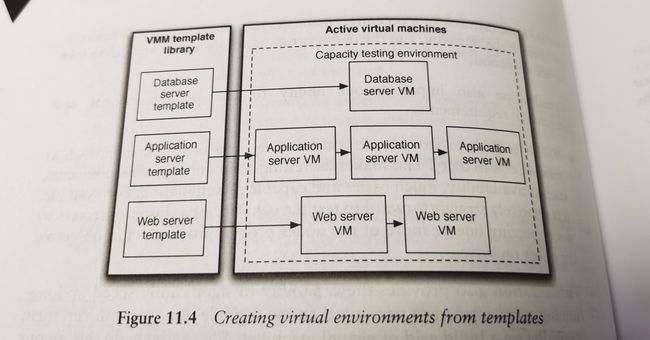
云计算的概念大家应该都很熟悉了,现在也是很热门的话题。各大产业巨头公司(比如微软、亚马逊、Google等)在上面的投入也不少。从资源的角度说,云计算就是将各种计算资源集中起来提供给用户,用户可以根据自己需求增加和减少资源的使用,并且通常按实际的使用量收费。
云服务提供商通常以三种方式提供服务:1. 基础架构服务(比如亚马逊的AWS),常见的服务有虚拟机、存储、网络负载均衡设备等。2. 平台服务(比如微软的Azure),常见的服务有数据库、开发平台和微服务架构等。3. 软件服务,比如Gmail、WordPress等。不过现在的主流厂商三种服务都会提供。图2为微软Azure提供的部分服务种类。
在持续交付中,很多构建和部署工作都可以交给云计算服务完成。以微软的Azure为例,一个Web应用程序的前端程序可以部署在Azure平台的IIS服务器上,后端的API服务可以采用微服务架构Service Fabric部署在Azure提供的集群上,数据库可以使用Azure提供的Tables或者CosmosDB服务。以上所有服务的部署都可以通过微软的powershell脚本,以自动化的方式完成。这里面的很多非功能性的问题,比如安全性、负载均衡、高可用性以及扩展性,都由Azure平台自动处理。
在实际项目的实践中,经常采用云计算(Cloud-based)与本地(On-prem)部署结合的方式,这主要考虑几个方面。一是成本问题,不是每个企业都能负担的起长期的、高额的计算费用。二是数据安全考虑,很多企业更情愿把关键数据放在自己公司的服务器上。三是技术的依赖性。很多产品的技术栈是与特定平台或系统相关的,这样某些云计算平台就不合适。
下面我们来看看持续交付中的数据管理实践。