多进程编程之进程间通信-管道和消息队列
1.进程间通信
Linux作为一种新兴的操作系统,几乎支持所有的Unix下常用的进程间通信方法:管道、消息队列、共享内存、信号量、套接口等等。
2.管道
管道是进程间通信中最古老的方式,它包括无名管道(或者匿名管道)和有名管道两种,前者用于父进程和子进程间的通信,后者用于运行于同一台机器上的任意两个进程间的通信。
2.1无名管道
2.1.1无名管道pipe
无名管道由pipe()函数创建:
#include
int pipe(int filedis[2]); 参数filedis返回两个文件描述符:filedes[0]为读而打开,filedes[1]为写而打开。filedes[1]的输出是filedes[0]的输入。下面的例子示范了如何在父进程和子进程间实现通信。
跨越fork调用的管道:
例子代码:
#include 运行结果:
基于管道的进程间通信:
int main()
{
int mycount=0;
ifstream m_InStream("subdata.txt");//读取的任务列表
int data_processed;
int file_pipes[3][2];
string some_data;
pid_t fork_result[3];
for (int i = 0; i < 3; ++i)
{
if (pipe(file_pipes[i]) == 0)
{
fork_result[i] = fork();
if (fork_result[i] == 0)
{
close(file_pipes[i][1]);
char buf[1024] = {0};
while(true)
{
int readsize = read(file_pipes[i][0], buf, sizeof(buf)+1);
buf[readsize]='\0';//注意这里,可以存在字符之后有其他字符,可以尝试下,注释掉该语句的效果!!
// printf("%X,%X,%X\n",buf[readsize],buf[readsize+1],buf[readsize+2]);
printf("Read %d byte,data=%s\n",readsize, buf);
std::cout << flush;// fflush(stdout);
if (strncmp(buf, "exit", 4) == 0)
{
break;
}
}
exit(0);
}
else if(fork_result[i] == -1)
{
fprintf(stderr, "Fork failure");
exit(EXIT_FAILURE);
}
}
}
string oneline;
int count=0;
while(getline(m_InStream, oneline,'\n'))
{
some_data = oneline;
char bufs[128] = {0};
strncpy(bufs,some_data.c_str(),some_data.size());
data_processed = write(file_pipes[count][1], bufs, strlen(bufs));
printf("Wrote %d bytes,data=%s\n", data_processed,bufs);
count++;
if(count>=3)
{
count = count -3;
}
sleep(1);
}
for(int i=0; i<3; ++i)
{
char bufs[128] = {0};
snprintf(bufs, sizeof(bufs), "exit");
write(file_pipes[i][1], bufs, strlen(bufs));
sleep(1);
}
int status =0;
int mpid =0;
for(int i=0;i<3;i++)
{
mpid = wait(&status);
printf("pid[%d] is exit with status[%d]\n",mpid,status);
}
return 0;
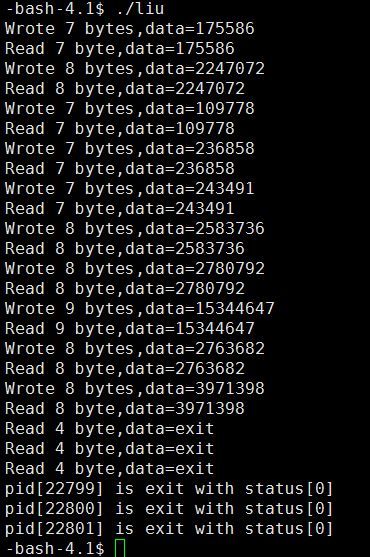
}运行结果如下:
2.1.2 popen和pclose
如果不用上述底层的pipe函数的话,可以采用较高级的popen和pclose来创建和关闭管道。
函数原型:
FILE *popen(const char * command ,const char *mode)
int pclose(FILE * stream)
参数commend是shell命令。
参数mode是一个字符指针,r或w,分别表示popen函数的返回值是一个读打开文件指针,还是写打开文件指针,失败时返回值为NULL,并设置出错变量errno。popen()会调用fork()产生子进程,然后从子进程中调用/bin/sh -c来执行参数command的指令。参数type可使用“r”代表读取,调用程序利用popen函数返回的FILE*文件流指针,就可以通过常用的stdio库函数(如fread)来读取被调用程序的输出;“w”代表写入,调用程序可以用fwrite调用向被调用程序发送数据,而被调用程序可以在自己的标准输入流上读取这些数据。向管道写信息还是读信息取决该参数。
1)读取外部程序的输出(r模式):
/*popen函数
(1)创建管道
(2)调用fork函数创建子进程
(3)执行exec函数调用,调用/bin/sh -c 执行commend中的命令字符串,返回标准I/O 文件指针
*/
#include运行结果:
root:x:0:0:root:/root:/bin/bash
2)将输出送往popen(w模式):
#include 运行结果:

该程序使用带有参数“w”的popen启动od -c命令,即可实现向该命令发送数据。通过fwrite方式给od -c命令发送了一个字符串,该命令收到该字符串并进行处理,最后把处理结果打印到自己的标准输出上。
在命令行上的等效命令:
echo “Once upon a time, there was…”| od -c
3)传递更多数据:
上面展示的都是通过一次fread和fwrite来收发数据,当需要以块方式传递不清楚输出数据长度的情况呢?此时可以通过多个fread和fwrite将数据氛围多个部分进行处理。
例子如下:
//liu.cpp
#include 该程序会连续从文件流中读取数据,直到没有更多的数据。注意,尽管ps命令的执行需要一些时间,Linux会安排进程调度,从而让两个程序在可以运行时继续运行。如果读进程liu没有数据可读,它会被挂起,直到有数据到达。如果写进程ps产生的输出超过可用缓冲区的长度,它就会被挂起,直到读进程读取其中的一些数据。
运行结果如下图:

2.2 有名管道(也叫做命名管道)
基于有名管道,我们可以实现不相关进程之间的数据交换,而不必有一个共同的祖先进程。有名管道是基于FIFO文件来完成的,有名管道是一种特殊类型的文件,它在系统文件中以文件名的形式存在,行为和上述介绍的无名管道pipe类似。
2.2.1 创建有名管道
有名管道可由两种方式创建:命令行方式mknod系统调用和函数mkfifo。下面的两种途径都在当前目录下生成了一个名为myfifo的有名管道:
方式一:mkfifo(“my_fifo”,”rw”);
方式二:mknod my_fifo p ,my_fifo 是指文件名
在程序中可以通过以下两个不同的函数进行调用:
#include
#include
int mkfifo(const char *pathname, mode_t mode);
int mknod(const char *pathname, mode_t mode | S_FIFO, (dev_t)0); 生成了有名管道后,就可以使用一般的文件I/O函数如open、close、read、write等来对它进行操作。
有名管道创建示例代码:
/*创建有名管道*/
#include 2.2.2 访问FIFO文件
与通过pipe调用创建管道不同,FIFO是以命名文件的形式存在,而不是打开的文件描述符,所以在对它进行读写操作之前必须先打开它。FIFO也用open和close函数进行打开和关闭。传递给open函数的是FIFO的路径名,而不是一个一般下的文件。
下面即是一个简单的例子,假设我们已经创建了一个名为my_fifo的有名管道。
1)使用open打开FIFO文件
#include 打开FIFO文件和普通文件的区别有两点:
(1)是不能以O_RDWR模式打开FIFO文件进行读写操作。这样做的行为是未定义的。之所以这样限制,是因为我们通常使用FIFO只是为了单向传递数据,所以没有必要使用这个模式。如果一个管道以读/写方式打开,进程就会从这个管道读回它自己的输出。
如果确实需要在程序之间双向传递数据,最好使用一对FIFO或管道,一个方向使用一个,或者采用先关闭再重新打开FIFO的方法来明确地改变数据流的方向。
(2)是对标志位的O_NONBLOCK选项的用法。
使用这个选项不仅改变open调用的处理方式,还会改变对这次open调用返回的文件描述符进行的读写请求的处理方式。
O_RDONLY、O_WRONLY和O_NONBLOCK标志共有四种合法的组合方式:
flags=O_RDONLY:open将会调用阻塞,除非有另外一个进程以写的方式打开同一个FIFO,否则一直等待,不会返回。
flags=O_RDONLY|O_NONBLOCK:即使此时没有其他进程以写的方式打开FIFO,此时open也会成功并立即返回,此时FIFO被读打开,而不会返回错误。
flags=O_WRONLY:open将会调用阻塞,除非有另外一个进程以读的方式打开同一个FIFO,否则一直等待。
flags=O_WRONLY|O_NONBLOCK:该函数的调用总是立即返回,但如果此时没有其他进程以读的方式打开,open调用将返回-1,并且此时FIFO没有被打开。如果缺少有一个进程以读方式打开FIFO文件,那么我们就可以通过它返回的文件描述符对这个FIFO文件进行写操作。
我们可以通过传递不同参数来观察FIFO的不同行为。
2)不带O_NONBLOCK标志的O_RDONLY和O_WRONLY
代码如下:
注意,open函数返回的文件描述符一定是最小的未用的描述符数字。
// Let's start with the header files, a #define and the check that the correct number
// of command-line arguments have been supplied.
#include \n" , *argv);
exit(EXIT_FAILURE);
}
// we now set the value of open_mode from those arguments.
for(i = 1; i < argc; i++) {
if (strncmp(*++argv, "O_RDONLY", 8) == 0)
open_mode |= O_RDONLY;
if (strncmp(*argv, "O_WRONLY", 8) == 0)
open_mode |= O_WRONLY;
if (strncmp(*argv, "O_NONBLOCK", 10) == 0)
open_mode |= O_NONBLOCK;
}
// We now check whether the FIFO exists and create it if necessary.
// Then the FIFO is opened and output given to that effect while the program
// catches forty winks. Last of all, the FIFO is closed.
//用access检查FIFO文件是否存在,如果不存在则进行创建
if (access(FIFO_NAME, F_OK) == -1) {
res = mkfifo(FIFO_NAME, 0777);
if (res != 0) {
fprintf(stderr, "Could not create fifo %s\n", FIFO_NAME);
exit(EXIT_FAILURE);
}
}
printf("Process %d opening FIFO\n", getpid());
res = open(FIFO_NAME, open_mode);
printf("Process %d result %d\n", getpid(), res);
sleep(5);
if (res != -1) (void)close(res);
printf("Process %d finished\n", getpid());
exit(EXIT_SUCCESS);
}
运行结果(将读取程序放在后台执行):
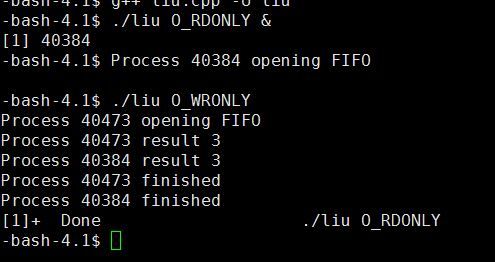
上述有名管道先启动了读进程,并在open调用中等待,当第二个进程打开FIFO文件时,两个程序继续运行。注意,读进程和写进程在open调用处取得同步。
3)带O_NONBLOCK标志的O_RDONLY和不带该标志的O_WRONLY运行结果
读进程执行open调用并立刻继续执行(所以输出了result 3的结果),即使此时没有写进程的存在。随后,写进程开始执行,它也在执行open调用后立刻继续执行,但是这次是因为FIFO已经被读进程打开。
运行结果如下图所示:
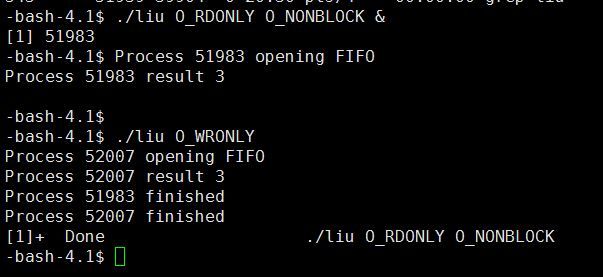
如果./liu O_RDONLY O_NONBLOCK &运行之后,没有立刻运行./liu O_WRONLY,则51983的进程可能直接接着输出对应的finished,主要看下一个进程运行的时间是否在sleep了5秒之内。
4)对FIFO进行读写操作:
使用O_NONBLOCK模式会影响的对FIFO的read和write调用。
对一个空的、阻塞的FIFO(即没有用O_NONBLOCK标志打开)的read调用将等待,直到有数据可以读取时才继续执行。与此相反,对一个空的、非阻塞的FIFO的read调用将立刻返回0字节。
对一个满的、阻塞的FIFO的write调用将等待,直到数据可以被写入时才继续执行。如果非阻塞的FIFO不能接收所有写入的数据,它将按下面的规则执行:
(1)如果请求写入的数据长度小于等于PIPE_BUF字节,调用失败,数据不能写入。
(2)如果请求写入的数据长度大于PIPE_BUF字节,将写入部分数据,返回实际写入的字节数,返回值也可能是0。
FIFO的长度是需要考虑的一个很重要的因素。系统对任一时刻在一个FIFO中可以存在的数据长度是有限制的,它由#define PIPE_BUF语句定义,通常可以在头文件limits.h中找到它。在linux和许多其他类UNIX系统中,它的值通常是4096字节,但在某些系统中它可能会小到512字节。系统规定:在一个以O_WRONLY方式(即阻塞方式)打开的FIFO中,如果写入的数据小于等于PIPE_BUF,那么或者写入全部字节,或者一个字节都不写入。
虽然,对只有一个FIFO写进程和一个FIFO读进程的简单情况来说,这个限制并不是非常重要的,但只使用一个FIFO并允许多个不同的程序向一个FIFO**读进程发送请求的情况是很就常见的。如果几个不同的程序尝试同时向FIFO写数据,能否保证来自不同程序的数据库不相互交错就非常关键了。也就是说,每个写操作**都必须是”原子化”的。怎样才能做到这一点呢?
如果能保证所有的写请求是发往一个阻塞的FIFO的,并且每个请求的数据长度小于等于PIPE_BUF字节,系统就可以确定数据块不会交错在一起。通常将每次通过FIFO传递的数据长度限制为PIPE_BUF字节是个好办法,除非只使用一个写进程和读进程.
使用FIFO实现进程间通信例子:
生产者程序:
//liu.cpp
#include 第二个程序是消费者程序,它从FIFO读取数据并丢弃它们。在运行这两个程序的同时,用time命令对读进程进行计时。
消费者程序:
//liu2.cpp
#include 运行结果如下所示:

两个程序使用的都是阻塞模式的FIFO,首先启动liu程序(写进程/生产者),它将阻塞以等待读进程打开这个FIFO。liu2(消费者)启动以后,写进程解除阻塞并开始向管道写数据。同时,读进程也开始从管道中读取数据。
linux会安排好这两个进程之间的调度,使它们在可以运行的时候运行,在不能运行的时候阻塞。因此,写进程将在管道满时阻塞,读进程将在管道空时阻塞。
time命令的输出显示,读进程只运行了不到0.01秒的时间,却读取了10MB的数据,这说明管道(至少在现在Linux系统中的实现)在程序之间传递数据是很有效率的。
3 消息队列
消息队列就是一个消息的链表,可以把消息看作一个记录,具有特定的格式以及特定的优先级。一个有写权限的进程按照一定的规则对消息队列进行信息添加,对消息队列有读权限的进程则可以从消息队列中读走消息,从而实现进程间的通信。。
代码版本1:
涉及函数:
1)创建新消息队列或者取得已经存在的消息队列
int msgget(key_t key, int msgflg);
参数:
key:可以认为是一个端口号,是用来命名某个特定的消息队列,进行消息队列标识。
msgflg:
IPC_CREAT值,若没有该队列,则创建一个并返回新标识符;若已存在,则返回原标识符。
IPC_EXCL值,若没有该队列,则返回-1;若已存在,则返回0。
2)向队列读/写消息
原型:
int msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
参数:
msqid:消息队列的标识码
msgp:指向消息缓冲区的指针,此位置用来暂时存储发送和接收的消息,是一个用户可定义的通用结构,形态如下:
struct msgstru
{ long mtype; /* 消息类型,必须 > 0 */
char mtext[1024]; /* 消息文本 */
};msgsz:消息的大小。
msgtyp:从消息队列内读取的消息形态。如果值为零,则表示消息队列中的所有消息都会被读取。
msgflg:用以控制当队列中没有对应类型的消息可以接收时的处理逻辑。对于msgsnd函数,msgflg控制着当前消息队列满或消息队列到达系统范围的限制时将要发生的事情。如果msgflg设置为IPC_NOWAIT,则在msgsnd()执行时若是消息队列已满,则msgsnd()将不会阻塞,不会发送信息,立即返回-1。如果执行的是msgrcv(),则在消息队列呈空时,不做等待马上返回-1,并设定错误码为ENOMSG。当msgflg为0时,msgsnd()及msgrcv()在队列呈满或呈空的情形时,采取阻塞等待的处理模式。此时对于发送进程而已发送进程将挂起以等待队列中腾出可用的空间;对于接收进程而言,该进程将会挂起以等待一条相应类型的信息到达。
3)设置消息队列属性
原型:int msgctl ( int msgqid, int cmd, struct msqid_ds *buf );
参数:msgctl 系统调用对 msgqid 标识的消息队列执行 cmd 操作,系统定义了 3 种 cmd 操作: IPC_STAT , IPC_SET , IPC_RMID
IPC_STAT : 该命令用来获取消息队列对应的 msqid_ds 数据结构,并将其保存到 buf 指定的地址空间。
IPC_SET : 该命令用来设置消息队列的属性,要设置的属性存储在buf中。
IPC_RMID : 从内核中删除 msqid 标识的消息队列。
receive代码:
/*receive.cpp */
#include
#include
msgs.msgtext[len] = '\0';
// std::cout<<"pid="<
if(ret_value == -1)
{
fprintf(stderr, "msgrcv failed with error: %d\n", errno);//消息队列中的信息被取完??
exit(EXIT_FAILURE);//消息队列为空的时候,就跳出。也可以设计成,消息队列为空时,不跳出,而是等待。
}
else
{
printf("pid=%d,data=%s\n",getpid(),msgs.msgtext);
}
if (strncmp(msgs.msgtext, "end", 3) == 0)
{
exit(EXIT_SUCCESS);//换成break的效果呢???是不一样的啊
}
//因为在send的时候,只send了一个end,当该标志信息被读取之后,其他的进程自然是读取不到信息的,
}
return;
}
int main()
{
int i,cpid;
/* create 5 child process */
for (i=0;iif (cpid < 0)
printf("fork failed\n");
else if (cpid ==0) /*child process*/
childproc();
}
int status =0;
int mpid =0;
// std::cout<<"father pid="<
for(int i=0;iprintf ("pid[%d] is exit with status[%d]\n",mpid,status);
}
return 1;
}
send代码:
/*send.c*/
#include ","<std::endl;
ret_value = msgsnd(msqid,&msgs,sizeof(struct msgstru),0);//消息队列标识符,准备发现信息的指针,信息的长度,控制标志位
sleep(1);
if ( ret_value < 0 ) {
printf("msgsnd() write msg failed,errno=%d[%s]\n",errno,strerror(errno));
exit(-1);
}
}
msgctl(msqid,IPC_RMID,0); //删除消息队列
//如果这行代码注释掉的话,则receive进程不会在接收一次send发出的任务之后,就全部子进程全部退出,而是send发送一次(即启动一次send程序)退出一个进程,这里启动了5个进程,所以,需要启动5次send程序,receive程序才会退出(每次退出一个进程)。
} 运行结果如下:
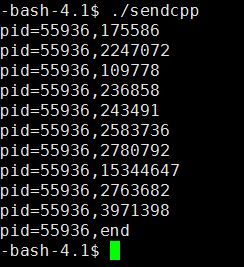
send的结果:
receive的结果:
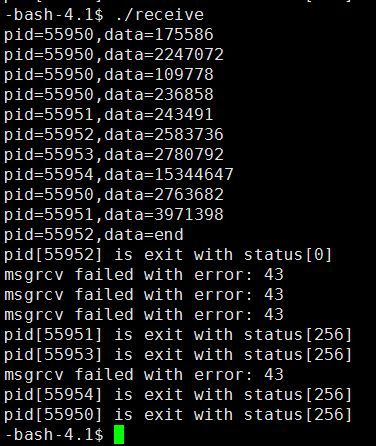
对于receive之后的结果,由于在getline的时候,在最后一行之后,send程序中往消息队列中写入的是一个end字符,而在receive方,只有其中一个进程获取到end字符,然后,正常退出该进程,而其他的进程,则是由于消息队列中信息为空,获取消息队列失败而退出的。所以,在结果图中可以看到有4个进程的消息队列获取结果失败,43提示符,从而退出进程,256的提示符。
查看消息队列的命令行:
查看全部ipc对象信息:
#ipcs -a
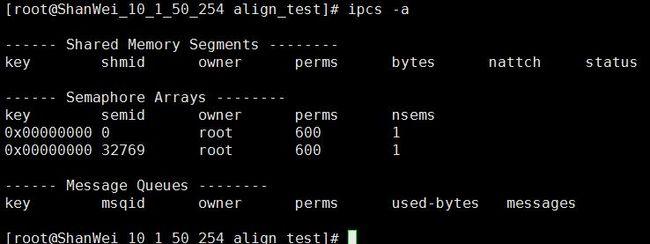
查看消息队列信息
#ipcs -q
查看共享内存信息
#ipcs -m
查看信号量信息
#ipcs -s
注意,由于设置的消息队列的最大占用byte是有限制的,查看命令如下:
# ipcs -l

从上面的结果我们可以看出消息队列中,最多可以容纳65536 bytes。超过的话,消息是无法添加到指定的队列的。
删除IPC对象的ipcrm
ipcrm -[smq] ID 或者ipcrm -[SMQ] Key
-q -Q删除消息队列信息 例如ipcrm -q 98307
-m -M删除共享内存信息
-s -S删除信号量信息
如果把两个程序合并到一起,写成一个程序呢?
至于共享内存,信号量和套接字在下文再继续介绍。