Spark源码分析之调度框架详解
文章目录
- 原理概述
- 源码分析
- Job提交
- Stage划分
- Task提交
- Executor端运行Task
Spark的调度框架分为资源调度和任务调度。Spark的资源调度是基于Yarn实现的,包含Driver和Executor资源的申请等,详细过程见博文 Spark源码分析之AM端运行流程(Driver) 和 Spark源码分析之CoarseGrainedExecutorBackend运行流程(Executor);本文主要讲述Spark任务调度框架的原理和源码分析。
原理概述
由于 Spark Scheduler内部原理剖析 中的Spark任务调度总览章节感觉已经讲解的很清楚了,因此原理部分我们直接摘抄引用如下。
当Driver起来后,Driver则会根据用户程序逻辑准备任务,并根据Executor资源情况逐步分发任务。在详细阐述任务调度前,首先说明下Spark里的几个概念。一个Spark应用程序包括Job、Stage以及Task三个概念:
- Job是以Action方法为界,遇到一个Action方法则触发一个Job;
- Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
- Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task;
Spark的任务调度总体来说分两路进行,一路是Stage级的调度,一路是Task级的调度,总体调度流程如下图所示。
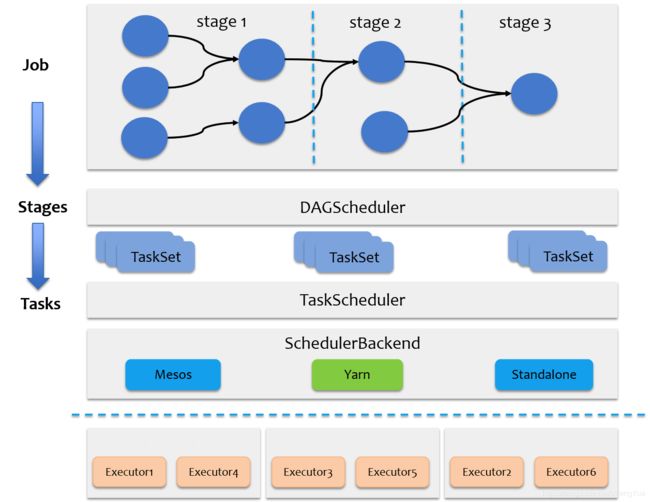
Spark RDD通过其Transactions操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。DAGScheduler负责Stage级的调度,主要是将DAG切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。有了上述感性的认识后,下面这张图描述了Spark-On-Yarn模式下在任务调度期间,ApplicationMaster、Driver以及Executor内部模块的交互过程。

Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver。SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。
源码分析
首先我们先看任务调度的整体流程图(Spark-On-Yarn模式),如下:
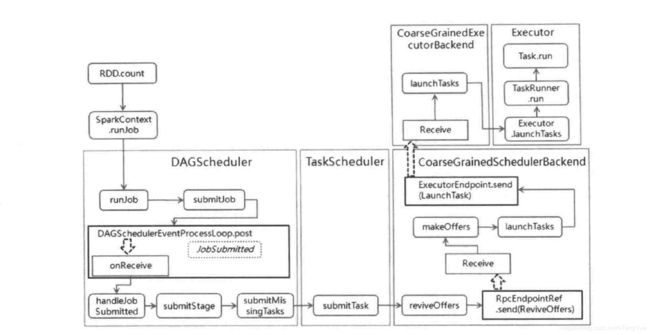
Job提交
下面我们逐步进行源码分析(源码版本为Spark2.4.3):
从上面我们知道Job的执行是由Action算子触发的。我们以rdd.count()为例看启动Job过程:
SparkContext#runJob()函数,重点分析SparkContext#runJob()函数,首先我们看其的四个参数分别为:
- rdd: RDD[T]:提交Job的rdd。
- func: (TaskContext, Iterator[T]) => U:在rdd的每个分区上运行的函数(运行在Executor端)。
- partitions: Seq[Int]:rdd的分区数组(分区个数如何确定?见 Spark源码分析之分区(Partition))
- resultHandler: (Int, U) => Unit):在rdd的每个分区运行完成后在Driver端的回调函数(运行在Driver端)。
action算子往往是Job的最后一步,和transformation算子类似也会先在Executor的Task任务中执行分区函数func,但不同的是当分区函数func执行完成后会把执行结果返回给Driver端并在回调函数resultHandler进行最终的结果处理(此步是在DAGScheduler#handleTaskCompletion()函数中调用监听函数job.listener.taskSucceeded(rt.outputId, event.result) -> JobWaiter#taskSucceeded(),最终完成调用resultHandler回调函数)。 由此结合上面截图的源码可知count算子在Executor端的Task任务调用func函数(Utils.getIteratorSize)累加分区数据个数,然后在Task执行完成后把累加的分区数据个数值返回Driver端执行resultHandler函数((index, res) => results(index) = res)放置在数组results中,最后对results数组存储数值进行sum获得最终统计的元素个数值。
注:在计算大数据量的时,使用某些action算子(例如:collect)容易引起OOM,这是由于这些算子传入SparkContext#runJob()函数的第二个参数func的实现逻辑返回的数据量过大,最终返回Driver端的多个分区的数据全部加载在内存中导致其OOM。因此,在计算的数据量较大的时候应慎用这些大量(甚至全量)返回分区数据给Driver的action算子。
我们继续往下分析,开始进入DAGScheduler的调度…
从上面代码可以看出,DAGScheduler的任务提交流程就是封装构建JobWaiter监听对象,JobWaiter主要作用就是异步监听任务的完成情况(在任务完成后会回调该监听对象),如果成功则在JobWaiter#taskSucceeded()中处理resultHandler回调函数,失败则捕获抛出异常。然后就可以通过构建JobSubmitted消息异步提交给DAGScheduler#eventProcessLoop等待事件驱动模型的处理。
DAGScheduler的事件驱动模型也是一个典型的生产者-消费者模型,通过事件阻塞队列缓存住各种事件,然后通过事件分发器里的常驻线程不断的从事件队列里取事件并将该事件交给相应的事件处理handler进行处理。事件驱动模型是在DAGScheduler初始化时构建启动的,如下图:
根据上面事件处理函数可知DAGScheduler#submitJob()提交的JobSubmitted消息事件是由DAGScheduler#handleJobSubmitted()响应处理,如下图:
一个Job可能被划分为多个Stage,各个Stage之间存在着依赖关系,下游的Stage依赖于上游的Stage,Stage划分过程是从最后一个Stage开始往前执行的,最后一个Stage的类型是ResultStage,非最后一个Stage的类型都是ShuffleMapStage。
ResultStage可以使用指定的函数对RDD中的分区进行计算并得到最终结果。ResultStage是最后执行的Stage,此阶段主要进行作业的收尾工作(例如:对各个分区的数据收集、打印到控制台或写入HDFS)
Stage划分
下面我们首先分析finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)看如何划分Stage呢?
首先看上图右侧的DAGScheduler#getShuffleDependencies()函数是对于给定的RDD获得所有的直接父shuffle依赖,其是整个Stage划分的核心函数,在生成Stage父子依赖时候多次调用,源码分析见代码。 分析上面截图可以看出创建ResultStage过程是在DAGScheduler#createResultStage()函数中首先调用DAGScheduler#getOrCreateParentStages()函数中,其首先会调用DAGScheduler#getShuffleDependencies()获得finalRDD的所有直接父shuffle依赖,然后根据获得的依赖依次调用DAGScheduler#getOrCreateShuffleMapStage()函数生成并返回直接父Stage,在调用DAGScheduler#getOrCreateShuffleMapStage()函数也会同时生成祖先Stage,并把所有Stage添加到stageIdToStage缓存,这样我们就完成了DAG中Stage的stage的拆分。我们继续分析DAGScheduler#getOrCreateShuffleMapStage()如下图:
如上图,DAGScheduler#getOrCreateShuffleMapStage()函数首先会调用DAGScheduler#getMissingAncestorShuffleDependencies()函数获得所有祖先shuffle依赖,并依次调用DAGScheduler#createShuffleMapStage()创建所有的ShuffleMapStage,此过程会把所有创建的ShuffleMapStage放在stageIdToStage缓存中,最后把finalRDD的直接父ShuffleMapStage返回供上游DAGScheduler#createResultStage()函数创建ResultStage。最后我们看DAGScheduler#createShuffleMapStage()的代码实现,如下图:
至此,DAG中Stage的划分源码就分析完成。下面给出一个示例可以参照理解Stage划分代码:
val conf = new SparkConf().setMaster("local[*]").setAppName("test")
val sc = new SparkContext(conf)
val fileInt = sc.textFile("/data/int.txt").map{ x => val xi = x.toInt; (xi,xi*xi)}
val spInt = sc.parallelize{ (0 until 1000).map{ x => (x,x * x+1) }}
val joinRes = fileInt.join(spInt)
val smRes = joinRes.mapPartitions{ iter => iter.map{ case (k,(v1,v2)) => (k, v1+v2) }}
val filterRes = smRes.filter{ case (k,v) => v % 10 == 0 }
val cntRes = filterRes.count()
sc.stop()

Task提交
下面我们回到DAGScheduler#handleJobSubmitted()函数看如何通过submitStage(finalStage)提交任务?
分析见上图代码注释,在DAGScheduler#submitStage()函数中首先判断当前Stage的父Stage是否完成,如果有未完成的,则递归的提交父Stage。这里提交的是最遥远的父Stage,后续的Stage又是什么时间提交的呢?答:在父Stage完成后会在TaskSetManager中向DagScheduler发送任务完成CompletionEvent事件,然后在DagScheduler#handleTaskCompletion()函数调用DagScheduler#submitWaitingChildStages()函数提交子Stage,从完成父子Stage的顺序调用,如下图:
我们回到提交stage任务的函数是DAGScheduler#submitMissingTasks(),继续分析
如上图分析过程见代码注释,DAGScheduler#submitMissingTasks()是Stage划分Task的核心函数,主要是根据Stage类型创建对应的分区任务(ShuffleMapStage -> ShuffleMapTask 或 ResultStage -> ResultTask),此过程会把运行分区任务的信息序列化并进行广播给Executor,然后把待计算的分区任务封装成TaskSet后提交给TaskScheduler进行任务分发调度。
到这里DAGScheduler就完成了Stage划分和Task生成。下面我们继续分析TaskScheduler的源码,Spark-On-Yarn实现类是YarnScheduler,大部分的实现代码在其父类TaskSchedulerImpl,接上面流程我们继续分析TaskSchedulerImpl#submitTasks()函数:

分析见上图代码注释,TaskSetManager负责在具体TaskSet的内部调度任务,包含负责追踪每一个task,如果task失败的话,会负责重试task,直到超过重试的次数限制,同时为这个TaskSet处理本地化调度机制;TaskScheduler负责与SchedulerBackend交互,并将资源提供给TaskSetManager供其作为本地化调度任务的依据。 这段代码的大致过程为TaskScheduler将TaskSet封装为TaskSetManager,存入待处理任务池(Pool)中,发送DriverEndpoint唤起消费(ReviveOffers)指令。具体过程为首先创建TaskSetManager,把它添加到调度器的Pool中(目前有两种调度器实现:FIFOSchedulableBuilder(默认)和FairSchedulableBuilder),然后调用backend.reviveOffers()发送指令,在Spark-On-Yarn模式下,backend的实现类是YarnSchedulerBackend,大部分代码实现在其父类CoarseGrainedSchedulerBackend中,发送指令实际就是调用CoarseGrainedSchedulerBackend#reviveOffers()函数,下面我们该指令的消息发送和响应过程,如下图:
如上图最终消息在响应函数CoarseGrainedSchedulerBackend#makeOffers(),该函数采用加锁方式,保证在调度分配资源期间,不会Executor被释放,该方法主要做以下操作:
1、获取当前全部可用的Executor封装为workOffers。
2、调用TaskSchedulerImpl对封装的workOffers分配任务,获得可发送Executor端的taskDescs对象。
3、调用launchTasks依次向Executor发送消息启动Task。
另外从这里可以看出,DriverEndpoint在启动时候也会后台启动一个任务,定时(默认1s)向自身发送ReviveOffers指令拉取待执行任务进行分配Executor,这样就能够保证,一旦有新的Executor资源(例如:新增Executor或任务执行完成释放Executor资源)就能继续分配任务。代码如下图:
我们首先分析上面第2步,看scheduler.resourceOffers(workOffers)如何对workOffers分配任务的,具体代码在TaskSchedulerImpl#resourceOffers()函数中,如下图:
重点关注上图的截图部分, 采用双层循环的方式,外层按本地化级别优先级遍历,内部调用循环调用TaskSchedulerImpl#resourceOfferSingleTaskSet()函数为Task分配任务,直至没有满足条件的Task可分配后跳出内循环,放大本地化级别后继续尝试任务分配。我们继续分析Task如何分配任务如下:
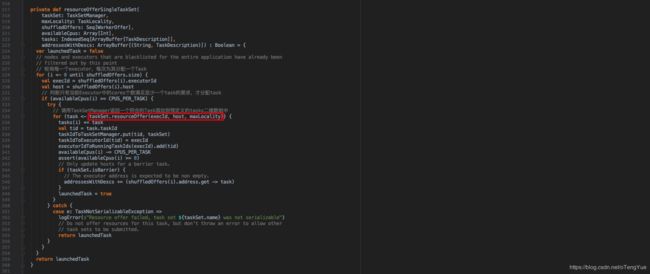
上图截图部分是每次调用会返回一个符合的Task任务,然后把任务放置在预定义的tasks二维数组中。我们继续分析TaskSetManager#resourceOffer()函数:
分析到这我们终于看到了TaskDescription,它就是对Task及其资源的封装,最终被序列化后发送给Executor真正执行任务。到这Task的分配过程基本已经完成,但还是有必要看下TaskSetManager#dequeueTask()如何取出一个符合条件的Task的,如下图:
上面过程就完成了Task任务的分配,下面我们回到CoarseGrainedSchedulerBackend#makeOffers()看如果启动已分配好的Task的,如下图:
Executor端运行Task
首先也是给出一张Executor运行流程图:
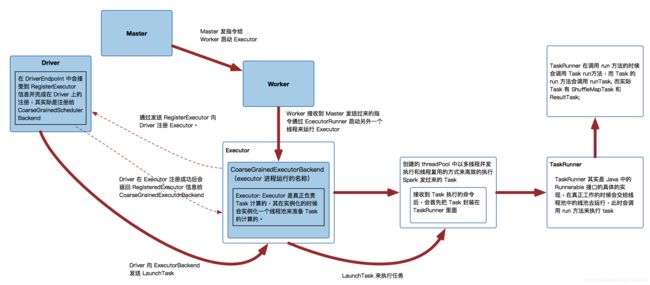
由于我们分析的是Spark-On-Yarn模式,因此只需看上图中下半部分的调用流程过程即可。
在上面生成了可执行的序列化TaskDescription对象后,会向CoarseGrainedExecutorBackend发送LaunchTask指令,CoarseGrainedExecutorBackend接收指令后先反序列化出待执行的TaskDescription对象,调用executor.launchTask(this, taskDesc)开始启动任务,如下图:
CoarseGrainedExecutorBackend是Executor运行所在的进程,Executor才是真正处理 Task 的对象,Executor类在初始化过程中会首先实例化一个线程池threadPool,每接收一个task都会通过线程池的方式执行。从Executor#launchTask()函数可以看出首先会开启一个新线程TaskRunner,然后把TaskRunner放到线程池中等待运行。我们继续分析TaskRunner#run()函数如下:

分析过程见上面代码注释,如上面画框部分执行任务继续调用Task.run()函数,主要工作是创建一个TaskContext,封装task运行过程中的上下文信息,然后调用子类的ShuffleMapTask#runTask()或ResultTask#runTask()函数执行算子计算逻辑(注:具体是哪种任务类型,是在DAGScheduler#submitMissingTasks()中会根据stage类型生成Task任务时候确定的,在Executor端反序列化后的任务就已经确定了是哪种任务类型了),如下图:
两种Task任务递归调用RDD算子过程类似,下面以ShuffleMapTask中iterator()函数(假设父RDD是MapPartitionsRDD),看如何完成递归调用的?如下图:
上面分析完了Task中RDD的递归计算,那一个Task的源RDD一般分两种:读取外部数据源RDD(例如HadoopRDD、JDBCRDD等)和ShuffledRDD。第一个是整个job的开始源RDD,主要是从外部数据源读取数据源的,不同的外部数据源有不同的实现;第二个是在产生Shuffle后拆分为父子Stage后,子Stage的Task的源RDD。我们重点看下第二个ShuffledRDD的compute函数的实现:
最后给出一张Task的底层原理机制图:
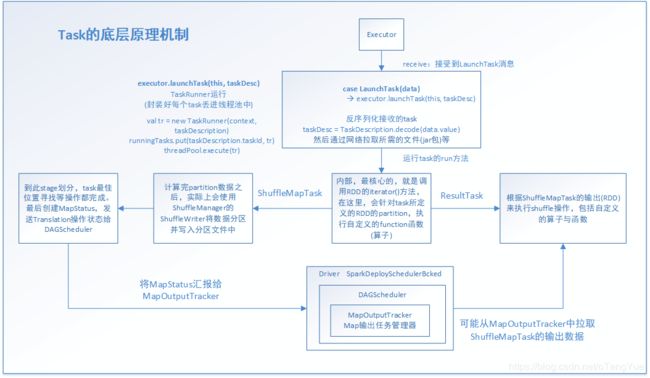
至此,Task在Executor的执行流程分析也完成了。
最后给一个WC和其DAG可视化图供理解调度过程:
import org.apache.spark._
object WordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: WordCount ");
System.exit(1);
}
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val result = sc.textFile(args(0))
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
result.saveAsTextFile(args(1))
}
}

