从零学大数据系列之数据库第一章:MySQL基础
一. 课前提示
1. 知识点
1. 数据库的相关概念
2. MySQL的安装与卸载
3. 登陆与服务
4. SQL的分类
5. DML操作
6. DQL操作
7. 约束
8.数据库的备份和恢复2. 教学重点
1. 数据库的相关概念
2. DML操作
3. DQL操作
4. 约束二. 正课内容
第一章 SQL简介及安装
1.1 简介
数据库(Data Base,简称DB):长期保存在计算机的存储设备上,数据按照一定的规则组织起来,可以被各种用户、应用共享的数据集合。
数据库管理系统(Database Management System, 简称DBMS):指的是一种用来管理和操作数据的大型软件,用于建立、使用、维护数据,对数据库进行统一的管理和控制,以保证数据的完整性和安全性。用户可以通过数据库管理系统访问数据库中的数据。
数据库:存储、维护和管理数据的集合。
数据库管理系统:数据库软件,数据库是通过这些软件进行创建和操作的。
1.2 常见的数据库管理系统
- Oracle:被认为是目前业界比较成功的关系型数据库的管理系统。Oracle可以运行在Windows、UNIX等主流的操作系统平台,完全支持所有的工业标准,并获得了最高级别的ISO标准安全性认证。
- MySQL:是一种关系型数据库管理系统。由瑞典MySQL AB公司开发,目前属于Oracle旗下产品。MySQL是目前最流行的关系型数据库管理系统(RDBMS:Relational DBMS)之一。
- SQLServer:是由微软推出的关系型数据库管理系统。
- DB2:是IBM的
1.3 关系型数据库、非关系型数据库
- 非关系型数据库:
- 采用了没有特定关系模型来组织数据。
- NOSQL基于键值对
- 关系型数据库:
- 依据所有存储数据的模型之间的关系建立的数据库。
- 所谓关系模型,指的是“一对一、一对多、多对多”等关系模型
1.4 MySQL的安装与卸载
1.4.1 安装
如果在安装的过程中缺少依赖: https://www.microsoft.com/zh-cn/download/details.aspx?id=40784





数据库已经安装完成,路径 C:\Program Files\MySQL
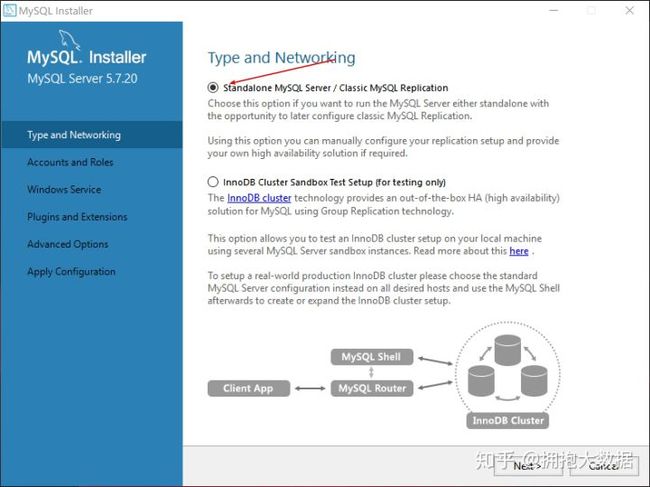
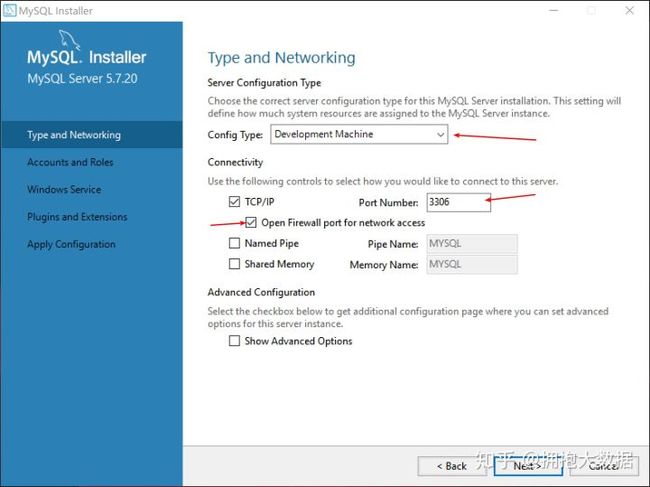


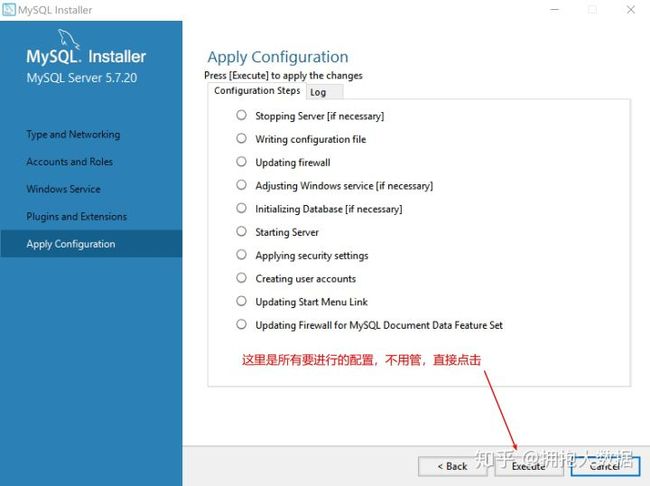
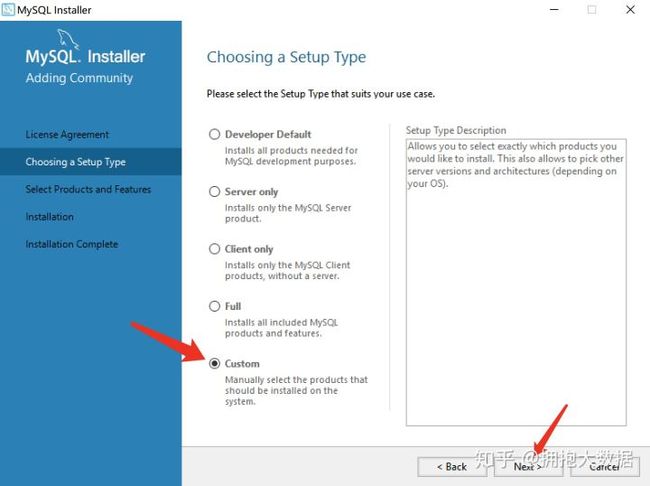
1.4.2 卸载
控制面板 -> 程序 -> 卸载程序 -> 找到MySQLServer -> 右键 -> 卸载
打开C盘 -> 打开ProgramData文件夹 -> 删除MySQL文件夹
清除注册表信息:
打开注册表:win+r 输入:regedit
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\EventLog\Application\MySQL
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\EventLog\Application\MySQL
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\EventLog\Application\MySQL1.5 启动、停止MySQL服务
1.此电脑 -> 右键 -> 管理 -> 服务 -> 找到MySQL57 -> 右键菜单

2.以管理员的身份运行命令行
1.开始菜单 -> windows系统 -> 命令提示符 -> 右键 -> 以管理员身份运行
2.输入指令:
net start mysql57// 开启服务
net stop mysql57// 停止服务
1.6 登录到数据库
1.打开命令行
2.输入指令:
如果输入mysql提示“不是内部命令,也不是外部命令”,说明需要配置环境变量:
2.1. 此电脑 -> 右键 -> 属性 -> 高级系统设置 -> 环境变量 -> 系统变量 -> Path
2.2. 将MySQLServer安装路径下的bin配置进来
C:\Program Files\MySQL\MySQLServer 5.7\bin
3.登录
3.1. mysql -u root -p// 这种方式的登录,敲回车后需要输入密码
3.2. mysql -uroot -p123456// 将用户名和密码都写到指令中,注意:没有空格1.7 MySQL密码操作
当我们进入数据库后,修改mysql密码的方式有以下四种:
第一种:mysql> alter user root@localhost identified by‘新密码';
第二种:mysql> set password for root@localhost=password('mmforu');
第三种:
mysql> use mysql
mysql> update user set authentication_string=password(‘123456') where user='root' and host='localhost';
mysql> flush privileges;
第四种:C:\Users\Michael> mysqladmin -uroot –p旧密码 password 新密码如果忘记了密码,怎么办
1. 停止MySQL57服务
2. 找到C:\ProgramData\MySQL\MySQL Server 5.7\目录下的my.ini文件,在77行下面添加skip-grant-tables
3. 启动MySQL57服务
4. 打开命令提示符界面,直接输入mysql指令,进入mysql内
5. 利用上一页的第三种方式,修改密码
6. 然后再修改my.ini文件,去掉skip-grant-tables,重启服务即可
1.8 SQL简介
SQL: Structure Query Language(结构化查询语言),SQL最早是被美国国家标准局(ANSI)确定为关系型数据库语言的美国标准。后来被国际化标准组织(ISO)采纳为关系型数据库语言的国际标准。
各种数据库厂商都支持ISO标准的SQL,类似于普通话。
各个数据库厂商在标准的基础上,定义了若干自己的扩展,类似于方言。
SQL是一种标准化的语言,允许你在数据库上进行操作,如:创建项目、查询内容、更新内容和删除内容等操作。
这些操作:Create、Read、Update、Delete,通常被称为 CRUD操作
1.9 SQL分类
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象(数据库、表、列)
- DML(Data Manipulation Language):数据操作语言,用于定义数据库记录(数据)
- DCL(Data Control Language):数据控制语言,用于定义访问权限和安全级别
- DQL(Data Query Language):数据查询语言,用于查询记录(数据)
SQL语句大小写是不区分的。
CREATE / create / Create / CrEaTe
但是,一般情况下,我们会大写。1.10 DDL使用(数据库)
1.创建数据库
# 创建数据库
CREATE DATABASE mydb1;
# 创建数据库,并采用指定的字符集
CREATE DATABASE mydb2 CHARACTER SET UTF8;2.查看数据库
# 查看当前数据库服务器中的所有的数据库
SHOW DATABASES;
# 查看创建数据库mydb1定义的信息
SHOW CREATE DATABASE mydb1;3.修改数据库
# 将数据库mydb1的字符集修改为GBK
ALTER DATABASE mydb1 CHARACTER SET GBK;4.删除数据库
DROP DATABASE mydb1;5.其他操作
# 切换当前使用的数据库
USE mydb1;
# 查询当前使用的数据库
SELECT DATABASE();1.11 表的概念
表:数据在数据库中的存储是以表的形式存在的。一个表中有若干个字段,将数据按照这些字段进行存储。
1、数据表(table),是关系型数据库的基本存储结构。一个关系型数据库是由多个表组成的。
2、数据表是二维的,它由纵向的列和横向的行组成。
3、数据表的行(Row)是横排数据,也被称之为记录(Recond)。
4、数据表的列(Column)是竖排数据,也被称之为字段(Field)。
5、表与表之间也可能存在着关系。表与表之间的关系
1. 一对一
在实际开发中应用不多。因为一对一的关系,完全可以放到一个表中
2. 一对多
一对多建表原则:在多的一方,创建一个字段,作为外键作为指向另外一的那一方的主键。
3. 多对多
多对多的建表原则:需要创建第三张表,在中间表中至少需要有两个字段。这两个字段分别作为外键指向各自一方的主键。1.12 数据类型
每一个字段在设计表的时候都要去指定类型:
int:整型
double:浮点型,例如double(5,2):表示最多有5位,其中必须有两位是小数,即最大值是 999.99
char:固定长度的字符串,例如char(5) : 'aa' 占5位
varchar:可变长度的字符串,例如varchar(5):'aa' 占2位
text:字符串类型
blob:字节类型
date:日期类型,格式是:yyyy-MM-dd
time:时间类型,格式为:hh:mm:ss
timestamp:时间戳类型,yyyy-MM-dd hh:mm:ss,会自动赋值
datetime:时间类型,yyyy-MM-dd hh:mm:ss1.13 DDL使用(表)
# DDL操作(表)
# 创建表格
CREATE TABLE t_users(name varchar(50), age INT, gender VARCHAR(10), height INT, weight INT);
# 删除表格
DROP TABLE t_users;
# 查看当前数据库中所有的表
SHOW TABLES;
# 查看创建一个表的信息
SHOW CREATE TABLE t_users;
# 查看一张表的字段信息
DESC t_users;
# 给一张表添加一个字段
ALTER TABLE t_users ADD score DOUBLE(5,2);
# 修改一张表的字段类型
ALTER TABLE t_users MODIFY score INT;
# 修改一张表的字段名
ALTER TABLE t_users CHANGE name uname VARCHAR(50);
# 修改一张表的字符集
ALTER TABLE t_users CHARACTER SET GBK;
# 删除一张表中的字段
ALTER TABLE t_users DROP score;第二章:数据库基本操作
2.1 远程工具的使用
(1) Connection Name(连接名):这个文本框,就是让你给此次连接起个昵称而已,因此随便写。
(2) hostname(主机名): 添加数据库服务端所在的主机IP
(3) port(端口号):MySQL的端口号,一般情况下都是默认的3306
(4) username(用户名):即你要使用哪个用户进行登陆数据库服务端。如,超级管理员root, 或者是其他普通用户。
(5) password(密码):你所使用的用户对应的密码
(6) default schema:表示你要连接MySQL里的哪个数据库(数据存储空间)。2.2 DML操作
DML指的是对数据库中的数据进行增、删、改的操作。不要和DDL搞混了。
在SQL中,字符串类型和日期类型需要用单引号括起来
空值:null / NULL
# 增:INSERT INTO
# 向表t_users插入一条数据,并且给每一个字段进行赋值,小括号中的是字段对应的值。要保证顺序。
INSERT INTO t_users VALUES('lily', 21, 'female', 172, 60);
INSERT INTO t_users VALUES('lucy', 21, 'female', 171, 60);
# 向表t_users插入一条数据,并且对部分字段进行赋值
INSERT INTO t_users (uname, age, gender) VALUES('JimGreen', 22, 'male');
# 向表t_users插入一条数据,并且对部分字段进行赋值,字段的顺序可以随意,但是要保证values后面的值要和前面的字段匹配
INSERT INTO t_users (age, gender, uname) VALUES(10, 'male', 'polly');INSERT INTO `t_name` VALUES(值1, 值2, ...)
INSERT INTO `t_name` (字段1, 字段2, ...) VALUES (值1, 值2, ...)2.2.1 插入数据
INSERTINTO`t_name` VALUES(值1, 值2, ...)
INSERTINTO`t_name` (字段1, 字段2, ...) VALUES(值1, 值2, ...)2.2.2 where
在进行数据的删除、修改、查询的时候,可以使用where对数据进行一个过滤。
= :相等比较(类似于java中的==)
!= <> : 表示不相等
> < >= <= : 大小比较
BETWEEN...AND... : 在xxx和xxx之间
IN(set) :在括号中所有值之间取
IS NULL
AND、OR、NOT
2.2.3 删除数据
# 删除数据
DELETE FROM t_student;
# 按照条件进行删除 WHERE
DELETE FROM t_student WHERE sname = '韦一笑';
# 删除掉表中所有的数据
TRUNCATE TABLE t_student;
DELETE 和 TRUNCATE
delete删除表中的数据,表结构还在;删除的数据可以恢复。
truncate是直接将表DROP掉,然后再按照原来的结构重新创建一张表。数据不可恢复。
truncate删除效率比delete高。2.2.4 修改数据
# 将所有的数据中的年龄都修改为60
UPDATE t_student SET sage = 60;
# 将姓名为'张三丰'的数据年龄改成60
UPDATE t_student SET sage = 60 WHERE sname='张三丰';
# 将姓名为'谢逊'的数据年龄改成50, java成绩修改成60
UPDATE t_student SET sage = 50, score_java = 60 WHERE sname = '谢逊';
# 将姓名为'灭绝师太'的数据mysql成绩在现有基础上加10
UPDATE t_student SET score_mysql = score_mysql / 10 where sname = '灭绝师太';第三章 基本查询语言
3.1 基本查询语言的结构
最简单的查询语句:
select...from....
一个完整的普通查询语句结构如下:
select [distinct].....from....[where....][group by .....][having.....][order by.....][limit.....]3.2 查询语句的执行顺序
1. 先执行from子句:基于表进行查询操作
2. 再执行where子句:进行条件筛选或者条件过滤
3. 再执行group by子句:对剩下的数据进行分组查询。
4. 再执行having子句:分组后,再次条件筛选或过滤
5. 然后执行select子句:目的是选择业务需求的字段进行显示
6. 再执行order by子句:对选择后的字段进行排序
7. 最后执行limit子句:进行分页查询,或者是查询前n条记录3.3 别名的用法
在select语句中,可以对表或者是列起别名操作。在使用汉字作为列别名时,可以加单双引号,也可不加。表别名不能加单双引号。
reg:
select name 姓名,
(year(now())-year(birth)) 年龄
from test1 t;
reg:
select e.empno 员工编号,e.ename,e.job,mgr '领导编号',hiredate,sal,comm,deptno from emp e;3.4 where子句的使用
作用:用于条件筛选或过滤
1)关系表达式: >,>=,<,<=,=,!=,<>
2)多条件连接符: and,or, [not] between ..and..
3)集合操作: [not] in (set),
>all(set), any(set), 1600
reg:查询工资大于1600并且小于2500的所有员工的编号,姓名,职位,工资
select empno,ename,job,sal from emp where sal>1600 and sal<2500;
select empno,ename,job,sal from emp where sal between 1600 and 2500;
reg:查询10,20号部门的所有员工的信息。
select * from emp where deptno not in (10,20);
reg:查询不是10号部门中姓名第二个字符是m的员工信息。
select * from emp where deptno<>10 and ename like '_m%'; 3.5 order by子句
用于查询排序的,通常放置在一个查询语句的最后部分。
语法: order by colName [asc|desc] [,colName [asc|desc]]
asc:升序, 默认情况就是升序
desc:降序
reg:查询员工表中的所有员工信息,按照工资降序排序
select * from emp order by sal desc;
reg:查询员工表中的所有员工信息,按照工资降序排序,如果相同,再按照奖金升序排序
select * from emp order by sal desc,comm asc;3.6 group by子句
1.需求:
有的时候,需要分组统计一些,最大值,最小值,平均值,和,总数之类的这样的信息,此时需要分组查询。
2.聚合函数:也叫分组函数
- count(): 统计每组满足的记录总数
- max():统计每组满足条件的最大值
- min():统计每组满足条件的最小值
- avg():统计每组满足条件的平均值
- sum():统计每组满足条件的总和。
注意:
- 所有的聚合函数,都会忽略字段为null的那条记录。
- count(*),不会忽略null值所在的行记录,即通常用于统计总行数。
3. 在分组查询时,只有分组字段可以写在select子句中,其他不是分组的字段,不应该写在select子句中,无意义
多字段进行分组:
A B 字段组合情况下:组的数组最多为 m*n
1 a 1001
1 b 1002
2 b
2 c
3 a
3 b
1 a 1003
1 b 1004
4. 聚合函数处理null值,可以使用ifnull(colName, value).
- ifnull(colName,value): 如果colName对应的值不为空,就使用本身的值,如果为null,使用value.
# 案例:查询每个部门中的每种职位的最高工资,最低工资,工资之和
select deptno,job ,max(sal),min(sal),sum(sal) from emp group by job,deptno;
# 案例: 查询所有员工的平均工资,平均奖金 使用ifnull函数
select avg(ifnull(sal,0)),avg(ifnull(comm,0)) from emp;
3.7 having子句
只能使用在分组查询子句后面。起到再过滤的作用。
# 查询部门平均工资大于1000部门号,平均工资。
select deptno,avg(ifnull(sal,0)),max(sal) avg_sal from emp group by deptno having avg(ifnull(sal,0)) >1000;
# 查询每种职位的最高工资大于1500的职位、最高工资,平均工资,平均奖金。
select job,max(sal),avg(ifnull(sal,0)),avg(ifnull(comm,0)) from emp group by job having max(sal)>1500;
3.8 去重查询
有的时候,我们需要查询表中有那些不同的数据。不需要重复出现,此时可以使用distinct关键字进行去重处理
注意:distinct关键字只能放在select关键字之后。
比如: 查询有那些部门号
3.9 分页查询
- 需求:当一页的数据量过大时,我们可以进行分页显示操作。注意:分页查询时,一般都要进行先排序,再分页。
- 关键字limit.
- 语法:limit m[,n];
m 表示从第几条记录开始查询,
n表示要查询的记录数目。
注意:mysql的记录index从0开始。
一个参数的含义:limit n
表示从0开始查询n条记录
案例1:每页5条记录,查询第二页的数据。
select empno,ename from emp limit 5,5;
案例2:查询第page页的数据, 每页大小为pageSize。limit的写法如下:
limit (page-1)*pageSize , pageSize
第四章 约束constraint(重点掌握)
4.1 概念
- 完整性约束条件,简称约束,用于保证表中数据的完整性和安全性。
- 约束是对表进行的一种强制性的校验规则。
- 在进行DML操作时,必须符合约束条件,否则不能执行。4.2 非空约束
- 非空约束:not null,简称NN
- 如果对字段设置了not null,在DML操作,不能为空。
- 建表写法:
create table tableName(
tid int,
tname varchar(20) not null,
tage int
);
- 建表后写法:
alter table tableName modify colName type not null;4.3 唯一性约束
- 唯一性约束:unique,简称 UK
- 如果字段设置了唯一性约束,那么在表中此字段的值不能重复,但是可以为null(无穷大不等于无穷大)
- 建表写法
create table tableName(
tid int,
tname varchar(20) not null,
username varchar(20) unique
);4.4 主键约束
- 主键约束:primary key,简称PK
- 主键约束是非空约束和唯一性约束的组合形式,表示字段的值不能为null且唯一。通常用于作为记录的唯一标识来 使用。
- 选择主键约束的字段要求:
1.对业务需求没有意义的字段,比如序号
2.如果设置了主键约束,那么此字段最好不好人为的修改。而是自动生成。使用auto_increment(自增序列)
3.不建议对动态赋值的字段进行设置,比如时间戳。
- 建表时写法:
create table tableName(
tid int primary key auto_increment,
tname varchar(20) not null
);
- 建表后设置:
alter table tableName add primary key(colName);4.5 外键约束
- 外键约束:foreign key,简称FK
- 外键约束是指 字段A的值,依赖于字段B的值。这两个字段可以在同一张表中,也可以在不同的表中。字段A所在的
表称之为从表(副表),字段B所在的表称之为主表(父表)。字段A的值也可以为null. 字段B必须为主键约束。
- 建表时写法
create table tableName(
tid int primary key auto_increment,
tname varchar(20),
tmgr int,
constraint constraintName Foreign key(tmgr) references tableName(tid)
);
建表后写法:
alter table tableName1 add constraint constraintName foreign key(colName1) references tableName2(colName2)4.6 检查约束
- 检查约束:check,简称ck。
- mysql不支持,可以使用枚举代替。
- 建表语句:
create table tableName(
tid int,
tname varchar(20),
tgender char(1) check(tgender in('f','m'))
);
案例:
create table temp_5(
tid int,
tname varchar(20),
tgender char(1) check(tgender in('f','m')) #语法通过,但是不生效
);
insert into temp_5 values (1001,'zs','a');
select * from temp_5;
案例:
create table temp_6(
tid int,
tname varchar(20),
tgender enum('f','m') #枚举写法
);
insert into temp_6 values (1001,'zs','m');第五章 数据库的备份和恢复
5.1 手动复制的方法
a.可以先登陆mysql 查看数据文件的位置:
show global variables like '%datadir%'
b.在某一个位置创建备份目录backup. 比如:D:\backup
c.将%datadir%下的所有文件,copy到backup下。
d.先模拟某一个数据库mydb毁坏。drop database mydb;
e.先终止服务项。再将所有的数据,copy到%datadir%下。然后再去查看。5.2 使用mysqldump命令进行备份
a.在命令提示符下输入(别登陆到mysql内):
mysqldump -uUsername -pPwd --all-databases > filename.sql #备份所有数据库
b.备份一部分数据库
mysqldump -uUsername -pPwd --databases dbname1 dbname2 > filename.sql
c.备份某个数据库中的某些表
mysqldump -uUsername -pPwd dbname tablename1 tablename2 > filename.sql
d.恢复数据
登入到mysql内,使用source命令
语法: source filename.sql
注意: 路径是绝对路径5.3 使用其他工具进行数据的导入和导出
略