bentoml部署深度学习模型(一)
核心概念(Core Concepts)
文章来源:https://docs.bentoml.org/en/latest/concepts.html
BentoML的主要思想是,数据科学团队应该能够以易于测试、易于部署和易于集成的方式发布他们的模型。为了做到这一点,需要帮助数据科学家开发一个构建和发布预测服务的工具,而不是将经过pickle的模型文件或Protobuf文件上传到服务器上。bentoml.BentoService公司是使用BentoML构建此类预测服务的基类。bentoml是用于创建预测服务的基类,这里给出一个最简单的部署案例:
import bentoml
from bentoml.handlers import DataframeHandler
from bentoml.artifact import SklearnModelArtifact
@bentoml.env(auto_pip_dependencies=True)
@bentoml.artifacts([SklearnModelArtifact('model')])
class IrisClassifier(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
return self.artifacts.model.predict(df)
每一个BentoService类,可以通过@bentoml.artifact 接口包含多个模型,也可以包含多个API接口。每一个API接口的定义,都需要指定一个BentoHandler的数据类型,该类型,定义了API的输入类型。BentoML提供了覆盖绝大多数情景的数据类型,包括DataframeHandler,TensorHandler,ImageHandler,JsonHandler。
一旦一个机器学习模型训练好了,用一个BentoService对象可以把训练好的模型打包,具体打包的方式,是通过 BentoService的pack方法实现的。打包好后,API接口就可以通过 self.artifacts.ARTIFACT_NAME来访问训练好的模型做预测了。比如上述案例中,artifact类用名字"model"来初始化,所以,就可以通过 self.artifacts.model访问模型了。
做完上述工作后,BentoService 就可以用于预测了。更重要的是,BentoML解决了将整个BentoService保存到磁盘、分发保存的文件以及在测试和生产环境中复制完全相同的预测服务的问题。
要保存一个BentoService对象,只需简单的调用 BentoService的save方法,在这个过程中,BentoML将会做如下工作:
- 保存基于机器学习训练框架下得到的模型,以及保存使用的artifact数据类型。
- 自动获取BentoService类的所有依赖,并且把依赖写到requirements.txt文件。
- 保存所有的本地python代码依赖。
- 将生成的所有文件放在一个文件目录中,默认情况下,该目录是由BentoML管理,也可以自己指定目录。
from sklearn import svm
from sklearn import datasets
clf = svm.SVC(gamma='scale')
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X, y)
# Create a iris classifier service with the newly trained model
iris_classifier_service = IrisClassifier()
iris_classifier_service.pack("model", clf)
# Test invoking BentoService instance
iris_classifier_service.predict([[5.1, 3.5, 1.4, 0.2]])
# Save the entire prediction service to file bundle
saved_path = iris_classifier_service.save()
print("saved_path:{saved_path}")
保存的BentoService文件目录称为Bento。它是一个版本控制的文件目录,包含运行此预测服务所需的所有信息。
对于每一个机器学习模型,可以把Bento想象成一个docker镜像,或者一个二进制软件。Bento可以在模型训练结束后自动生成,新的Bento反应了模型的最新信息,可以很容易的保存、分发Bento文件、以及测试预测服务,然后把模型部署到生产。
BentoML跟踪保存的所有bento,并为模型管理提供web UI和CLI命令。默认情况下,BentoML将所有模型文件和元数据保存在本地文件系统中。对于一个开发团队的配置来讲,建议为整个团队运行一个共享的BentoML服务器,该服务器将其所有Bento文件和元数据存储在云中(例如RDS、S3)。这允许您的ML团队轻松地共享、查找和使用彼此的模型和模型服务端点。在这里阅读更多关于它的信息。
BentoML CLI Listing recent Bento:
> bentoml list
BENTO_SERVICE CREATED_AT APIS ARTIFACTS
IrisClassifier:20200121114004_360ECB 2020-01-21 19:40 predict<DataframeHandler> model<SklearnModelArtifact>
IrisClassifier:20200120082658_4169CF 2020-01-20 16:27 predict<DataframeHandler> clf<PickleArtifact>
...
BentoML model management web UI:
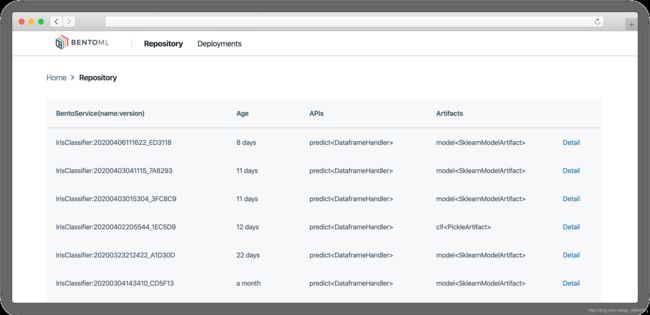

创建BentoService
通过创建一个预测类,这个类继承 bentoml.BentoService,来实现自己的预测服务。建议将你的BentoService类源代码放入一个单独的python文件中,并将这个类与模型训练的代码放在一起用git托管。
BentoMl的设计,让BentoService的代码很容易就放在模型训练之后,这样可以将模型训练和模型服务绑定在一起,使得后期模型的管理,测试、上线部署变得很容易。
注意
BentoService类不能在__main__模块中定义,这意味着类本身不应该在Jupyter笔记本单元或python交互shell中定义。但是,您可以使用jupyter notebook中的%write file magic命令将BentoService类定义写入单独的文件,请参阅BentoML quickstart notebook中的示例。
BentoService只能使用Python创建。但是可以使用BentoML的其他语言/框架训练模型,并从BentoML的模型管理、API服务器、dockerisation和性能优化中获益。为此,您需要创建自定义组件。对R和Spark MLlib模型的支持在我们的规划之中。
定义依赖(Defining Service Environment)
定义服务的环境
bentoml.env用于定义预测服务的环境设置和依赖项的API。下面是BentoML支持的依赖类型:
PyPI Packages
Python 的PyPi包是最常用的依赖,BentoML提供了一种机制,可以自动计算出BentoService python类所需的PyPI包,只需使用auto-pip-dependencies=True选项:
@bentoml.env(auto_pip_dependencies=True)
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
return self.artifacts.model.predict(df)
如果模型服务所需的PyPI包的特定版本不同于您的模型训练环境,或者如果auto_pip_dependencies=True选项不适用于您的案例,您还可以手动指定PyPI包的列表,例如:
pip_dependencies=['scikit-learn']
)
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
return self.artifacts.model.predict(df)
类似地,如果您已经有在依赖包名称,并且已经放在了文件requirements.txt.txt中,就可以指定这个依赖包文件的路径,比如:
@bentoml.env(requirements_txt_file='./requirements.txt')
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
return self.artifacts.model.predict(df)
Conda Packages
同样的,可以指定Conda包依赖,下面是一个需要H2O的Conda包示例预测服务:
@bentoml.artifacts([H2oModelArtifact('model')])
@bentoml.env(
pip_dependencies=['pandas', 'h2o==3.24.0.2'],
conda_channels=['h2oai'],
conda_dependencies=['h2o==3.24.0.2']
)
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
return self.artifacts.model.predict(df)
注意:这里的Conda包由于AWS Lambda平台的限制,不能在AWS Lambda部署中使用。
Bash脚本(Init Bash Script)
Init setup脚本用于自定义提供docker容器的API。用户可以通过init安装脚本将任意bash脚本插入docker构建过程,以安装额外的系统依赖项或执行预测服务所需的其他设置。
@bentoml.env(
auto_pip_dependencies=True,
setup_sh="./my_init_script.sh"
)
class ExamplePredictionService(bentoml.BentoService):
...
@bentoml.env(
auto_pip_dependencies=True,
setup_sh="""\
#!/bin/bash
set -e
apt-get install --no-install-recommends nvidia-driver-430
...
"""
)
class ExamplePredictionService(bentoml.BentoService):
...
如果您有一个特定的docker镜像,您想用于您的API服务器,我们正在研究自定义docker镜像支持。如果您有兴趣帮助测试此功能,请与我们联系。
模型打包工件(Packaging Model Artifacts)
BentoML的API允许用户指定BentoService所需的经过训练后的模型。当保存和加载BentoService时,BentoML自动处理模型序列化和反序列化。因此BentoML要求用户为他们正在使用的机器学习框架选择正确的类型。BentoML为大多数流行的ML框架提供了内置的类型,您可以在这里找到支持的框架列表。如果您使用的ML框架不在列表中,请告诉我们,我们将考虑添加它的支持。要指定BentoService所需的模型类型,请使bentoml.artifacts并传递一个模型类型列表,并在预测服务中为每个模型指定一个唯一的名称。下面是一个示例预测服务,它包含两个经过训练的模型:
import bentoml
from bentoml.handlers import DataframeHandler
from bentoml.artifact import SklearnModelArtifact, XgboostModelArtifact
@bentoml.env(auto_pip_dependencies=True)
@artifacts([
SklearnModelArtifact("model_a"),
XgboostModelArtifact("model_b")
])
class MyPredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
# assume the output of model_a will be the input of model_b in this example:
df = self.artifacts.model_a.predict(df)
return self.artifacts.model_b.predict(df)
序列化模型:
svc = MyPredictionService()
svc.pack('model_a', my_sklearn_model_object)
svc.pack('model_b', my_xgboost_model_object)
svc.save()
对于大多数模型服务场景,我们建议每个预测服务使用一个模型,并将非相关模型分离为单独的服务。唯一的例外是当多个模型相互依赖时,如上面的示例。
接口函数和输入数据类型(API Function and Handlers)
BentoService API是客户端访问预测服务的入口点。它是通过编写API处理函数(BentoService类中的方法)来定义的,该函数在客户端发送推断请求时被调用。用户需要用 @bentoml.api,并传入一个Handler类,该类定义API函数所需的输入格式。例如,如果您的模型期望将DataFrame格式的数据作为输入,则可以对您的API使用DataframeHandler,例如:
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
assert type(df) == pandas.core.frame.DataFrame
return postprocessing(model_output)
当指定输入是DataframeHandler格式时,服务端会将client端的预测请求参数:比如json格式、csv格式的输入参数,转换为pandas.DataFrame格式。
用户可以在处理数据的API函数中编写任意的python代码。除了将预测输入数据传递给模型进行推理外,用户还可以在API函数中编写数据提取、数据预处理和后处理。例如:
from my_lib import preprocessing, postprocessing, fetch_user_profile_from_databasae
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df):
user_profile_column = fetch_user_profile_from_databasae(df['user_id'])
df['user_profile'] = user_profile_column
model_input = preprocessing(df)
model_output = self.artifacts.model.predict(model_input)
return postprocessing(model_output)
注意:可以查看支持哪些输入数据集类型。
需要注意的是,在BentoML中,传递给用户定义的API函数的输入变量始终是一个用于预测的输入列表。BentoML用户必须确保他们的API函数代码正在处理一个batch的输入数据。
这种设计使得BentoML能够在在线API服务中进行微批处理(Micro-Batching),这是模型服务系统最有效的优化技术之一。
接口返回值(API Function Return Value)
API接口可以返回如下类型的数据:
pandas.DataFrame
pandas.Series
numpy.ndarray
tensorflow.Tensor
# List of JSON Serializable
# JSON = t.Union[str, int, float, bool, None, t.Mapping[str, 'JSON'], t.List['JSON']]
List[JSON]
用户API函数的任务是确保预测结果的列表与输入序列的顺序匹配,并且具有完全相同的长度。
注意:
在BentoML 0.7.0之前,API函数可以一次处理并返回一个预测请求,但是在引入自适应微批处(micro batching)理特性之后,不再推荐这样做。
多服务接口(Service with Multiple APIs)
BentoService可以包含多个接口,这使得构建支持不同客户端的不同访问模式的预测服务变得非常容易,例如:
from my_lib import process_custom_json_format
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(DataframeHandler)
def predict(self, df: pandas.Dataframe):
return self.artifacts.model.predict(df)
@bentoml.api(JsonHandler)
def predict_json(self, json_arr):
df = processs_custom_json_format(json-arr)
return self.artifacts.model.predict(df)
该案例演示了如何定义连个API的情况,两个API底层预测函数是一样的,不同的是,输入不同,第一个API的输入是DataFrame格式的数据,第二个API的输入是一个json,然后需要一个处理json的函数,来把json类型的数据,转换为DataFrame,最后传递给预测函数。
确保为每个API指定不同的名称。BentoML使用方法名作为API的名称,这将成为它生成的服务端点的一部分。
API的调用(Operational API)
完成模型训练/评估的代码和BentoService的定义之后,以下是创建BentoService实例并将其保存以供服务所需的步骤:
- 第一步,训练模型
- 第二步,创建BentoService 实例
- 第三步, 用BentoService#pack打包训练好的模型
- 第四步,用 BentoService#save保存一个Bento
下面给一个案例:
from sklearn import svm
from sklearn import datasets
# 1. 第一步,Model training
clf = svm.SVC(gamma='scale')
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X, y)
# 2. 第二步,Create BentoService instance
iris_classifier_service = IrisClassifier()
# 3. 第三步,Pack trained model artifacts
iris_classifier_service.pack("model", clf)
# 4. 第四步,Save
saved_path = iris_classifier_service.save()
完成上述四步,就创建了一个Bento,可以理解为一个docker镜像,也可以理解为一个python包。
怎么保存模型(How Save Works)
BentoService#save_to_dir(path)是将BentoService保存到目标目录的基本操作。save_to_dir序列化模型组件,并将所有相关代码、依赖项和配置保存到给定路径中。
用户可以使用 bentoml.load(path) 从保存的文件路径加载完全相同的BentoService实例。这使得以相同的方式轻松地将预测服务分发到测试和生产环境中成为可能。
BentoService#save本质上调用了BentoService#save_to_dir(path),同时跟踪您创建的所有预测服务并维护这些已保存包的文件结构和元数据信息。
模型服务(Model Serving)
一旦BentoService被保存为Bento,就可以在不同的场景下部署了。
有三种主要的服务模式:
- 在线服务-客户端通过API端点近实时地访问预测
- 离线批量服务-在存储系统中预计算预测和保存结果
- 设备端服务-分布式模型并在移动或物联网设备上运行
BentoML对在线服务和离线批量服务都有很好的支持。它有一个高性能的API服务器,可以加载保存的Bento并公开restapi供客户端访问。它还提供了加载Bento的工具,并为其提供一批用于离线推断的输入。仅当客户端具有Python运行时时(例如,路由器或树莓派中的模型服务)才支持边缘服务。
在线服务(Online API Serving)
一旦保存了BentoService,就可以轻松地启动REST API服务器来测试发送请求和与服务器交互。例如,在“入门指南”中保存bentoservice后,可以立即使用以下命令启动API服务器:
bentoml serve IrisClassifier:latest
如果您使用的是save_to_dir,或者您直接从其他计算机复制了保存的Bento文件目录,那么BentoService IrisClassifier不会在本地BentoML存储库中注册。在这种情况下,您仍然可以通过提供保存的BentoService的路径来启动服务器:
bentoml serve $saved_path
REST API请求格式由每个API的处理程序类型和处理程序配置决定。更多细节可以在BentoML API Handler Refernces找到。
要运行生产API服务器,请确保改用bentoml serve-gunicorn命令,或使用Docker容器进行部署。
bentoml serve-gunicorn $saved_path --enable-microbatch --workers=2 --port=3000
API容器化部署(API Server Dockerisation)
当您准备将服务部署到生产环境中时,可以使用BentoML轻松创建包含模型API服务器的docker映像。保存Bento时,BentoML也会在同一目录中生成Dockerfile。Dockerfile是一个文本文档,包含创建docker映像所需的所有命令,docker build命令从Dockerfile生成映像。
# Find the saved path of the latest version of IrisClassifier Bento
saved_path=$(bentoml get IrisClassifier:latest -q | jq -r ".uri.uri")
# Build docker image using saved_path directory as the build context, replace the
# {username} below to your docker hub account name
docker build -t {username}/iris_classifier_bento_service $saved_path
# Run a container with the docker image built and expose port 5000
docker run -p 5000:5000 {username}/iris_classifier_bento_service
# Push the docker image to dockerhub for deployment
docker push {username}/iris_classifier_bento_service
下面是一个使用上面构建的docker映像在Kubernetes集群中创建的部署示例:
apiVersion: apps/v1 # for k8s versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: iris_classifier
spec:
selector:
matchLabels:
app: iris_classifier
replicas: 3
template:
metadata:
labels:
app: iris_classifier
spec:
containers:
- name: iris_classifier_bento_service
image: {username}/iris_classifier_bento_service:latest
ports:
- containerPort: 5000
自适应的微批处理(Adaptive Micro-Batching)
微批处理是将输入的预测请求分组成小批,以实现模型推断任务中批处理的性能优势的一种技术。BentoML在剪纸机的启发下实现了这样一个微批处理层:一个低延迟的在线预测服务系统。
考虑到从微批处理中模型服务性能可以得到很大提升,bentomlapi被设计成在用户端不需要任何代码更改的情况下与微批处理一起工作。这就是为什么所有的API处理程序都被设计为接受输入是一个列表,如API函数和处理程序部分所述。
目前,微批处理仍然是一个beta版本,用户可以在运行BentoML API服务器时通过传递参数来决定是否启用微批处理:
# Launch micro batching API server from CLI
bentoml serve-gunicorn $saved_path --enable-microbatch
# Launch model server docker image with micro batching enabled
docker run -p 5000:5000 -e BENTOML_ENABLE_MICROBATCH=True {username}/iris-classifier:latest
程序访问(Programmatic Access)
保存的BentoService也可以从保存的Bento直接load,并直接用Python访问。主要有三种方法:
- 1.从保存的Bento目录加载 bentoml.load(path)API
import bentoml
bento_service = bentoml.load(saved_path)
result = bento_service.predict(input_data)
这种方法的好处是灵活性。用户可以轻松地在其后端应用程序中调用保存的BentoService,并以编程方式选择要加载的模型以及如何使用它们进行推理。
- 2.Install BentoService as a PyPI package
Bento目录也可以安装pip,如《入门指南》中所示:
pip install $saved_path
# Your bentoML model class name will become the package name
import IrisClassifier
installed_svc = IrisClassifier.load()
installed_svc.predict([[5.1, 3.5, 1.4, 0.2]])
这种方法确保在安装时为BentoService安装了所有必需的pip依赖项。当您的数据科学团队将预测服务作为一个独立的python包发布时,它是非常方便的,可以由各种不同的开发人员共享以进行集成。
- 3.shell命令行访问
类似地,可以使用BentoML CLI工具加载Bento进行推断。一旦通过pip安装了bentoml,就可以使用CLI命令bentoml。要加载已保存的Bento文件,只需使用bentoml run命令,并为其指定名称和版本对或Bento的路径:
# With BentoService name and version pair
bentoml run IrisClassifier:latest predict --input='[[5.1, 3.5, 1.4, 0.2]]'
bentoml run IrisClassifier:latest predict --input='./iris_test_data.csv'
# With BentoService's saved path
bentoml run $saved_path predict --input='[[5.1, 3.5, 1.4, 0.2]]'
bentoml run $saved_path predict --input='./iris_test_data.csv'
或者,如果您已经pip安装了BentoService,它会专门为此BentoService提供一个CLI命令。CLI命令与BentoService类名相同:
IrisClassifier run predict --input='[[5.1, 3.5, 1.4, 0.2]]'
IrisClassifier run predict --input='./iris_test_data.csv'
离线批服务(Offline Batch Serving)
上述编程访问部分中的所有三种方法都可以用于执行单机批量离线模型服务。取决于输入数据的格式,如果输入是一个list(即训练时的一个batch),每一个元素表示一个独立的输入,那么就支持batch处理。预测可以使用BentoService的Python API或Bash CLI命令启动。这使得与 Apache Airflow和Celery等作业调度工具的集成变得非常容易。
对于集群上运行的大型数据集上的批处理服务,BentoML团队正在为BentoService构建Apache Spark UDF加载器。此功能仍处于测试阶段。如果您有兴趣帮助测试或改进它,请与我们联系。
模型管理(Model Management)
默认情况下,BentoService#save会将所有BentoService保存的捆绑文件保存在 / b e n t o m l / r e p o s i t o r y / /bentoml/repository/ /bentoml/repository/目录下,然后将服务名称和服务版本保存为子目录名称。保存的BentoService的所有元数据都存储在~/bentoml/storage.db的本地SQLite数据库文件中.
用户可以方便地查询和使用他们创建的所有BentoService,例如,列出所有创建的BentoService:
> bentoml list
BENTO_SERVICE AGE APIS ARTIFACTS
IrisClassifier:20200323212422_A1D30D 1 day and 22 hours predict model
IrisClassifier:20200304143410_CD5F13 3 weeks and 4 hours predict model
SentimentAnalysisService:20191219090607_189CFE 13 weeks and 6 days predict model
TfModelService:20191216125343_06BCA3 14 weeks and 2 days predict model
> bentoml get IrisClassifier
BENTO_SERVICE CREATED_AT APIS ARTIFACTS
IrisClassifier:20200121114004_360ECB 2020-01-21 19:45 predict model
IrisClassifier:20200121114004_360ECB 2020-01-21 19:40 predict model
> bentoml get IrisClassifier:20200323212422_A1D30D
{
"name": "IrisClassifier",
"version": "20200323212422_A1D30D",
"uri": {
"type": "LOCAL",
"uri": "/Users/chaoyu/bentoml/repository/IrisClassifier/20200323212422_A1D30D"
},
"bentoServiceMetadata": {
"name": "IrisClassifier",
"version": "20200323212422_A1D30D",
"createdAt": "2020-03-24T04:24:39.517239Z",
"env": {
"condaEnv": "name: bentoml-IrisClassifier\nchannels:\n- defaults\ndependencies:\n- python=3.7.5\n- pip\n",
"pipDependencies": "bentoml==0.6.3\nscikit-learn",
"pythonVersion": "3.7.5"
},
"artifacts": [
{
"name": "model",
"artifactType": "SklearnModelArtifact"
}
],
"apis": [
{
"name": "predict",
"handlerType": "DataframeHandler",
"docs": "BentoService API",
"handlerConfig": {
"output_orient": "records",
"orient": "records",
"typ": "frame",
"is_batch_input": true,
"input_dtypes": null
}
}
]
}
}
类似地,可以使用Bento名称和版本名称,直接加载和运行这些BentoService。例如:
> bentoml serve IrisClassifier:latest
* Serving Flask app "IrisClassifier" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
> bentoml run IrisClassifier:latest predict --input='[[5.1, 3.5, 1.4, 0.2]]'
[0]
自定义模型储存库(Customizing Model Repository)
BentoML有一个独立的组件YataiService,用于处理模型存储和部署。BentoML默认使用本地YataiService实例,该实例将BentoService文件保存到 ∼ \sim ∼/BentoML/repository/,并将其他元数据保存到~/BentoML/storage.db.
用户还可以自定义此项以使其适用于团队设置,从而使数据科学家团队能够轻松地共享、使用和部署彼此创建的模型和预测服务。为此,用户需要从BentoML cli命令yatai-service-start设置运行YataiService的主机服务器:
> bentoml yatai-service-start --help
Usage: bentoml yatai-service-start [OPTIONS]
Start BentoML YataiService for model management and deployment
Options:
--db-url TEXT Database URL following RFC-1738, and usually can
include username, password, hostname, database name as
well as optional keyword arguments for additional
configuration
--repo-base-url TEXT Base URL for storing saved BentoService bundle files,
this can be a filesystem path(POSIX/Windows), or an S3
URL, usually starts with "s3://"
--grpc-port INTEGER Port for Yatai server
--ui-port INTEGER Port for Yatai web UI
--ui / --no-ui Start BentoML YataiService without Web UI
-q, --quiet Hide all warnings and info logs
--verbose, --debug Show debug logs when running the command
--help Show this message and exit.
BentoML为运行YataiService提供了一个预先构建的docker镜像。对于每一个BentoML版本,一个新的镜像将被推送到bentoml/yatai-service服务下的docker hub,镜像标签与PyPI包版本相同。例如,使用以下命令启动BentoML版本0.7.2的YataiService,从本地~/BentoML目录下的本地BentoML存储库加载数据:
> docker run -v ~/bentoml:/bentoml \
-p 3000:3000 \
-p 50051:50051 \
bentoml/yatai-service:0.7.2 \
--db-url=sqlite:///bentoml/storage.db \
--repo-base-url=/bentoml/repository
为团队部署YataiService的推荐方法用一个远程PostgreSQL数据库和S3存储数据库。例如,部署以下docker容器以运行配置有远程数据库和S3存储的YataiService,以及用于管理在AWS上创建的部署的AWS凭据:
> docker run -p 3000:3000 -p 50051:50051 \
-e AWS_SECRET_ACCESS_KEY=... -e AWS_ACCESS_KEY_ID=... \
bentoml/yatai-service:0.7.2 \
--db-url postgresql://scott:tiger@localhost:5432/bentomldb \
--repo-base-url s3://my-bentoml-repo/
* Starting BentoML YataiService gRPC Server
* Debug mode: off
* Web UI: running on http://127.0.0.1:3000
* Running on 127.0.0.1:50051 (Press CTRL+C to quit)
* Usage: `bentoml config set yatai_service.url=127.0.0.1:50051`
* Help and instructions: https://docs.bentoml.org/en/latest/guides/yatai_service.html
* Web server log can be found here: /Users/chaoyu/bentoml/logs/yatai_web_server.log
部署YataiService服务器后,获取服务器IP地址并运行以下命令,将BentoML客户端配置为使用此远程YataiService进行模型管理和部署。您需要将127.0.0.1替换为您的团队可以访问的IP地址或URL:
bentoml config set yatai_service.url=127.0.0.1:50051
运行上述命令后,所有BentoML模型管理操作都将发送到远程服务器,包括保存BentoService、查询保存的BentoServices或创建模型服务部署。
注意:
BentoML的YataiService不提供任何身份验证。为了保护您的部署,我们建议您只允许您的数据科学团队访问VPC中的服务器。BentoML团队还为企业团队提供托管YataiService,该团队内置了所有在实践中的最安全的配置,以引导端到端模型管理和模型服务部署工作流。请与我们联系以了解有关我们产品的更多信息。