说明
500 lines or less 系列中A Web Crawler With asyncio Coroutines尝试翻译,不求信雅达,但求通俗易懂。
如有转载,请标明出处,并附原文地址。
如有侵犯原作者版权,请联系clark1013@hotmail.com。
原文地址如下,如有兴趣,可去此处探索。
http://aosabook.org/en/500L/a-web-crawler-with-asyncio-coroutines.html
概述
传统的计算机科学强调的是通过高效的算法来快速完成数据计算。但是许多网络应用程序最耗时的步骤却并非计算,而是接受了许多速度缓慢的连接或不常发生的时间。这些网络应用程序面对的挑战是:需要高效等待海量的网络事件。这个挑战的现代解决方案是异步I/O(asynchronous I/O,简写为“async”)。
本文构建了一个简单的网络爬虫。这个网络爬虫是典型的异步应用程序,因为它没有进行大量的计算,而是等待许多响应。这也意味着如果这个爬虫一次可以爬取越多网页,程序的运行时间也越短。如果采用多线程的方案,即为每一个正在进行的数据交换的请求开启一个线程,那么随着并发的请求数量的提升,在端口数量耗尽之前,计算机很快就会就会耗尽内存或耗尽其他与线程有关的资源。使用异步I/O就避免了使用线程会带来的问题。
我们将分三步来展示我们的示例。第一步,我们展示了一个异步事件循环,在这个异步事件循环的基础上,我们通过回调来初步构建了网络爬虫。这个爬虫很高效,但是随着问题复杂性的扩展,代码的扩展将会变成难以管理的意大利面式代码。第二步,我们展示了既高效又易于扩展的协程,这里的协程是通过python的生成器函数来实现的。第三步,我们用到了python的标准库中的“asyncio”库,并使用异步队列协调这些组建。
任务
网络爬虫的目的是查找并下载网络上的所有页面,并可能存储或为它们加上索引。网络爬虫从一个根URL开始,它获取每个页面,并解析这个页面中未能被爬取的页面,并将未被爬取的加入队列中。当从页面中无法解析到未被爬取的页面,且队列为空的时候,爬虫才会停止工作。
我们可以通过可以通过并行地下载许多页面来加快处理速度。每当爬虫找到新页面的时候,它会在另外的端口上同时开启一个抓取的操作。当得到响应的时候,爬虫将会解析页面,并将新的页面加入到队列中。爬虫的的返回可能会包含带来太高并发的结果,所以我们需要限制并发的请求量,并将多余的链接放在队列中,直到有正在执行的请求完成为止。
传统的解决方案
我们如何使得爬虫并行?传统的方式是创建一个线程池,每个线程在负责在某一段事件的某一个端口上进行页面的下载。例如,我们需要从xkcd.com下载一个页面:
def fetch(url):
sock = socket.socket()
socket.connect(("xkcd.com", 80))
request = "GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n".format(url)
sock.send(request.encode("ascii"))
response = b""
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
links = parse_links(response)
q.add(links)
套接字的操作默认是阻塞的:每当线程调用了connect或recv这样的方法,线程会暂时停止直到操作完成为止。所以如果想同时下载多个页面,我们也需要多个线程。更为成熟的应用程序会通过将空闲的线程置于线程池中,以此用来摊销创建线程所带来的成本,在随后的下载任务中,这些线程可以被复用。在连接池中,对于套接字也采取了同样的处理手段。
然而,线程会带来很大的系统开销,所以操作系统会强制给用户或机器可以的开启的线程数加上限制。再Jesse的系统中,一个Python线程的内存开销大概是50KB,开启10k个线程即会导致系统运行受到影响。如果我们再并行的套接字上同时开启10k量级的并发操作,在端口耗尽之前,系统的线程会先被耗尽。线程耗尽的形式可能是线程数量达到上限,或者是操作系统的线程数量限制成为瓶颈。
在Dan Kegel富有影响力的文章《The C10K problem》中,他指出了在I/O并发中多线程的限制。原文如下:
It's time for web servers to handle ten thousand clients simultaneously, don't you think? After all, the web is a big place now.
1999年,Kegel创造了"C10K"这个术语。从现在的计算机发展水平来看,10k量级的连接并不是大多数网络应用程序的瓶颈,但是这个问题仅仅是从并发规模上得到了改变,而非问题本身的类型。从那时的角度来看,10k量级的并发连接也是不可能发生的。现在这个问题也仅仅是量级变得更高而已。事实上,我们的玩具爬虫仅仅使用多线程也能工作地很好。但是对于大规模的应用程序来说,当并发数量达到100k量级的时候,瓶颈仍然是存在的:在大多数操作系统还能创建端口的时候,系统可以开启的线程数量先达到上限。那么我们如何克服这个问题呢?
异步
异步I/O框架通过使用非阻塞的套接字(non-blocking sockets)来在单线程上进行并行的操作。在我们的异步爬虫中,我们在套接字连接到服务器之前就将其设置为非阻塞的。
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(("xkcd.com", 80))
except BlockingIOError:
pass
诡异的是,一个非阻塞的套接字即使在正常工作的时候,也可能会突然抛出异常。这个诡异的行为来源于底层的C函数,这个函数会将errno设置成EINPROCESS来标识它已经开始工作。
现在我们的爬虫需要一种方式来获知连接是否已经建立,以便于其可以发送一条HTTP请求。我们可以简单地在一个死循环中不断尝试,就像下面地代码一样:
request = "GET {} HTTP/1.0\r\n Host: xkcd.com \r\n\r\n".format(url)
encoded = request.encode("ascii")
while True:
try:
sock.send(encoded)
break
except OSError as e:
pass
print("sent")
这样的实现方式不仅会带来巨大的资源浪费,而且不能有效的等待响应多个套接字上的事件。早期,BSD Unix 对于这个问题的解决方案是select。select是一个在一个或多个(小规模)套接字上等待时间发生的C函数。现在随着网络应用程序对于响应大规模的连接的需求,select已经逐渐被poll代替,更为先进的方式是BSD的kquene和Linux的epoll。这些API的功能与select类似,但是在大量连接的情况下比select表现更好。
Python3.4的DefaultSelector使用的是系统上性能最好的类似于select的函数。为了注册网络I/O的通知,我们先创建了非阻塞的套接字并使用default selector来进行注册。
from selectors import DefaultSelector, EVENT_WRITE
selector = DefaultSelector()
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(("xkcd.com", 80))
except BlockingIOError:
pass
def connected():
selector.unregister(sock.fileno())
print("connected")
sock.register(sock.fileno(), EVENT_WRITE, connected)
我们忽略了连接过程中产生的虚假异常,随后调用selector.register,并向其传递了套接字的文件描述符,另外传递了一个用以表达我们在等待何种类型的时间的常数。需要注意的是,当连接建立时,我们传递了EVENT_WRITE:这个常数意味着我们想要知道何时这个套接字是“可写”的。同时,我们也传递了一个Python函数connected,这个函数在事件发生的时候运行。也就是我们熟知的回调机制。
当selector接收到I/O通知地时候,我们在循环中处理这个通知:
def loop():
while True:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
connected回调被存储为event_key.data,一旦非阻塞地套接字连接一次,我们取回这个方法并执行一次。
与上面写的不断进行检查的循环不同,在这个方法中,我们通过调用select使循环暂停,并等待下一个I/O事件。随后循环调用了在等待这些事件的回调函数。未完成的操作会保持挂起的状态直到事件循环的接收到事件。
到目前为止,我们展示了什么呢?我们演示了当操作准备好的时候,我们如何开始一个操作并执行一个回调函数。一个异步框架建立在我们已经演示的两点特性之上:1.非阻塞的套接字和事件循环;2.在单线程上并行进行操作。
我们已经已经达成了“并发(concurrency)”,但却非传统意义上的“并行(parallelism)”,我们构建了一个可以进行重叠I/O的小系统,它可以发起新的操作即使其他的操作还未完成。但是它却未能有效利用多核进行并行计算。不过,我们的系统也是为了I/O边界问题而构建,而非CPU边界的问题。
所以我们的事件循环在并发I/O的场景下非常高效,因为它不需要为每个连接分配线程资源。但是在我们继续前进之前,需要纠正一个常见的错误认知,即异步比多线程更加快速。通常来说,情况正好相反,在Python中,像我们这样的系统在面对小规模、非常活跃的连接的时候比多线程表现更差。在没有全局解释锁的运行时环境中,多线程甚至可以表现地更棒。异步I/O真正可以发挥效用,通常是在面对哪些有许多缓慢连接或者不常发生地事件地情况下。
使用回调编程
仅仅依靠我们已经构建地粗糙地异步框架,我们就可以构建网络爬虫了吗?事实上,即使一个简单地URL获取器就很难编写。
我们从全局的集合开始我们的爬虫。集合分为两个,一个用来存储我们已经爬取过的URL,一个用来存储待爬取的URL。
urls_todo = set(["/"])
urls_seen = set(["/"])
urls_seen集合包含了urls_todo加上已经爬取完成的URL。两个集合都使用根URL"/"来进行初始化。
获取一个页面需要一系列的回调。之前已经写过的connected回调负责在套接字建立连接后向服务器发送一个GET请求。但是请求发送后,系统必须要等待并读取响应内容,所以connected函数需要注册另外一个回调函数。如果在响应读取的函数过程中,未能读取到全部响应,那么它会再次被注册。
我们可以使用一个Fetcher对象。它需要一个URL,一个套接字对象,和一段用来收集响应内容的空间。
class Fetcher:
def __init__(self, url):
self.url = url
self.response = b""
self.sock = None
我们通过调用Fetcher.fetch来开始我们的方法。
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False)
try:
self.socket.connected(HOST_TUPLE)
except BlockingIOError:
pass
# register next callback.
selector.register(self.sock.fileno(),
EVENT_WRITE,
self.connected)
fetch方法开启一个套接字发起连接。并在连接建立之前注册了方法的返回值。这个方法必须重新控制事件循环以等待连接。要理解其原因,假想我们的整个应用的结构如下:
fetcher = Fetcher("/353/")
fetcher.fetch()
while True:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback(event_key, event_mask)
所有的事件通知都在事件循环调用select的时候处理。因此fetch必须将控制权交给事件循环,这样程序才能直到什么时候套接字建立起了连接。只有当套接字建立起连接后循环才会调用connected回调,这个回调是在fetch的结尾被注册的。
connected的实现如下:
def connected(self, key, mask):
print("connected")
selector.unregister(key.fd)
request = "GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n".format(self.url)
self.sock.send(request.encode("ascii"))
# register next callback.
selector.register(key.fd,
EVENT_READ,
self.read_response)
这个方法发送了一个GET请求。真实的应用会检查send的返回值,以防整个消息不能一次被发送。不过我们只是构建一个小应用用于演示。所以只是简单地调用了send,然后等待响应。当然,send方法也必须注册另一个回调并移交事件循环地控制权。下一个,也是最后一个回调,read_response,处理服务器的回复。
每当selector发现套接字是“可读的”的时候,回调会被执行。可能会有两种情况,套接字有数据或套接字被关闭。
回调函数从套接字每次请求4KB的数据。如果有效的响应数据少于4KB,chunk包含了所有的的有效数据。如果有效响应数据大于4KB,chunk会取出正好4KB的数据,套接字仍然是可读的,回调函数会再次被调用。当响应完成时,服务器会将套接字关闭,chunk也会被清空。
parse_link方法,并未在这里展示,它的返回值是一个URL的集合。我们会为每个新的开启一个新的fetcher,不限制并发量。值得一提的是,异步编程的一个良好的特性是:当我们改变共享数据的时候,不需要加互斥锁,例如,当我们向urls_seen中添加链接的时候。由于不存在抢占式的多线程,所以在程序执行的任意点,都不需要被打断。
我们添加了一个全局变量stopped,并用来控制整个循环。
stopped = False
def loop():
while not stopped:
events = selector.select()
for event_key, event_mask in events:
callback = event_key.data
callback()
一旦所有页面下载完成,fetcher会停止全局事件循环,整个程序也会退出。
这个示例展示了异步程序的一个痛点:意大利面条式代码。我们需要某种方式来表达一系列的计算和I/O操作,并需要规划这一系列操作的并行运行方式。但是由于没有多线程,这一系列的操作无法被收集到单个函数中,每当一个函数开启一项I/O操作,它将直接保存将来的状态并返回。而你需要负责的是编写这些状态保存的代码。
如何理解这个痛点。我们可以考虑一下通过线程的方式加上传统的阻塞套接字来获取一个页面的方式:
def fetch(url):
""" traditional approch, use multi-threading and blocking socket """
sock = socket.socket()
sock.connect(("xkcd.com", 80))
request = "GET {} HTTP/1.0\r\nHost: xkcd.com\r\n\r\n".format(url)
sock.send(request.encode("ascii"))
response = b""
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
links = parse_links(response)
q.add(links)
考虑一个问题,这个函数在一个套接字操作和下一个之间记住了什么?看起来,一个套接字,一个URL,以及一个不断累加的response结果都被程序记住了。运行在线程上的函数使用到了编程语言的一个基本特性,将临时状态存储在临时变量中,而临时变量存储在栈区。这个函数的内部是有“后续操作(continuation)”的,即在I/O完成后进行的一系列操作。运行时环境通过存储线程的指令指针来保存后续的操作。你不需要考虑如何保存这些临时变量和后续操作。这都是由编程需要帮你做好的。
但是在基于回调的异步框架中,这些语言特性都没有用了。在等待I/O操作的过程中,一个函数必须手动保存它的状态,因为在I/O完成前,一个函数就返回并丢失它的栈帧。为了替代临时变量,我们的异步示例存储sock和response作为Fetcher实例的一个属性。为了替代指令指针,我们通过注册connected和read_response的回调来存贮后续操作。但是当应用层序的规模增长的时候,这样通过手工回调的方式来存储状态的方式其复杂程度也会增加。而大规模的记录状态也会让代码编写者头大。
更坏的一点是,如果在注册下一个回调之前当前的回调抛出了异常会发生什么?假设我们的parse_link方法中有BUG,在解析HTML的时候抛出了异常。
Traceback (most recent call last):
File ".\crawler.py", line 145, in
loop()
File ".\crawler.py", line 141, in loop
callback(event_key, event_mask)
File ".\crawler.py", line 116, in read_response
links = self.parse_links()
File ".\crawler.py", line 130, in parse_links
raise Exception("parse Exception")
Exception: parse Exception
栈的轨迹跟踪仅仅显示了时间循环在运行回调。但是我们不知道到底是什么导致了这个异常。程序链在两个末端都断了:我们忘了我们将要去哪里,也不知道我们从哪里来。这种内容的丢失被称为“栈撕裂(stack ripping)”,而这导致了问题分析的困难。栈撕裂也阻止了我们在回调链中的异常处理,通常采用的方法是在一个函数及其树节点上包裹"try/ except"语句。
所以,尽管一直以来都有对于多线程和异步的效率的争论。在在此问题之外,对于出现问题后的处理也是存在争论的:多线程,如果在同步数据的时候出现问题,通常对于数据间的竞态条件更加敏感;异步,由于栈撕裂的存在,通常来说更加难于调试。
协程
不过也可以告诉大家一个好消息,异步代码想要结合回调的效率和多线程的美观是可能的。这个结合通过一个叫做“协程(coroutines)”的模式来实现。通过使用python3.4中的标准异步I/O库——aiohttp,在协程中获取一个页面是非常直观的。
@asyncio.coroutine
def fetch(self, url):
response = yield from self.session.get(url)
body = yield from response.read()
同样的,这段代码也是可伸缩的,就如同前面提到的,一个线程占用50k内存,而一个协程的内存占用仅仅3k,所以开100k这个量级的协程也就不会带来内存支持不上的问题。
协程的概念来自于早期的计算机科学,其本质是一段可以被暂停或者恢复。与操作系统控制的抢占式的多任务不同,协程协作式的完成多任务,它们可以一个协程何时暂停,以及接下来执行哪个协程。
协程有很多种实现方式,即使在python中就有好几种。"asyncio"标准库中的协程在python3.4中通过生成器,期物和"yield from"表达式来实现。而在python3.5中,协程已经成为了语言本身的特性。但是,理解协程在python3.4中的实现方式(使用预存在的语言工具),是理解python3.5的协程的基础。
接下来的部分将会演示生成器的机理和它如何被用作协程的。
Python 生成器的工作原理
在掌握python生成器的原理之前,你必须理解一个普通的python函数的工作机理。通常来说,当python函数调用子程序的时候,在子程序执行过程中或获得进程的控制权,直到子程序返回或者抛出异常,之后的控制权会回到调用端。
>>> def foo():
... bar()
...
>>> def bar():
... pass
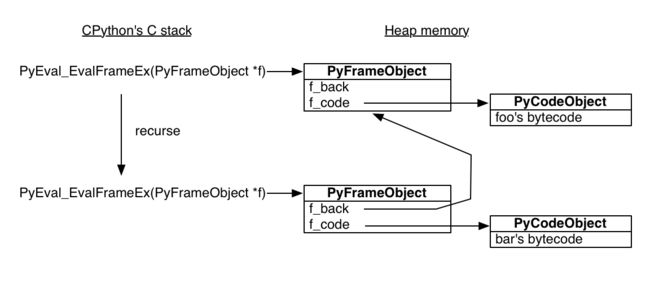
python的标准解释器是用C语言编写的。用来执行python函数的C函数被称作PyEval_EvalFrameEx。它消耗一个python的栈帧对象来在栈帧的内容上计算python的字节码。以下是foo函数的字节码。
>>> dis.dis(foo)
2 0 LOAD_GLOBAL 0 (bar)
3 CALL_FUNCTION 0 (0 positional, 0 keyword pair)
6 POP_TOP
7 LOAD_CONST 0 (None)
10 RETURN_VALUE
foo函数将bar函数加载到其栈上进行调用随后从出栈其返回值,将None加载到栈上并返回None。
当PyEval_EvalFrameEx遇到CALL_FUNCTION字节码的时候,它会创建一个新的python栈帧并递归:这意味着,他将会使用这个新的栈帧来递归调用PyEval_EvalFrameEx,这个栈帧将会被用来执行bar函数。
理解python的栈帧是在堆区(用户空间)被分配的是非常重要的。python解释器是一个普通的C程序,所以它的栈帧是普通的栈帧。但是python的栈帧是在堆区被分配的。这也就意味着,python的栈帧是可以存活在函数调用以外的。为了交互式的看这个说法,在栈帧调用的时候用一个全局变量指向这个栈帧。
>>> import inspect
>>> frame = None
>>> def foo():
... bar()
...
>>> def bar():
... global frame
... frame = inspect.currentframe()
...
>>> foo()
>>> frame.f_code.co_name
'bar'
>>> caller_frame = frame.f_back
>>> caller_frame.f_code.co_name
'foo'
生成器的内部实现与函数实现的内部有相似的地方:一个Code对象和一个栈帧。
生成器如下:
>>> def gen_fn():
... result = yield 1
... print("result of yield: {}".format(result))
... result2 = yield 2
... print("result of 2nd yield: {}".format(result2))
... return "done"
...
当python将gen_fn编译成字节码的时候,它看到了yield表达式就知道gen_fn是一个生成器函数,然后会设置一个flag来记住这个事实(实现方式是将gen_fn.__code__.co_flags左移5位)。
到我们调用生成器函数的时候,python看到生成器flag,就不会实际执行这个函数,还是创建一个生成器对象。
>>> gen = gen_fn()
>>> gen
python的生成器封装了一个栈帧加上对于一些代码的引用,这些代码的主体如下:
>>> gen.gi_code.co_name
'gen_fn'
所有的生成器的调用都指向了同一段代码。但是每个调用都有自己的栈帧,这个栈帧不是真实的栈,而是位于堆区等待被使用。
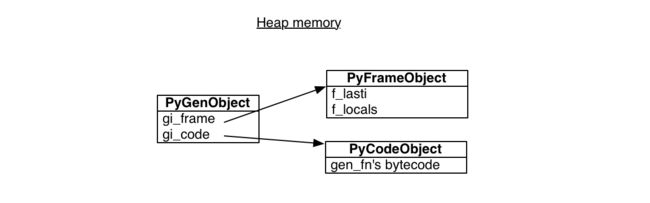
这个栈帧对象有一个"last instruction"指针,存储了最近被执行的操作。一开始,最后的指针是-1,意味着生成器还没有开始。
>>> gen.gi_frame.f_lasti
-1
当调用send方法的时候,生成器执行到第一个yield表达式然后暂停。send方法的返回值是-1,这个值是生成器gen传递给yield表达式的。
>>> gen.send(None)
1
生成器的操作指针现在已经从开始位置0到达了3个字节码。而编译的python的字节码长度到了56。
>>> gen.gi_frame.f_lasti
3
>>> len(gen.gi_code.co_code)
56
生成器在任意时刻都可以从任意函数中被恢复。因为其栈帧并不再栈区,而是在堆区。它在调用层级中的为止还未恢复,它不需要像大部分的函数调用一样遵循先进后出的执行顺序。
我们可以向生成器发送"hello",它会变成yield表达式的结果,生成器会继续继续执行到生成2这一句。
>>> gen.send("hello")
result of yield: hello
2
现在生成器的栈帧会包含本地变量result:
>>> gen.gi_frame.f_locals
{'result': 'hello'}
其他从gen_fn创建的生成器会有它们自己的栈帧和本地变量。
当我们再次调用send方法的时候,生成器从它的第二个yield表达式出发继续执行,并通过抛出一个特殊的StopIteration异常来结束。
>>> gen.send("good bye")
result of 2nd yield: good bye
Traceback (most recent call last):
File "", line 1, in
StopIteration: done
这个异常有一个值,这也是生成器的返回值:字符串"done"。
通过生成器构建协程
所以一个生成器可以暂停,可以通过一个值继续执行,而且它有返回值。这些让生成器成为构建一个异步编程模型的绝佳选择,再也不需要意大利面式的回调。我们想要构建协程(coroutine)——一段可以在项目中与其他程序在执行计划上协同的程序。我们的协程是python标准库中asyncio的简化版本。在asyncio中,我们会使用生成器,期物和"yield from"表达式。
首先我们需要一种方式来代表将来将会获得结果(期物"future"),这个结果也是协程正在等待的。精简版如下:
class Future:
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self = result
for fn in self._callbacks:
fn(self)
让我们通过期物和协程来更新我们的Fetcher类。
期物在刚被创建的时候处于被挂起(pending)的状态,到调用set_result方法后,其状态转变成已确定("resolved")。
在之前我们通过回调的方式实现异步,fetch方法开始于连接一个套接字,然后注册回调connected,这个回调会在套接字准备好了以后执行。现在我们可以将这两步合并到一个协程之中。
def fetch(self):
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(HOST_TUPLE)
except BlockingIOError:
pass
f = Future()
def on_connected():
f.set_result(None)
selector.register(sock.fileno(),
EVENT_WRITE,
on_connected)
yield f
selector.unregister(sock.fileno())
print(connected)
现在fetch是一个生成器函数,而非一个常规函数,因为函数体中包含了yield表达式。我们创建一个挂起的期物,然后通过yield表达式使fetch方法暂停直到套接字准备好。内部函数on_connected用来确定期物。
但是当期物确定以后,依靠什么来重新激活生成器呢?我们需要一个协程驱动——以"task"命名。
class Task:
""" 驱动协程 """
def __init__(self, coro):
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
next_future = self.coro.send(future.result)
except StopIteration:
return
next_future.add_done_callback(self.step)
任务调度对象Task通过发送None给fetch生成器来激活它。然后fetch开始运行直到它产出期物,Task接收这个期物作为next_future。当套接字连接以后,事件循环调用回调函数on_connected,这个回调函数负责解析期物,调用step,恢复fetch。