Java集合ArrayList和HashMap源码学习
Java集合框架
Java集合类主要由两个接口派生出来的:Collection和Map。
各集合接口主要实现子类
备注:jdk1.7_75
List集合
ArrayList实现原理
基础数据结构:对象引用数组
![]()
默认大小:10,
![]()
每次扩展的大小:当前容量的1.5倍(左移一位实现),如果容量还不够,则直接扩展到所需大小。
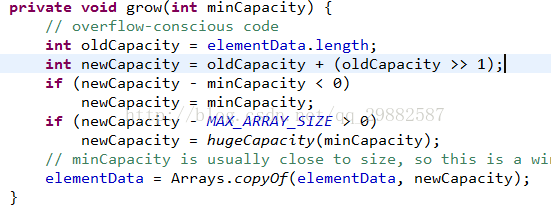
Add函数实现:

如果index超过当前大小(不是容量),则抛出异常。确保容量足够,把index之后的元素整体拷贝到index+1之后的位置,最后在index放置element。
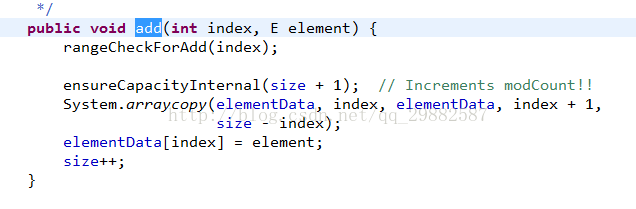

Set方法:直接替换原数组的值。返回旧值。
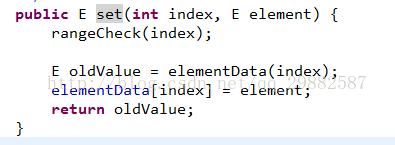
Remove(int)方法:同样使用数组拷贝。最后一个元素移除时不会进行拷贝。缩小数组大小 (size-1)=null

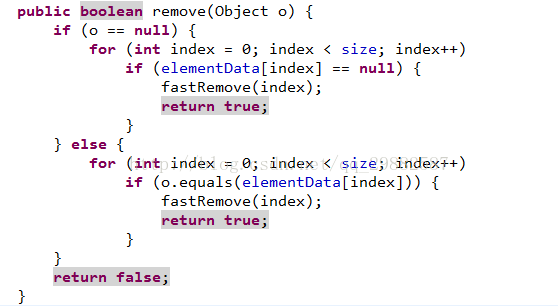
Remove(Object)方法:对象==null时移除数组中为null的元素,不为null时采用equals比较,通过时移除。
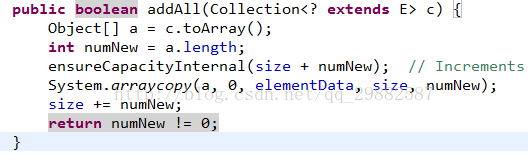
AddAll(Collection)方法:数组拷贝。
Contains方法,indexOf方法:遍历查找。

优点:查询快,增删慢。
Map集合
HashMap实现原理
基础数据结构:数组-链表(Entry作为链表结点)
![]()
1.HashMap将键值对封装成一个JavaBean,把Entry对象存在数组中,存放的位置由key的hashcode和数组长度的取模,代码如下

默认数组大小:16
![]()
默认负载因子:0.75
桶数组扩容大小:2(不能修改,跟Map的扩容优化有关)。
Put方法:代码如下。

解析:
代码487-489行:如果table为空,则进行初始化,threshold是当前的数组大小。
代码490-491行:key为空时,则进行添加nullkey的键值对。下面会在进行解析。
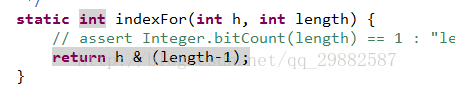
代码492-493行:根据key的hashcode计算此键值对在数组中的位置。
代码494-502行:遍历i对应的Entry链表,替换掉与当前key的hash值并且key值的引用也相同的Entry,比较引用时会使用==和equals比较,成立一个即可。
代码494-502行:如果没有重复的,则执行添加函数。
PutForNullKey方法:添加key为null的Entry,放到数组第1位.

AddEntry方法:

解析:如果当前Entry的个数(size)大于阈值(threshold)并且桶数组(table)中bucketIndex位置上的元素不为空时,进行扩容操作,扩容大小为原先的2倍。
如果不需要扩容,则在bucket位置上创建一个Entry,放到链表首部。

Map扩容机制
扩容时机:当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值---即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
参考博客:http://blog.csdn.net/aichuanwendang/article/details/53317351
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
Resize方法:

解析:使用新的容量值创建数组,在将数据转移到新数组中去。最后更新索引值,修正阈值(threshold)新阈值为新容量*负载因子和最大容量+1的最小值。
Transfer方法:

解析:遍历旧数组,重新计算hash值,再根据hash值放置Entry的位置。JDK1.8对此有优化(不需要重新计算hash值)。
Get方法:

如果可以为空则直接从table[0]中查找。不为空根据hash值查找Entry在桶数组中的位置,在遍历链表查找key的hash值相同并且引用比较也相同的Entry。引用比较也采用==和equals。
代码如下:

总结:
l Map的基础数据结构为Entry数组-链表,
l 增加Entry的方式步骤
1. 根据key的hash值计算Entry所在桶数组的位置(bucketIndex)
2. 在根据bucketIndex找到链表,遍历链表检查是否由重复值。
3. 检查是否需要扩容,如果需要则进行扩容
4. 将Entry插入到链表的头部。
l 插入Entry的过程即用到了hash比对也用到了引用比对(==和equals)
l 查找过程步骤如下
1. 如果为空,在table[0]中查找
2. 根据key的hash值计算Entry所在桶数组的位置(bucketIndex)
3. 遍历链表根据key的hash和引用比对(==和equals)找到Entry