Java集合在某种程度上可以说是对一些数据结构与算法的封装,并给出相应的接口,这充分的体现了面向对象编程的思想。
Java中集合的结构大概如下图所示:
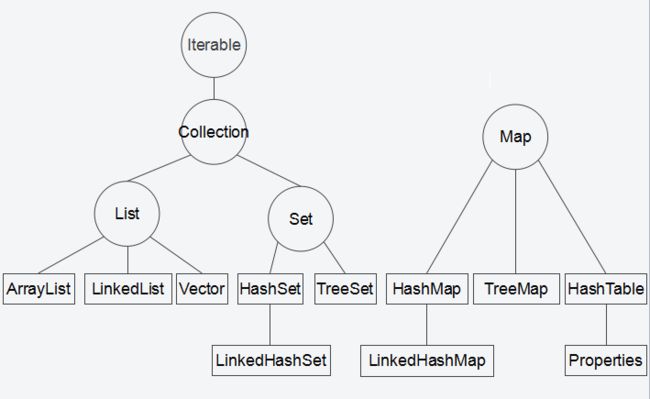
1.Iterable和Iterator
java.lang.Iterable
java.util.Iterator
通过它们两在java中的位置可以看错Iterable是属于基础类的一份子,而Iterator是在集合类当中。Iterator是迭代器类,而Iterable是接口,因为Iterable中封装了Iterator接口,只要实现了Iterable接口的类,就可以使用Iterator迭代器了。因此List和Set位于Iterable下就不难理解了。
2.List
List中用的最多的为ArrayList和LinkedList,这两个相当于数组和链表的形式,ArrayList是连续存储,LinkList是分散存储,我们可以自己动手写来模拟这种存储方式,而他们的优缺点也和数组链表的优缺点大致相同,不再陈述。
MyArrayList,MyLinkedList
而Java作为面向对象语音,也为我们封装了很多方法,以便于对List进行操作:
int size() :获得数据个数
boolean contains(Object o) :是否包含数据o
int indexOf(Object o) :返回元素o第一次出现的位置
Object[] toArray(): 转换成长度固定的数组
get(int index) :返回第index个元素
add(E e):向最后添加元素。数据可以重复
add(int index, E element):某个位置之后添加元素
remove(int index):删除一个位置的元素
remove(Object o):删除元素o
void clear():清空
3.Set
Set,类似于数学中的集合,他存储的元素是不重复的,Set中的数据都是只有一份,并且Set中的数据不是以键值对存储的,以下是Set中一些常用的方法:
boolean contains(Object o):判断是否存在元素o
add(E e) :添加元素到集合
remove(Object o) :从集合移除
int size() :获取个数
boolean isEmpty():是否空
void clear() :清空
4.Map
首先实现了Map接口的类的数据的存储都是以键值对的形式来进行存储的,而在实际中用的最多的就是HashMap,要了解什么是HashMap,要先了解什么是哈希算法。简单来说,哈希算法就是根据一定的规则,计算一个数据应该放到哪个地址,因此,就有一定的几率使得两个完全不同的数据计算得到的地址是一样的,而一个好的哈希算法是使这种情况发生的几率最小。
HashMap中数据进行存储时键不能重复,但值可以重复,这就造成了数据的存储略慢,但是查询速度快,理论上来讲查询速度和数据量无关。正所谓鱼与熊掌不可兼得,编程也是这样的,同样只要了解其基本原理,在某种程度上就可以说已经学会了HashMap,这得力于Java中封装的大量方法:
int size() :键值对条数
V get(Object key) :根据键获得值。如果不存在这样的键则返回null
boolean containsKey(Object key) :判断键是否存在
put(K key, V value) :键值对放入map。如果已经key已经存在则用新的键值对替换旧的键值对,也就是“键不能重复”
remove(Object key):根据键移除键值对
void clear() :清空
Set keySet() :得到所有的key,返回值是Set类型。
5.泛型
泛型,简单来讲,就是人为规定了参数的标准,或者类型,除了我规定的类型外都不可以传进来,Java中除了集合可以使用外我们也可以自己定义泛型,方法也很简单:在类名后面用<>声明类型的“代替符号”,然后类中需要用这个类型的地方用这个名字就行。
泛型不能使用int、double、boolean等原始类型,而应使用比如Integer、Double、Boolean等包装类型,怎样去判断一个类型是基本类型还是包装类型呢:首字母大写是包装类型,小写为基本类型。这也解释了Java中String为什么有那么多的方法,因为“他的首字母是大写的”。当然用的时候是可以使用原始类型,因为有拆箱装箱。
Java数组支持协变,什么是协变呢,简单说就是父类相关的变量可以指向子类相关的对象,但泛型是不支持协变。
ArrayList list1 = new ArrayList
ArrayList list1 = new ArrayList
() ; ArrayList
list2 = new ArrayList(); ArrayList list3
= new ArrayList ();
泛型擦除是java文件编译为class文件是做的鬼,如果将class文件反编译为java文件,那么,上面三条语句会变成这样:
ArrayList list1 = new ArrayList() ;
ArrayList
list2 = new ArrayList(); ArrayList list3
= new ArrayList();
正向编译时,会自动去除后面的
用泛型集合编写代码的时候可以避免放入数据类型错误,并且取数据的时候避免类型转换。当然,泛型也有不好的地方:
1、运行时无法得知对象的泛型类型信息。比如无法用arr instanceof LinkedList判断
2、一旦转换为非泛型变量,那么就有放入非法数据的可能性。没有根除的办法。
3、不同类型的泛型不能构成重载方法。例如:
static void m1(LinkedList
list) static void m1(LinkedList
list) static void m1(LinkedList list)
上面三种方法是不能构成重载方法的。
5-1.有界类型
有界类型是指,在指定一个类型参数时,可以指定一个上界,声明所有的实际类型都必须是这个超类的直接或间接子类,比如:
class className
6.其它总结
Stack(栈):先入后出。push放入数据,pop取出数据
Queue(队列):先入先出。offer入队,poll出队
Vector、Hashtable被废弃,不推荐使用。