tags:
- python
- flask
计算机体系
艾兰•图灵(Turing)❤ &冯•诺依曼(Neumann)
艾兰•图灵(Turing):图灵机,密码
冯•诺依曼(Neumann):二进制
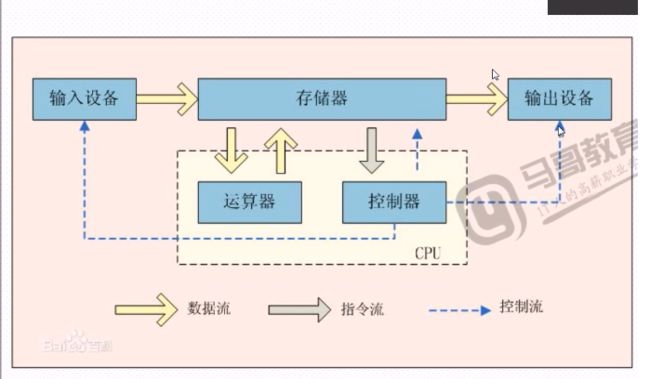
冯•诺依曼体系(体系架构)
CPU 运算器+控制器(中央处理器)
运算器:算术运算、逻辑运算、数据传输
控制器:控制程序执行
读取——
存储器:记忆程序、数据,例如内存(掉电易失,速度快)
输入设备:将数据输入到计算机中,例如键盘、鼠标
输出设备:将数据或程序处理结果展示给用户,列入显示器、打印机
cpu中还有寄存器和多级缓存Cache
寄存器:cpu对寄存器数据处理再存储到内存,速度:寄存器>内存>io
寄存器(小,也在cpu里)---缓存(大一点里,放在cpu)---内存(比cpu慢n万倍,不在cpu中)【全都掉电遗失】----
一级缓存→二级缓存:独享
三级缓存:控制器电信号送到内存,多cpu共享
都快于内存,
磁盘仅仅是“永久化”存储工具(掉电不失)
面向机器的语言(低级语言)
计算机语言--机器语言--汇编语言
高级语言
更加接近人类自然语言和数学语言
低级语言对机器友好
C、C++等语言的源代码需要本地编译,兼容指令集86速度一般
Java、Python、C#的源代码需要被解释器编译成中间代码(Bytecode)*(编译成虚拟机认得的字节码),在虚拟机(由他来转换成物理机可识别的机器代码)上运行,一次编译到处执行,跨平台
编译型语言:把源代码转换成目标机器的cpu指令
解释型语言:解释后转换成字节码,运行在虚拟机上,解释器执行中间代码
互联网
计算机网络体系:层次&协议
n层是n-1层的用户,又是n+1层的服务提供者
应用层<处理PC上的应用进程,http,ftp,是传输层的一个封装>
表示层<类似于完成跨平台(主机到PC机)的一些解码,关心的是传输信息的语法(数据的表示形式)和语义(数据的含义)>
会话层<(进程到进程)令牌管理,持有令牌的进行活动>
传输层<(主机到主机)TCP/IP传输规则:超麻烦的我也没怎么看懂,大底是在上三层和下三层之间传输数据段(segment),几个概念没啥概念,比如“端到端”“开放端系统”“多路复用”“多个逻辑连接”“网络分流”“吞吐量”>
网络层
数据链路层<网络结构,链路结构、数据通道,建立一条线路,确保物理层传输的比特流(0/1)无差错地递交到对方。 >
物理层<同轴电缆线:硬件设备约定-协议:RJ45协议,通信介质要提供足够带宽,减少信道上的堵塞>
各种操作遵循各自协议,发邮件,收邮件,网络访问,不啦不啦
*三引号中间加引号计入字符串,比如直接打换行
*r:不转义了
*用锁紧表示层次关系,四个空格一缩进
*标识符默认不用歧义单词、大小写敏感、字母下划线数字、不用下划线开头(python下划线开头有默认含义)
*python中没有定义常量的方式,但有字面常量存储在内存中
语言类型

动态语言 变量类型可以随便变(可能和设计者期望的数据类型不一致)
静态语言 声明变量
强类型语言不同类型之间进行操作,必须先强制类型转换
弱类型语言自己转换为同类型语言(但是转换之间的规则可能和设计者意思不一样)
运算符
python3 a/b=小数 a//b=整数(强行取整)
内存管理
垃圾回收:不用了打个标记标记是垃圾,设定一个标准(比如到达内存的百分之九十时),进行垃圾回收
引用计数
python数据结构
字符串
布尔
List
Dict
Tuple
算法
有个函数可以在平时测试自己的程序简洁度
import datetime
start=datetime.datetime.now()#开头
delta=(datetime.datetime.now()-start).total_seconds()#结尾
print (delta)
**可以根据经验记录一些跑的比较慢的函数
九九乘法表
for i in range(1,10):
s=''
for j in range(1,i+1):
s+=str(j)+'*'+str(i)+'='+str(j*i)+' ' #这里是做完一整行的乘法表形成字符串在打印
print(s)
print方法中默认会换一行,默认分隔符是空格
如果不限那个换行,可以:
print(q,e,sep='',end=' ')#这样结束就不换行,分隔符就是无
for i in range(1,10):
for j in range(1,i+1):
print(str(j)+'*'+str(i)+'='+str(j*i)+' ',end=' ')
print()
格式化字符串 format函数:string.format(value)---value对应{},默认依次对应,也可以加索引对应自定义顺序
\t 和' '的空格优点区别,可以在实际中体会一下
for i in range(1,10):
for j in range(1,i+1):
print('{}*{}={}\t'.format(j, i, j * i), end="")
print()
print('{0}*{1}={2:<2}'.format(j, i, j * i), end="\t",sep='')
:是分隔符,箭头方向朝左是左对齐,朝右是右对齐

for i in range(1,10):
for j in range(1,i+1):
print(''' \t''', end="")
for j in range(i,10):
print('{}*{}={}\t'.format(i, j, j * i), end="")
print()
or
for i in range(1,10):
s=' '
for j in range(i,10):
v = ' '
if ((i==1 and j>3) or(i==2 and j==4)):
v=' '
s+='''{}*{}={}{}'''.format(i, j, j * i,v)
print('{:>100}\t'.format(s))
菱形
for i in range(1,5):
for j in range(1,5-i):
print(' ',end='')
for j in range(1,2*i):
print('*',end='')
print()
for i in range(1,4):
for j in range(1,i+1):
print(' ', end='')
for j in range(1, 8-2 * i):
print('*', end='')
print()
python默认的除法是带小数的,注意一下,保留整数部分用//,取模用%
更简洁的思路
line=int(input(">>>"))
for i in range(-line//2,line//2+1):
for j in range(1,abs(i)+1):
print(' ',end='')
for j in range(1, line-2*abs(i)+1):
print('*', end='')
print()
再简洁一点:
line=int(input(">>>"))
for i in range(-line//2,line//2+1):
print(' '*abs(i),end='')
print('*'*(line-2*abs(i)))
斐波那契数列
F(n)=F(n-1)+F(n-2) (n属于自然数)
F(0)=0,F(1)=1
打印100个
f0=0
f2=1
for n in range(1,100):
fn=f1+f0
print(fn)
f0=f1
f1=fn
交换:a,b = b,a+b #1.a=b;2.b=a+b(等号右边分别算好,对应左边,元祖)
f1=0
f2=1
for count in range(99):
print(f1)
f1,f2=f2,f1+f2
素数
import math
def isPrime(num):
temp=int(math.sqrt(num))
for i in range(2,temp+1):
if num%i==0:
return 0
return 1
i=3
while(i<101):
if isPrime(i):
print (i)
i+=2
"""
num=int(input(">>>"))
if isPrime(num):
print (u"是素数")
else:
print("不是素数")
"""
乘法表进阶
for i in range(1,10):
s=''
for j in range(1,10):
s+"{}*{}={:<{}}".format(j,i,2 if j<4 else 3)
print("{:>80}".format(s))
猴子偷桃
猴子摘下若干桃子,每天吃一半+1颗,第十天想吃时只剩下1颗,求第一天一共摘了多少颗桃子?
n=int(input('>>>'))
a=1
for i in range(1,n):
a=2*a+1
print('The monkey stole {} peaches'.format(a))
模块
虚拟机
一个是安装了docker,还不是很理解这个应用(具体是官网+百度步骤)
1.一个是cmd环境下‘pip install virtualenv’指令,出现好看的进度条直到安装完成
2.mkdir Virtualenv(mkdir:创建目录)
3.cd Virtualenv(cd:命令cmd打开文件夹)
4.virtualenv flask-env
5.cd flask-env
6.dir
7.cd Scripts
8.dir
9.activate(此时激活成功,进入了这个虚拟环境,’deactivate'离开此虚拟环境)
flask的安装
pip安装flask,进入虚拟机activate模式
1.pip install flask(之后安装各种包都可以用pip install 包名,这样的指令)
2.python(进入python命令行)
3.import flask
4.flask.version
5.exit() (退出python脚本)
web基础
url详解
组成:scheme://host:port/path/?query-string-***#anchor
scheme代表访问的协议,一般为http或者ttp等
host主机名,域名
port端口号。如:
http:80端口
https:443端口
path查找路径
query-string查询字符串
www.baidu.com/s?wd=cmd%20&rsv_spt=1&rsv_iqid=0x8816e3f7000156b1&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=0&oq=cmd%2520%25E4%25B8%25AD%2520yes&rsv_t=e384akCn7G6jd8a0yEhy3T9qzkXMmv2LrBc%2Bkj1jmf6eFFHs3PUHFWzfzNfO2lPaFx2A&rsv_pq=e3b2831b0001b808&inputT=1797&rsv_sug3=59&rsv_sug1=53&rsv_sug7=100&rsv_sug4=2617&rsv_sug=2
_?wd=不啦不啦 就是查询字符串_
anchor 锚点,后台一般不用管,前段用来做页面定位的
baike.baidu.com/item/%E5%88%98%E5%BE%B7%E5%8D%8E/114923?fr=aladdin
页面内跳转->
baidu.com/item/%E5%88%98%E5%BE%B7%E5%8D%8E/114923?fr=aladdin#2
#2这里就是锚点
web服务器

web服务器:负责处理http请求,相应静态文件(图片、css文件……),常见的有apache、Nginx、IIS
应用服务器:负责处理逻辑的服务器,如python、php代码不能直接通过web服务器处理,只能通过因那个用服务器来处理,常见的有 vwsgl、tomcat等等
web应用框架:一般用某种语言,封装了常用的web功能的框架就是web应用框架,flask、Django、java中的SSH
要讨论应用层和传输层
框架
framwork,现成可用的代码包,提供不同类型网站框架
比如以内容呈现为主、电商(订单管理,订单流程)、app(数据接口,让app调用)
python常见框架:
Full-Stack Framworks
Django、Web2by、TurboGears、Pylons
Non Full-Stack Framworks
Tornado、Flask、Bottle、web.by、Pyramid
https://trypyramid.com/)https://wiki.python.org/moin/WebFrameworks
根据项目需求选择框架
flask
flask基础
url与视图
1.创建项目添加flask虚拟环境,选择到python执行文件
2.flask程序代码的详细解释
3.设置debug模式 新版本下debug=True代码无效,要通过编译器自己设置
*出错位置
*只要修改了项目中的‘python文件,程序会自动加载,不需要手动设置
4.使用配置文件
*建立一个config文件
import config #建一个config文件放所有的配置文件
app.config.from_object(config)
*还有许多其他参数,如’SECRET_KEY'和‘SQLALCHEMY’等配置
5.url传参
*参数的作用:可以在相同的url,指定不同的参数来加载数据
*flask中使用方式
@app.route('/article/')
def article(id)
return u'您请求的参数是:%s'%id
"""
*参数需要放在尖括号中
*视图函数中需要放和url中的参数同名的参数
"""
6.url反转
from flask import Flask,url_for
函数下:
print url_for('aeticle',id='abc')
"""
*在页面重定向时,会使用url反转
*在模板中会使用url反转
7.页内跳转和重定向
from flask import Flask,redirect,url_for #导入包
app = Flask(__name__)
@app.route('/')
def hello_world():
list_url = url_for('list')
return redirect(list_url) #重定向到另一个页面
return 'Hello World!alexaddsaa'
@app.route('/list/')
def list():
return u'你好'
if __name__ == '__main__':
app.run()
jinja2模板
模板渲染和参数传递
渲染模板
1.模板放于‘template’文件夹下
2.从‘flask’中导入‘render_templete’函数
3.在视图函数中,使用‘render_templiate'函数,渲染模板。只需要填写模板名字,不需要填写template文件夹路径;默认从template文件夹下开始查找,如果html文件建在其下文件夹下,则需要添加template之后的路径
模板参数
1.少量参数,直接在render_template函数中添加
2.多个参数,先防御字典,再通过’**字典名‘传参
3.在模板中使用变量,语法:’{{params}}
4.访问模型中的属性或是字典,可以通过‘{{params.property}}’的形式,或者‘{{params['属性内容']}}’
def index():
class Person(object):
name=u'小姐姐'
age=18
P=Person()
context={
'username':'jubi',
'gender':u'女',
'age':18,
'person':P
}
return render_template('index.html',**context)
html通过{{参数名}}传参
here html
用户名:{{ username }}
性别:{{ gender }}
性别:{{ age}}
管理员:{{ person.name }}
管理员:{{ person.age }}
if判断语句
{%if***%}
{%else%}
{%endif%}
for循环语句
1.字典(列表)的便利,可以使用字典(列表)函数,如:'items()'、'keys()'、'values()'、‘iteritems()’、‘iterkeys’、‘itervalues()’
{%for x,y in user.items()%}
{{x}}:{{y}}
{%endfor%}
实例
书名
作者
价格
{% for book in books %}
{{ book.name }}
{{book.author}}
{{book.name}}
{% endfor %}
def index():
books=[
{
'name':u'A',
'author':'A.a',
'price':120
},
{
'name': 'B',
'author': 'B.a',
'price': 120
},
{
'name': 'C',
'author': 'C.a',
'price': 120
},
{
'name': 'D',
'author': 'D.a',
'price': 120
}
]
return render_template('index.html',books=books)
过滤器(本身就是一个函数,特征是管道符’|‘)
1.介绍和语法:
*介绍:过滤器可以处理变量,把原始的变量经过处理后展示出来。
*语法:
{{avatar|default('xxx‘)}}
2.default过滤器:如果当前页面不存在,这时候可以指定默认值
3.length过滤器:求列表、字符创、字典或者元祖的长度
继承和Block
1.继承
*作用:可以把一些公共的代码放在父模板中,避免每个模板写相同的代码。
*语法:
{%extends 'base.html'%}
2.block实现
*作用:可以让字幕版实现一些自己的需求。父模板需要提前定义好
*注意:子模板中的代码,必须要放在block块中。
{% block main %}
{% endblock %}
url链接和加载静态文件
1.使用'url_for('视图函数名称')可以反转成url
2.加载静态文件
*语法‘url_for('static',filename='文件路径')’
*静态文件,flask会从‘static’文件夹中开始寻找,路径直接其后路径
python3装mysql是装pymysql哦
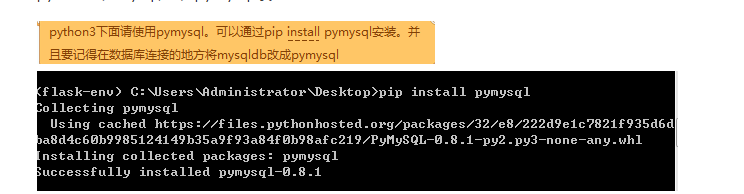
1.在类unix系统上,直接进入虚拟化环境,输入‘sudo pip install mysql-python’
2.win系统上需要装驱动,但python3直接进入虚拟环境,装pip install pymysql
*数据库连接的地方将mysqldb改成pymysql
flask-sqlalchemy的介绍与安装:
1.ORM:Object Relationship Mapping(关系模型映射)
class Article(Model):
id=int()
title=string()
content=Text()
article=Article(id-1,title='aaa',content='bbb')
add(article1)
aeticle1.title='ccc'
update(article1)
delete(article1)
2.flask-sqlalchemy是一套ORM框架
3.ORM的好处:让我们操作数据库跟操作的对象是一样的,非常方便。因为一个表就抽象成一个类。
4.安装:’sudo pip install sqlalchemy'/'pip install sqlalchemy'
flask-sqlalchemy对的使用
services.msc 确认数据库服务已开启
cmd中
连接数据库的语句是:net start mysql
在bin目录下:mysql -u root -p
改密码(改了一万年终于改好了,cmd真的很麻烦呢)
[注意]一旦进入数据库代码要以;结尾
alter user 'root'@'localhost' identified by 'youpassword';
create database db_demol utf8;
1.初始化和设置数据库配置信息
使用flask_sqlalchemy import SQLALchemy
form flask_sqlalchemy import SQLALchemy
#app=Flask(_name_)
#app.config.from_object(config)
#db=SQLchemy(app)
2.设置配置信息:在'config.py'中添加以下配置信息
#dialect+driver://username:password@host:port/database
DIALECT ='mysql'
DRIVER ='pymysql'
USERNAME ='root'
PASSWORD ='czy2018'
HOST ='127.0.0.1'
PORT ='3306'
DATABASE ='db_demol'
# 这个连接字符串变量名是固定的具体 参考 flask_sqlalchemy 文档 sqlalchemy会自动找到flask配置中的 这个变量
SQLALCHEMY_DATABASE_URI = "{}+{}://{}:{}@{}:{}/{}?charset=utf8".format(DIALECT, DRIVER, USERNAME, PASSWORD, HOST, PORT,
DATABASE)
SQLALCHEMY_TRACK_MODIFICATIONS=False
3.在主app文件中添加主配置文件
app=Flask(_name_)
app.config.from_object(config)
db=SQLchemy(app)
使用flask-SQLALchemy创建模型与表的映射:
1.模型需要继承自‘db.Model',然后需要映射到表中的属性,必须写成’db.Column'的数据类型
2.数据类型:
‘db.Integer’--int
'db.String'--varchar
'db.Text'--text
3.其他参数
'primary_key'主键
'autoincrement'自增
'nullable=True/False'是否可空
4.最后需要调用'db.create_all'来将模型真正的创建到数据库中。
增删改查
查
#select * from article where title='article'
result = Article.query.filter(Article.title=='aaa').all().first
print (result.title,result.content)
改
1.查找要修改的数据
2.修改
3.提交事务
article1=Article.query.filter(Article.title=='aaa').first()
article1.content='bbb'
db.session.commit()
删除
1.查找到要删除的数据
2.删除
3.提交
article1=Article.query.filter(Article.content=='aaa').first()
db.session.delete(article1)
db.session.commit()
SQLALchemy外键约束
class User(db.Model):
__tablename__='user'
id=db.Column(db.Integer,primary_key=True,autoincrement=True)
username=db.Column(db.String(100),nullable=False)
class Article(db.Model):
__tablename__='article'
id=db.Column(db.Integer,primary_key=True,autoincrement=True)
title=db.Column(db.String(100),nullable=False)
content=db.Column(db.Text,nullable=False)
author_id=db.Column(db.Integer,db.ForeignKey('user.id'))#外键
author=db.relationship('User',backref=db.backref('article'))#正回溯,给‘Article'这个模型添加一个‘author’属性,可以访问这篇文章的作者数据,像访问普通模型一样。
’backref‘是定义反向引用,可以通过’User‘这个模型访问这个模型写的所有文章
article=Article(title='apple',content='appletree')
article.author=User.query.filter(User.id==1).first()
db.session.add(article)
db.session.commit()
*通过1表的a属性找2表的b属性内容
article=Article.query.filter(Article.title=='apple').first()
return "username:%s"%article.author.username
*通过2表的b属性找1表的a属性内容
user=User.query.filter(User.username=='jx').first()
result=user.article
for article in result:
print(article.title)
1对多关系
sql的创建相关代码复习
create table article(
id int primary key autoincrement,
title varchar(100) not null,
)
create table tag(
id int primary key autoincrement,
name varchar(100) not null,
)
create table article_tag(
article_id int,
tag_id int,
primary key('article_id','tag_id'),
foreign key 'article_id'reference'article.id',
foreign key 'tag_id'reference'tag.id'
)
*多对多的关系,要通过一个中间表进行关联
*中间表,不能通过‘class’的方式实现,只能通过‘
db.Table('表名',
db.Column('表A',其数据类型及其他属性,db.Foreign('其外键属性名'),primary_key=True),
db.Column('表B',其数据类型及其他属性,db.Foreign('其外键属性名'),primary_key=True)
) ’的方式实现
*设置关联'tags=db.relationship('Tag',secondary=article_tag,backref=db.backref('articles'))'需要使用一个关键字参数'secondary=中间表'来进行关联
*访问和数据添加,可通过‘
article1=Article(title='aaa')
article2=Article(title='bbb'
tag1=Tag(name='111')
tag2=Tag(name='222')
article1.tags.append(tag1)
article1.tags.append(tag2)
article2.tags.append(tag1)
article2.tags.append(tag2)
db.session.add(article1)
db.session.add(article2)
db.session.add(tag1)
db.session.add(tag2)
db.session.commit()’实现
article_tag=db.Table('article_tag',
db.Column('article_id',db.Integer,db.ForeignKey('article.id'),primary_key=True),
db.Column('tag_id',db.Integer,db.ForeignKey('tag.id'),primary_key=True)
)
class Article(db.Model):
__tablename__='article'
id=db.Column(db.Integer,primary_key=True,autoincrement=True)
title=db.Column(db.String(100),nullable=False)
tags=db.relationship('Tag',secondary=article_tag,backref=db.backref('articles'))
class Tag(db.Model):
__tablename__='tag'
id=db.Column(db.Integer,primary_key=True,autoincrement=True)
name=db.Column(db.String(100),nullable=False)
db.create_all()
@app.route('/')
def hello_world():
article1=Article(title='aaa')
article2=Article(title='bbb')
tag1=Tag(name='111')
tag2=Tag(name='222')
article1.tags.append(tag1)
article1.tags.append(tag2)
article2.tags.append(tag1)
article2.tags.append(tag2)
db.session.add(article1)
db.session.add(article2)
db.session.add(tag1)
db.session.add(tag2)
db.session.commit()
article1 = Article.query.filter(Article.title == 'aaa').first()
tags = article1.tags
for tag in tags:
print(tag)
return 'Hello World!'
Flask-Script的介绍与安装
1.Flask-Script:.Flask-Script的作用是可以通过命令行的形式来操作Flask。列入通过命令跑一个开发版本的服务器、设置数据库、定时任务等。
2.安装:首先进入到虚拟环境中(到script目录,执行activate),然后'pip install flask-script'来进行安装。

3.如果直接在主‘manage.py'中写命令,那么在终端就只需要’python manage.py command_name'就可以了
4.如果把一些命令集中在一个文件中,那么在线终端就需要输入一个父命令,比如'python manage.py db init'。
5.例子
#manage.py
from flask_script import Manager
from app import app
from db_script import DBmanager
manager=Manager(app)
@manager.command#专注器
def runserver():#运行服务器
print ('服务器跑起来了')
manager.add_command('db',DBmanager)
if __name__=='__main__':
manager.run()
#db_script.py
from flask_script import Manager
DBmanager=Manager()
@DBmanager.command def init():
print('数据库初始化完成')
@DBmanager.command def migrate():
print('数据表迁移成功')

分开models解决循环引用
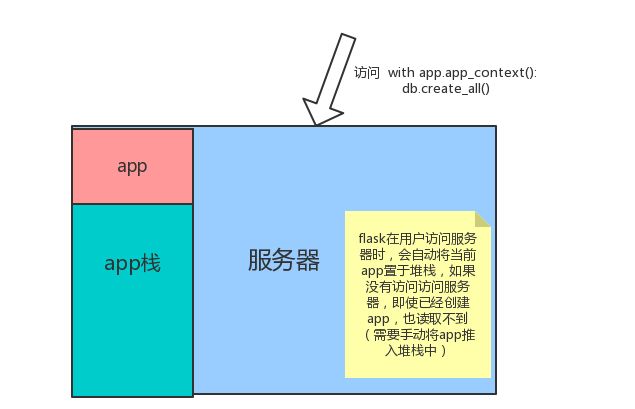
1.分开models让代码更加方便的管理
2.把'db'放在一个单独的文件中,切断循环引用的线条就可以了。
!!很多时候报错都是拼错和符号打错,注意
flask-migrate讲解
1.介绍:因为采用'db.create_all()'在后期修改字段的时候,不会自动映射到数据库中能够,必须删除表,然后重跑'db.create_all()'才会映射,这样不符合我们的需求。因此flask-migrate就是为了解决这个问题,她可以在每次修改模型后,将修改的东西映射到数据库中。
2.使用'flask_migrate'必须借助'flask_script',这个包的'MigrateCommand'中包含了所有和数据库相关的命令。
4.'flask_migrate'相关命令
*python manage.py db init :初始化一个迁移脚本环境,只需要执行一次。
*python manage.py db migrate :将模型生成迁移文件,只要模型更改了,就需要执行一遍这个命令。
*python manage.py db upgrade:将迁移文件真正的映射到数据库中。每次运行了migrate命令,都要执行一遍这个命令。
注意需要将你想要映射到数据库的模型,都要导入‘manage.py’文件中,如果没有导入进去,就不会映射到数据库中。
from flask_script import Manager
from app import app
from flask_migrate import Migrate,MigrateCommand
from exts import db
from models import Article
#模型(python manage,py db init) -> 迁移文件(python manage.py db migrate) -> 表(python manage.py db upgrate)
#多次更改不需要初始化,只需要做迁移和更新映射
manager=Manager(app)
#1.要使用flask_migrate,必须绑定app和db
migrate=Migrate(app,db)
#2.把MigrateCommand命令添加到manager中
manager.add_command('db',MigrateCommand)
if __name__=='__main__':
manager.run()
session和cookie

cookie
1.cookie出现的原因:在网站中,http请求是无状态的。也就会说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求的是哪个用户。cookie的出现就是为了解决这个问题,第一次登录后服务器返回一些数据(cookie)给浏览器,然后浏览器保存在本地,当该用户发送第二次请求的时候,就会自动那个把上次存储的cookie数据自动的携带给服务器,服务器通过浏览器携带的数据就能判断当前用户是哪个了。
2.如果服务器返回了cookie给浏览器,那么浏览器下次再请求相同服务器时,就会自动把cookie发送给浏览器,是一个无需用户操作的过程。
3.cookie是保存在浏览器中的,相对的是浏览器。
session
1.session介绍:session和cookie的作用类似,都是为了存储用户相关信息。不同的是,cookie是存储在本地浏览器,而session存储在服务器。存储在服务器的数据会更加安全,不容易被窃取。但存储在服务器也有一定的弊端,就是会占用服务器的资源,但现在服务器已经发展至今,一些session信息还是绰绰有余的。
2.session好处:
*敏感数据不是直接发送回给浏览器,而是发送回一个‘session_id’,服务器将'session_id'和敏感数据做一个映射存储在'session‘(在服务器上面)中,更加安全。
flask中的session机制
1.flask中的session机制是:把敏感数据经过加密后放入session中,然后再把session存放到cookie中,下次请求的时候,再从浏览器发送来的cooki中读取session,然后再从session中读取敏感数据,并进行解密,获取最终的用户数据。
2.flask的这种session机制可以节省服务器的开销,因为把所有信息都存储到了客户端(浏览器)。
3.安全是相对的,把session放到cookie中,经过加密,也是比较安全的,这点大家放心使用就可以了。
操作session
1.session的操作方式:
*使用session需要从flask中导入session,之后所有关于session的操作都是通过这个变量来的。
*使用session需要设置SECRET_KEY来加密,因为每次启动服务器SECRET_KEY值都会变化,之前的session就不能通过这个SECRET_KEY来解密了。
*操作session跟操作字典是一样的:
*增:session[username']=...'
*删:session.pop('username') or del session[username]
*清除所有session:session.clear()
*获取session:session.get(''username')
2.设置session过期时间:
*如果没写session过期时间,默认浏览器关闭为过期时间
*如果设置session的permanent属性为True,那么过期时间为31天
*可以通过给app.config设置PERMANENT_SESSION_LIFETIME来更改过期时间,这个值的数据类型是'datetime.timedelay'类型
from flask import Flask,session
import os
from datetime import timedelta
app = Flask(__name__)
app.config['SECRET_KEY']=os.urandom(24)
app.config['PERMANENT_SESSION_LIFETIME']=timedelta(days=7)
#添加数据到session中 #操作session的时候,跟操作字典是一样的 #SECRET_KEY @app.route('/')
def hello_world():
session['username']='jubi'
#如果没写session过期时间,默认浏览器关闭为过期时间
#如果设置session的permanent属性为True,那么过期时间为31天 session.permanent=True
return 'Hello World!'
补充:

知识点补充
get请求和post请求
介绍:
1.get请求:
*使用场景:如果只对服务器获取数据,并没有对服务器产生任何影响,那么这时使用get请求。
*传参:get请求传参是放在url中,并且是通过‘?’的形式来指定key和value的。
2.post请求:
*使用场景:如果要对服务器产生影响,那么使用post请求。
*传参:通过‘from data’的形式发送给服务器的。
get和post请求获取参数:
1.get请求是通过'flask.request.args'来获取。
2.post请求是通过'flask.request.form'来获取。
3.post请求在模板中要注意几点:
*input标签中,要写name来标识这个value的key,方便后台获取。
*在写form表单的时候,要指定'method=post',并且要指定'action='/login/''。
跳转到搜索页面
from flask import Flask,render_template,request
app = Flask(__name__)
@app.route('/')
def hello_world():
return render_template('index.html')
@app.route('/search/')
def search():
'''
1.arg:argument
args的存储相当于一个字典,即比如参数a=apple&b=banana
{
a:apple
b:banana
}
2.通过request.args参数可以获取用户传来的参数
3.通过request.args.get('q')可以获取用户提交的查询参数
'''
a=request.args
q=request.args.get('q')
return u'用户提交的查询参数是:%s
' \
u' 直接打印是:%s'% (q,a)
#默认的视图函数只能采用get请求
#如果要采用post请求,要写明
@app.route('/login/',methods=['GET','POST'])
def login():
if request.method=='GET':
return render_template('login.html')
else:
username=request.form.get('username')
password=request.form.get('password')
print('username:',username)
print('password:',password)
return 'post request'
if __name__ == '__main__':
app.run()
程序和请求上下文
from flask import request
临时将某些对象变为全局变量(不是真正的全局变量,只是让特定的变量在单线程中全局可以访问)
current_app 程序上下文 当前激活程序的程序实例
g 程序上下文 处理请求时作为临时的存储对象,每次请求都会重置这个变量。
request 请求上下文 请求对象,封装了客户端发出的http请求的内容。
session 请求上下文 用户会话,记住存储请求之间需要记住的词典。
before_first_request 注册一个函数,在处理第一个请求之前运行。
before_request 注册一个函数,在每次请求之前运行。
after_request 注册一个函数,如果没有未处理的异常抛出,在每次请求之后运行
teardown_reques t注册一个函数,即使有未处理的异常抛出,也在每次请求之后运行。
请求钩子函数和视图函数共享数据一般使用上下文全局变量g,例如,before_request处理程序可以从数据库库中加载已登录用户,并将其保存到g.user中。随后调用视图函数时,视图函数再使用g.user
@app.before_request
def my_before_request():
user_id=session.get('user_id')
if user_id:
user=User.query.filter(User.id==user_id).first()
if user:
g.user=user
@app.context_processor
def my_context_processor():
if hasattr(g,'user'): #函数判断属性g有没有user对象
return {'user': g.user}
return {}
#befor_request-->视图函数-->context_processor
保存全局属性的g对象
from flask import g
g.xxx=
g:global
1.g对象是专门用来保存用户数据的。
2.g对象在一次请求中的所有代码的地方都是可以使用的,但是仅限于当次请求。
钩子函数(hook function)
before_request:
*在请求之前执行的
*在视图函数执行之前执行的
*这个函数只是一个装饰器,她可以把需要设置为钩子函数的代码放到视图函数之前执行
context_processor: *上下文处理器应该返回一个字典,字典中的‘key’会被模板中当成变量来渲染
*上下文处理器中返回的字典,在所有页面中都是可用的。
*被这个装饰器修饰的钩子函数,必须返回一个字典,即使为空也要返回。
bootstrap官网:http://getbootstrap.com
装饰器
装饰器实际上就是一个函数,但有两个特别之处:
1.参数是一个函数
2.返回值是一个函数
from functools import wraps
#在所有的函数执行之前,都要答应一个hello world
def my_log(func):
@wraps(func)
def wrapper(*args,**kwargs):#这种参数来解决包容性
print('hello world')
func(*args,**kwargs)
return wrapper
#run.__name__代表的是run这个函数的名称
@my_log
def run():
print('run')
#->run=my_log(run)=wrapper
#run()
#wrapper()
1.装饰器的使用时通过@符号,放在函数上面
2.装饰器中定义的函数,需要用args,*kwargs两对兄弟组合
3.需要使用哪个functools,wraps在装饰器中的函数上把传进来的一个函数进行函数包裹,这样就不会丢失原来的函数的name等属性。
常函数
安装
python
flask:pip install flask
virtualenv:pip install virtualenv
pymysql:j进入虚拟机环境(到script目录,执行activate),pip install pymysql
flask-SQLALchemy:进入虚拟机环境,pip install sqlalchemy
flask-script:进入虚拟环境,pip install flask-script
flask-migrte:进入虚拟机环境,pip install flsk-migrate
pip install flask_login
ctrl+b看函数解析