人工智能入门课程学习(8)——决策树算法
文章目录
- 1.决策树算法简介
- 2.决策树分类原理
- 2.1 熵
- 2.2 决策树的划分依据一------信息增益
- 2.3 决策树的划分依据二----信息增益率
- 2.4 决策树的划分依据三——基尼值和基尼指数
- 案例
- 2.5 小结
- 1.决策树构建的步骤
- 2.常见决策树类型的比较
- 1.ID3算法
- 2.C4.5算法
- CART算法
- 3.特征工程——特征提取
- 3.1 字典特征提取
- 3.2 应用
- 3.3 决策树算法api
- 4.案例:泰坦尼克号船员生存预测
- 4.1 步骤分析
- 4.2 代码实现过程
- 5.总结
1.决策树算法简介
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
怎么理解这句话?通过一个对话例子

想一想这个女生为什么把年龄放在最上面判断!??
上面案例是女生通过定性的主观意识,把年龄放到最上面,那么如果需要对这一过程进行量化,该如何处理呢?
此时需要用到信息论中的知识:信息熵,信息增益
2.决策树分类原理
2.1 熵
物理学上,熵 Entropy 是“混乱”程度的量度。
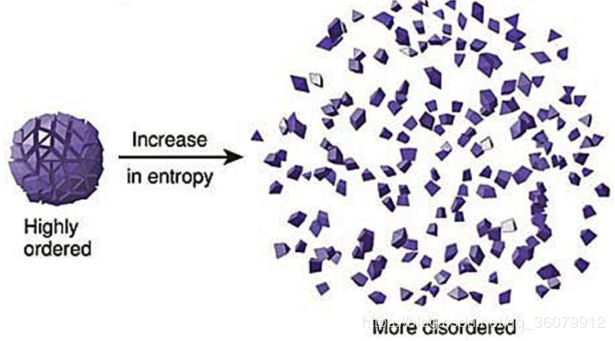
系统越有序,熵值越低;系统越混乱或者分散,熵值越高。
1948年香农提出了信息熵(Entropy)的概念。
假如事件A的分类划分是(A1,A2,…,An),每部分发生的概率是(p1,p2,…,pn),那信息熵定义为公式如下:(log是以2为底,lg是以10为底)
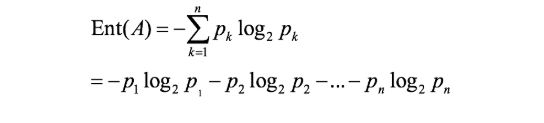
2.2 决策树的划分依据一------信息增益
信息增益:以某特征划分数据集前后的熵的差值。熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
信息增益 = entroy(前) - entroy(后)
例如计算 性别和活跃度两个特征,哪个对用户流失影响更大
数据说明:第一列为论坛号码,第二列为性别,第三列为活跃度,最后一列用户是否流失。
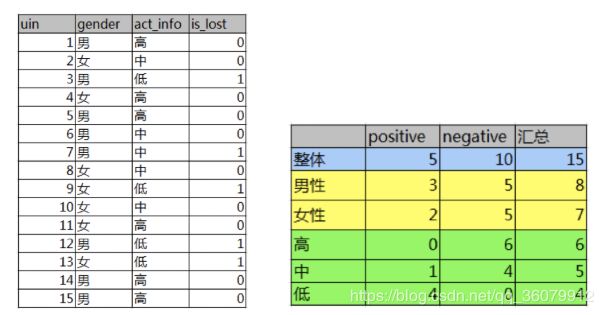
通过计算信息增益可以解决这个问题,统计上右表信息
其中Positive为正样本(已流失),Negative为负样本(未流失),下面的数值为不同划分下对应的人数。
可得到三个熵:
 活跃度的信息增益比性别的信息增益大,也就是说,活跃度对用户流失的影响比性别大。
活跃度的信息增益比性别的信息增益大,也就是说,活跃度对用户流失的影响比性别大。
在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
2.3 决策树的划分依据二----信息增益率
增益率:增益比率度量是用前面的增益度量Gain(S,A)和所分离信息度量SplitInformation(如上例的性别,活跃度等)的比值来共同定义的。

2.4 决策树的划分依据三——基尼值和基尼指数
基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不一致的概率。故,Gini(D)值越小,数据集D的纯度越高。
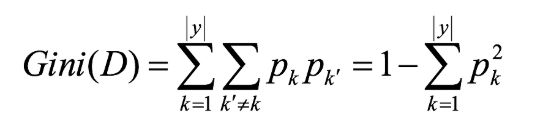
基尼指数Gini_index(D):一般,选择使划分后基尼系数最小的属性作为最优化分属性。
案例
请根据下图列表,按照基尼指数的划分依据,做出决策树。
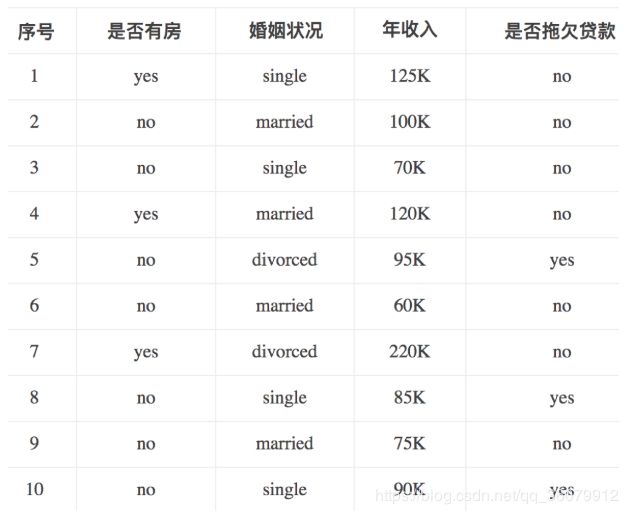
1,对数据集非类标号属性{是否有房,婚姻状况,年收入}分别计算它们的Gini系数增益,取Gini系数增益值最大的属性作为决策树的根节点属性。
2,根节点的Gini系数为:
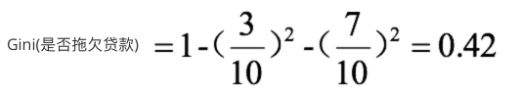
3,当根据是否有房来进行划分时,Gini系数增益计算过程为:

4,若按婚姻状况属性来划分,属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的Gini系数增益。
{married} | {single,divorced}
{single} | {married,divorced}
{divorced} | {single,married}
分组为{married} | {single,divorced}时:

对比计算结果,根据婚姻状况属性来划分根节点时取Gini系数增益最大的分组作为划分结果,即:{married} | {single,divorced}
5,同理可得年收入Gini。。。
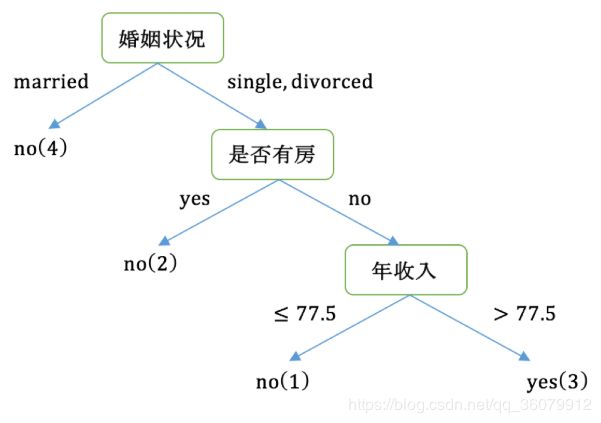
最后根据Gini值建立的决策树:
2.5 小结
1.决策树构建的步骤
1.开始将所有记录看作一个节点
2.遍历每个变量的每一种分割方式,找到最好的分割点
3.分割成两个节点N1和N2
4.对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止。
2.常见决策树类型的比较

1.ID3算法
存在的缺点
(1) ID3算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息.
(2) ID3算法只能对描述属性为离散型属性的数据集构造决策树。
2.C4.5算法
做出的改进(为什么使用C4.5要好)
(1) 用信息增益率来选择属性
(2) 可以处理连续数值型属性
(3)采用了一种后剪枝方法
(4)对于缺失值的处理
C4.5算法的优缺点
优点:
产生的分类规则易于理解,准确率较高。
缺点:
在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
CART算法
CART算法相比C4.5算法的分类方法,采用了简化的二叉树模型,同时特征选择采用了近似的基尼系数来简化计算。
C4.5不一定是二叉树,但CART一定是二叉树。
同时,无论是ID3, C4.5还是CART,在做特征选择的时候都是选择最优的一个特征来做分类决策,但是大多数,分类决策不应该是由某一个特征决定的,而是应该由一组特征决定的。这样决策得到的决策树更加准确。这个决策树叫做多变量决策树(multi-variate decision tree)。在选择最优特征的时候,多变量决策树不是选择某一个最优特征,而是选择最优的一个特征线性组合来做决策。这个算法的代表是OC1,这里不多介绍。
如果样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习里面的随机森林之类的方法解决。
3.特征工程——特征提取
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
- 特征提取分类:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习将介绍)
特征提取API:
sklearn.feature_extraction
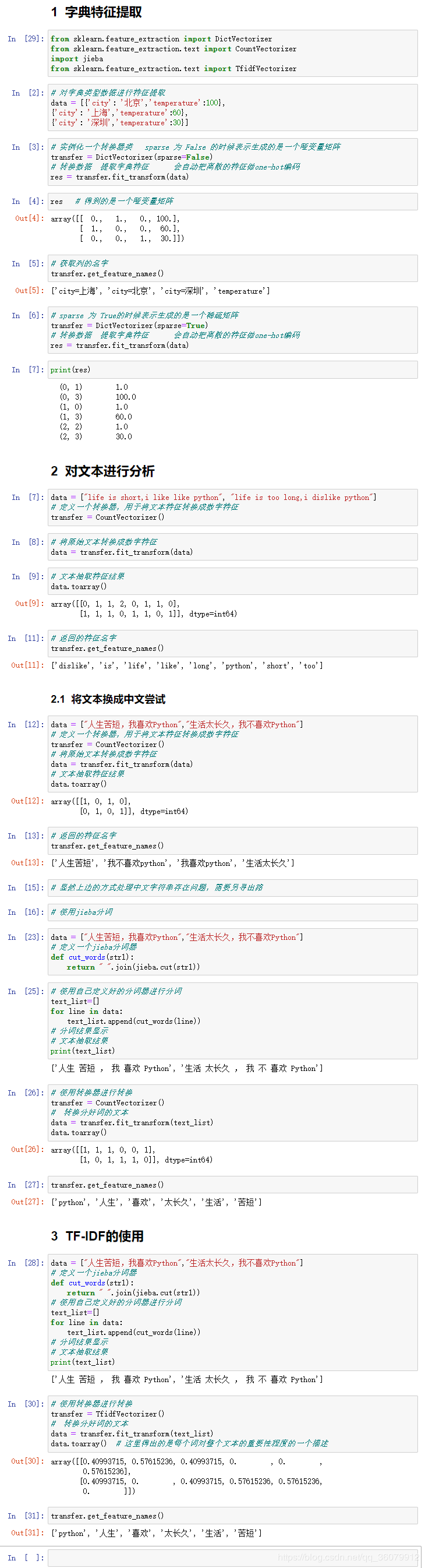
3.1 字典特征提取
作用:对字典数据进行特征值化
- sklearn.feature_extraction.DictVectorizer(sparse=True,…)
- DictVectorizer.fit_transform(X)
- X:字典或者包含字典的迭代器返回值
- 返回sparse矩阵
- DictVectorizer.get_feature_names() 返回类别名称
- DictVectorizer.fit_transform(X)
3.2 应用
我们对以下数据进行特征提取:
3.3 决策树算法api
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)

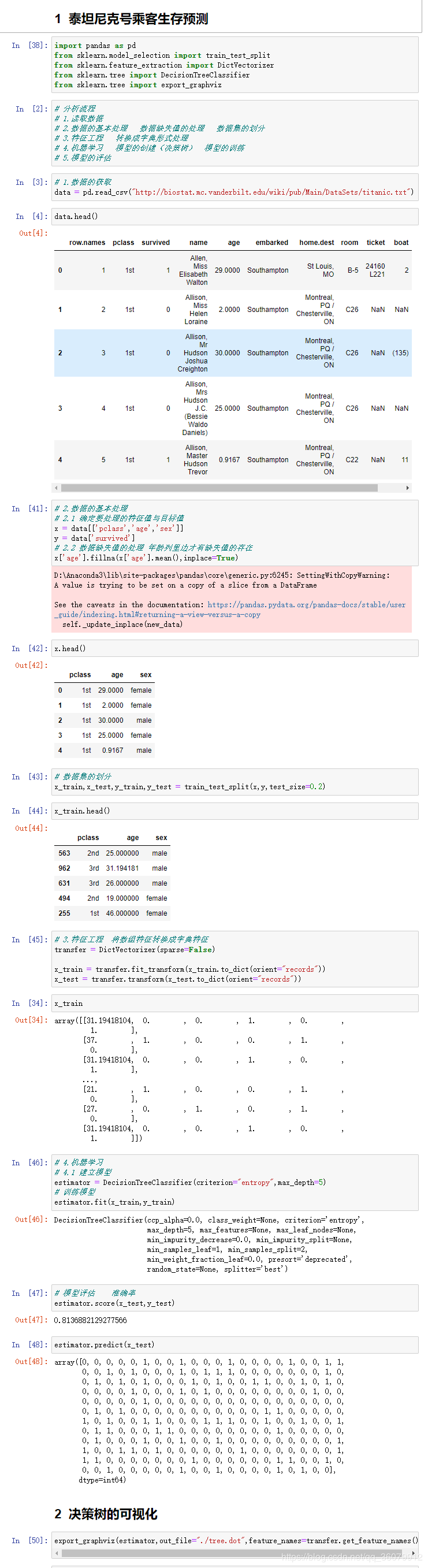
4.案例:泰坦尼克号船员生存预测
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt

经过观察数据得到:
-
1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
-
2 其中age数据存在缺失。
4.1 步骤分析
1.获取数据
2.数据基本处理
2.1 确定特征值,目标值
2.2 缺失值处理
2.3 数据集划分
3.特征工程(字典特征抽取)
4.机器学习(决策树)
5.模型评估
4.2 代码实现过程
## 将生成的 ./dot 文件导入 http://webgraphviz.com/ ,然后就可以看到整个决策树的全况了
5.总结
