fasttext ---强大的文本分类
最近接触到自然语言处理,需要对网上新闻进行文本分类,所以入坑fasttext。 之前用过CNN网络写过文本分类,直到本渣接触到了fasttext,才发现,人生苦短,我要快!
这篇文章是转载自 https://blog.csdn.net/weixin_36604953/article/details/78324834 这个江户川大神@夏洛克江户川,文章通俗易懂
文本分类需要CNN?No!fastText完美解决你的需求(后篇)
想必通过前一篇的介绍,各位小主已经对word2vec以及CBOW和Skip-gram有了比较清晰的了解。在这一篇中,小编带大家走进业内最新潮的文本分类算法,也就是fastText分类器。fastText与word2vec的提出者之所以会想到用fastText取代CNN(卷积神经网络)等深度学习模型,目的是为了在大数据情况下提高运算速度。
其实,文本的学习与图像的学习是不同的。学习不同,一般情况下,文本学习并不需要过多隐藏层、过复杂的神经网络,为什么这么说呢?打个比方,有这样一句话:“柯南是个聪明的帅哥”,如果让你去学习理解这句话,听上二三十次次与听上两三次相比,对于这句话的理解可能也没有什么提升,就模型而言,不需要过复杂的神经网络就可以很好的对这句话进行学习,然而图像不同,如果让你临摹一个大师的化作,你第一次临摹可能是个四不像,但第一万次临摹,可能就会以假乱真了。所以,用简单的网络对自然语言进行学习,可以快速、高质量的得到结果。正因如此,才有了fastText算法。
言归正传,我们开始fastText算法的深入了解,这篇文章主要从三个方面来介绍算法:模型架构、分层softmax、n-gram特征。在算法原理介绍完毕后,同上一篇文章一样,会带领各位小主实现fastText算法的应用,迫不及待了吧?
预备知识
为了更好的理解fastText,我们先来了解一些预备知识。第一个是BoW模型,也叫做词袋模型。BoW模型(Bag of words)应用于自然语言处理、信息检索和图像分类等方面。它忽略掉文本的语法和语序等要素(举个例子,Bow模型认为“我爱你”和“你爱我”是相同的,如果我们的世界是一个BoW模型该有多好,再也不会出现对女神单相思的情况了),将其仅仅看作是若干词汇的集合。BoW 使用一组无序的单词(word)来表达一段文字或一个文档,并且文档中每个单词的出现都是独立的。
例如:首先给出两个简单的文本文档如下:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
基于上述两个文档中出现的单词,构建如下一个词典 (dictionary):
{“John”: 1, “likes”: 2,”to”: 3, “watch”: 4, “movies”: 5,”also”: 6, “football”: 7, “games”: 8,”Mary”: 9, “too”: 10}
上面的词典中包含10个单词, 每个单词有唯一的索引, 那么每个文本我们可以使用一个10维的向量来表示,向量中的元素是词典中对应的词语出现的频数。如下所示:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1,1, 1, 0, 1, 1, 1, 0, 0]
该向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频数。
第二个要介绍的是名为“霍夫曼树”的数据结构,fastText的速度快,且不会受到不平衡分类问题影响的关键因素就是这个数据结构。
霍夫曼编码树,又称最优二叉树。是一类带权路径长度最短的树。假设有n个权值{w1,w2,…,wn},如果构造一棵有n个叶子节点的二叉树,而这n个叶子节点的权值是{w1,w2,…,wn},则所构造出的带权路径长度最小的二叉树就被称为霍夫曼树。
带权路径长度:如果在一棵二叉树中共有n个叶子节点,用Wi表示第i个叶子节点的权值,Li表示第i个叶子节点到根节点的路径长度,则该二叉树的带权路径长度:
WPL=W1∗L1+W2∗L2+...Wn∗LnWPL=W1∗L1+W2∗L2+...Wn∗Ln
霍夫曼树的构建步骤如下:
(1)将给定的n个权值看做n棵只有根节点(无左右孩子)的二叉树,组成一个集合HT,每棵树的权值为该节点的权值。
(2)从集合HT中选出2棵权值最小的二叉树,组成一棵新的二叉树,其权值为这2棵二叉树的权值之和。
(3)将步骤2中选出的2棵二叉树从集合HT中删去,同时将步骤2中新得到的二叉树加入到集合HT中。
(4)重复步骤2和步骤3,直到集合HT中只含一棵树,这棵树便是霍夫曼树。
感觉还云里雾里?没关系,小编来举个简单的例子你就明白了。假设给定如图1的四个带权重的节点A—D,结点下方为其对应的权重。
感觉还云里雾里?没关系,小编来举个简单的例子你就明白了。假设给定如图1的四个带权重的节点A—D,结点下方为其对应的权重。

图1
首先选出权重最小的两个节点作为图2中新树的左右子树(新树即右侧由6、C、A组成的树),新树根节点权重为其左右子树权重之和(即1+5=6)。

图2
然后重复前一操作,从剩余结点中选出最小的,与前一个树的根节点组成新树的左右结点,如图3所示,新的根节点权重为其两个子结点之和(10+6=16)。

图3
在重复前面的操作,得到图4的最终树。
fastText的霍夫曼树叶子结点对应为最终的label,可以看到,权重最大的,也就是权重最大的label,其深度最小,fastText 充分利用了这个性质,使得其速度得以提升。

图4
Huffman编码(霍夫曼编码):
对每个字符设计长度不等的编码,让出现较多的字符采用尽可能短的编码。利用霍夫曼树求得的用于通信的二进制编码称为霍夫曼编码。
树中从根结点到每个叶子节点都有一条路径,对路径上的各分支约定指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为各个叶子节点对应的字符编码,即是霍夫曼编码。以前面的例子为例,各路径上的编码如图5所示。故A结点的编码应当为111,B为10,C为110,D为0。D是权重最大的结点,换言之也就是出现最多的结点,其编码最短,只有一个0,而权重最小的结点是A,其编码为111,这样的编码方式完成了我们对节点编码的需求。

图5
fastText模型架构
fastText算法是一种有监督的模型,与《前篇》中的CBOW架构很相似,其结构如图6所示。《前篇》中的CBOW,通过上下文预测中间词,而fastText则是通过上下文预测标签(这个标签就是文本的类别,是训练模型之前通过人工标注等方法事先确定下来的)。如果小主在上一篇文章中已经对CBOW了解透彻了,可能到这里你已经觉得fastText并没有什么新鲜玩意儿。事实确实如此,从模型架构上来说,沿用了CBOW的单层神经网络的模式,不过fastText的处理速度才是这个算法的创新之处。
fastText模型的输入是一个词的序列(一段文本或者一句话),输出是这个词序列属于不同类别的概率。在序列中的词和词组构成特征向量,特征向量通过线性变换映射到中间层,再由中间层映射到标签。fastText在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
图 6 展示了一个有一个隐藏层的简单模型。第一个权重矩阵w_1可以被视作某个句子的词查找表(词表查找是啥来着?去看看《前篇》中的那个矩阵相乘你就想起来了)。词表征被平均成一个文本表征,然后其会被馈送入一个线性分类器。这个构架和《前篇》介绍的CBOW模型相似,只是中间词(middle word)被替换成了标签(label)。该模型将一系列单词作为输入并产生一个预定义类的概率分布。我们使用一个softmax方程来计算这些概率。当数据量巨大时,线性分类器的计算十分昂贵,所以fastText使用了一个基于霍夫曼编码树的分层softmax方法。常用的文本特征表示方法是词袋模型,然而词袋(BoW)中的词顺序是不变的,但是明确考虑该顺序的计算成本通常十分高昂。作为替代,fastText使用n-gram获取额外特征来得到关于局部词顺序的部分信息,后文将详细介绍。

图6
层次softmax
Facebook声称fastText比其他学习方法要快得多,能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。这样的速度取决于什么呢?模型架构上并没有什么本质革新,接下来就带你“上高速”~
softmax函数
上一篇,我们已经介绍了这个函数。softmax函数实际是一个归一化的指数函数:
σ(z)j=ezj∑Kk=1ezkσ(z)j=ezj∑k=1Kezk
而softmax把一个k维的real value向量(a1,a2,a3,a4….)映射成一个(b1,b2,b3,b4….)其中bi是一个0-1的常数,然后可以根据bi的大小来进行多分类的任务,如取权重最大的一维。
分层softmax(Hierarchical softmax)
分层softmax的目的是降低softmax层的计算复杂度。
二叉树。Hierarchical softmax本质上是用层级关系替代了扁平化的softmax层,如图1所示,每个叶子节点表示一个词语(即霍夫曼树的结构)。
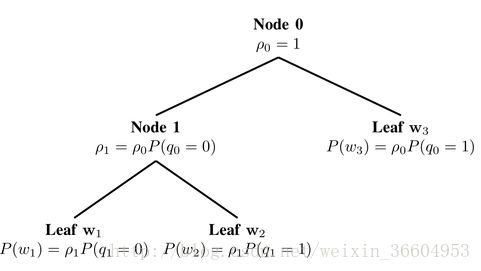
图7 Hierarchical softmax
我们可以把原来的softmax看做深度为1的树,词表V中的每一个词语表示一个叶子节点。如果把softmax改为二叉树结构,每个word表示叶子节点,那么只需要沿着通向该词语的叶子节点的路径搜索,而不需要考虑其它的节点。这就是为什么fastText可以解决不平衡分类问题,因为在对某个节点进行计算时,完全不依赖于它的上一层的叶子节点(即权重大于它的叶结点),也就是数目较大的label不能影响数目较小的label(即图5中B无法影响A和C)。
平衡二叉树的深度是log2(|V|),因此,最多只需要计算log2(|V|)个节点就能得到目标词语的概率值。hierarchical softmax定义了词表V中所有词语的标准化概率分布。
具体说来,当遍历树的时候,我们需要能够计算左侧分枝或是右侧分枝的概率值。为此,给每个节点分配一个向量表示。与常规的softmax做法不同,这里不是给每个输出词语w生成词向量v_w^’,而是给每个节点n计算一个向量〖vn’〗。总共有|V|-1个节点,每个节点都有自己独一无二的向量表示,H-Softmax方法用到的参数与常规的softmax几乎一样。于是,在给定上下文c时,就能够计算节点n左右两个分枝的概率:
p(right|n,c=σ(hTvnT))p(right|n,c=σ(hTvnT))
上式与常规的softmax大致相同。现在需要计算h与树的每个节点的向量v_n^’的内积,而不是与每个输出词语的向量计算。而且,只需要计算一个概率值,这里就是偏向n节点右枝的概率值。相反的,偏向左枝的概率值是1- p(right│n,c)。

图8 Hierarchical softmax的计算过程(来自Hugo Lachorelle的YouTube课件)
如图8所示,为了方便理解,这里的叶子节点给出的依然是词语,也就是CBOW的架构,fastText是相同的道理,只是将叶子节点替换为label即可。假设已知出现了词语“the”、“dog”、“and”、“the”,则出现词语“cat”的概率值就是在节点1向左偏的概率值、在节点2向右偏的概率以及在节点5向右偏的概率值的乘积。
值得注意的是,此方法只是加速了训练过程,因为我们可以提前知道将要预测的词语(以及其搜索路径)。在测试过程中,被预测词语是未知的,仍然无法避免计算所有词语的概率值。
向量表示该节点的搜索路径,词语“cat”的向量就是011。上文中提到平衡二叉树的深度不超过log2(|V|)。若词表的大小是|V|=10000,那么搜索路径的平均长度就是13.3。
N-gram
常用的特征是词袋模型,在第一部分小编已经介绍过词袋模型了。词袋模型不考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。“我爱你”的特征应当是“我”、“爱”、“你”。那么“你爱我”这句话的特征和“我爱你”是一样的,因为“我爱你”的bag(词袋)中也是只包含“你”、“爱”、“我”。
还是那句话——“我爱你”:如果使用2-gram,这句话的特征还有 “我-爱”和“爱-你”,这两句话“我爱你”和“你爱我”就能区别开来了,因为“你爱我”的2-gram的特征还包括“你-爱”和“爱-我”,这样就可以区分“你爱我”和“我爱你”了。为了提高效率,实务中会过滤掉低频的 N-gram。否则将会严重影响速度。
在fastText 中一个低维度向量与每个单词都相关。隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
fastText算法实现
这里提醒读者,fastText在Python2和Python3中都可以使用,已有了现成的包,但只支持Linux和mac系统,windows暂时还不支持fastText。本例使用的环境是linux-ubuntu16.04+Python3+JupyterNotebook的组合,读者当然可以使用其他IDE或是使用Python2,都是完全没有问题的。只需要在终端使用语句pip install fasttext(Python2)或是pip3 install fasttext进行安装即可。
我们使用的语料是清华大学的新闻文本(数据比较大,可以在http://thuctc.thunlp.org/message进行下载),这里不在详细介绍分词过程,与《前篇》中的过程基本是一致的。可以直接到https://pan.baidu.com/s/1jH7wyOY和https://pan.baidu.com/s/1slGlPgx下载处理好的训练集和测试集(处理后的数据形式为词与词之间用空格分开,词语与标签默认用label分隔),如图9所示。

图9 分词后数据样例
使用logging可以查看程序运行日志。fasttext.supervised()的第一个参数为训练集,即用来拟合模型的数据,第二个参数为模型存储的绝对路径,第三个为文本与标签的分隔符;训练好模型后通过load_model加载模型,对训练集使用test方法则可以在测试集上使用模型,则会得到模型在测试集上的准确率和召回率,可以看到模型的准确率和召回率是非常高的,而且对于这个近400Mb的训练集,拟合模型只花费了60秒左右(小编的电脑为8GB内存),速度是非常可观的。

图10 建立模型
fastText算法通过了两篇的讲解,相比聪明的你已经掌握了算法原理,关于fastText算法到这里就要告一段落了,熟悉了原理和思想,接下来小主可以去找些有趣的文本做一些有趣的事情了,与fastText一起飚车吧!