经典算法梳理(4)KMP字符串匹配算法
KMP算法是经典的字符串匹配算法,比较难懂被人诟病。本文尝试深入浅出地描述KMP算法。

KMP算法较为复杂的第一步:生成前缀数组
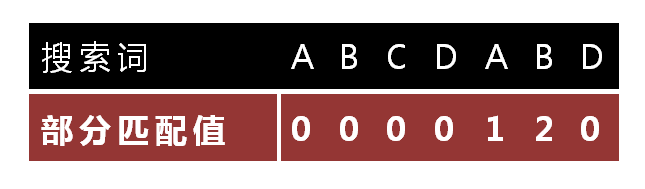
匹配后移动:匹配不成功,继续移动





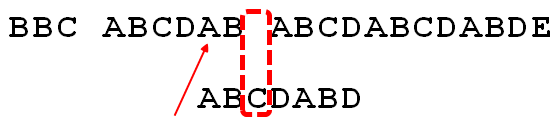


KMP算法是经典的字符串匹配算法,比较难懂被人诟病。本文尝试深入浅出地描述KMP算法。
字符串匹配,如图所示,在较长的字符串中,匹配找出,是否存在较短的的字符串。
图示字符串匹配从第一个数字开始匹配。我们想想暴力算法如何匹配?
第一个数字对齐,匹配7位,错误 ,移动到第二位继续之前的流程。。。很耗时间,能不能加速这个过程,就是KMP算法实现的
KMP算法较为复杂的第一步:生成前缀数组
(这里有些绕,注意看下方文字,容易理解这个前缀数组是怎么生成的)
我们的目标是得到这样的一个:前后缀加速数组!用来加速。注意看下面的文字,才容易理解如何生成这个数组
对于搜索词: A B C D A B D 我们首先找他的前缀,再找前缀的 前缀,后缀共有元素长度。(有点绕,继续看下面的)
这个搜索词的前缀:从长度1到长度7
A,AB,ABC,ABCD,ABCDA,ABCDAB,ABCDABD
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
至此 生成前缀数组 [0,0,0,0,1,2,0]
看两遍,就明白这个前缀数组怎么生成了!!确实得至少看两遍。
2 利用前缀数组,加速字符串的匹配过程:
开始正常的匹配过程:
匹配后移动:匹配不成功,继续移动
匹配到这里发现情况比较乐观。=。=
此时在小字符串内继续匹配
小字符串内匹配出现问题!!!
如果是普通的暴力循环。会重新移动到c字符又开始匹配。这不是我们需要的
拉出我们第一步的前缀数组!
KMP算法神奇之处,在于利用前缀数组,快速计算出移动位数,减少重复匹配次数!(念两遍)
移动位数 = 已匹配的字符数 - 对应的部分匹配值
这里选取的是 最后匹配的字符。(注意什么是最后的匹配字符!)
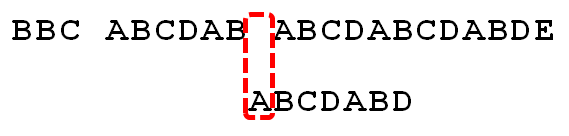
此时:已匹配字符数: 6
这里对应的字符是:ABCDABD的倒数第二个字符B, 对应的匹配值:2
待匹配的大字符串,开始移动: 6 - 2 = 4 个单位!
KMP神奇之处!:
移动前:
这样就移动了4个单位后:
此时c字符不匹配,C之前匹配的字符B
此时两个字符串匹配个数是 2 , B对应前后缀数组的值是0
移动单位: 2 - 0 = 2;
移动两位,默认空格时移动一位
这里空格移动一位
发现匹配6个之后,最后一位不一样
最后匹配位置还是B 继续移动: 6 - 2 = 4 位
匹配成功!