基于卷积神经网络的中药饮片识别
Identification of Chinese herbal decoction pieces based on convolutional neural network
写在前面:
本文将介绍如何在matlab上面搭建卷积神经网络
1.如何搭建cnn,2.常用概念,3.如何收集数据,4.程序解读
一.背景
图像识别技术已逐步应用于中医药领域,极大推动了中医药客观化、标准化相关研究。 采用模式识别方法不仅可提高中药饮片识别自动化程度及分类识别的稳定性,还能确保统一的分类结果,避免人工方法导致的分类结果不一致。
本次使用卷积神经网络进行常见的4味中药进行识别,并进行预测
二. 原理解说
-
神经网络的实现过程:
1、准备数据集,提取特征,作为输入喂给神经网络(Neural Network,NN)
2、搭建 NN 结构,从输入到输出(先搭建计算图,再用会话执行)
( NN 前向传播算法 ----》 计算输出)
前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对一组输入给出相应的输出。
3、大量特征数据喂给 NN迭代优化 NN 参数
( NN 反向传播算法 ----》 优化参数训练模型)
训练模型参数,在所有参数上用梯度下降,使 NN 模型在训练数据上的损失函数最小。
4、使用训练好的模型预测和分类 -
神经网络快速搭建:
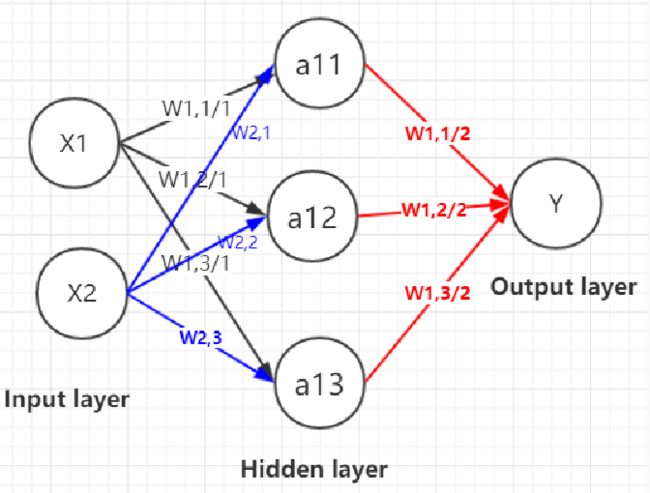
-
如何快速搭建一个卷积神经网络
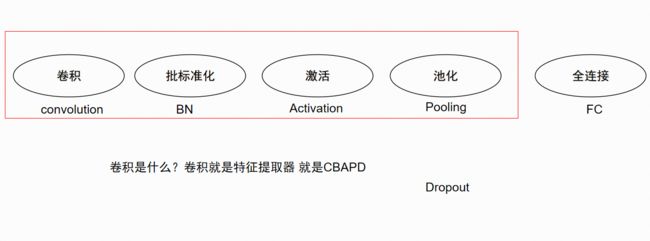
-
参照模型

-
监督学习
监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。 -
学习率
作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
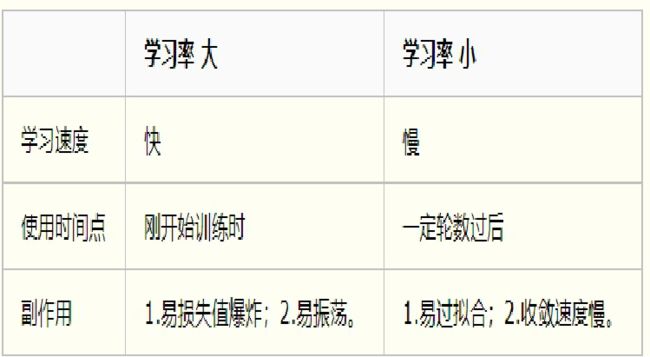

-
过拟合与欠拟合
数据量不够 —> 欠拟合 过程问题 —> 过拟合

-
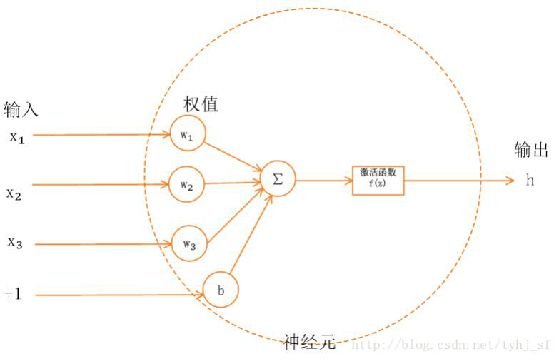
激活函数
在多分类单标签问题中,可以用softmax作为最后的激活层,取概率最高的作为结果;
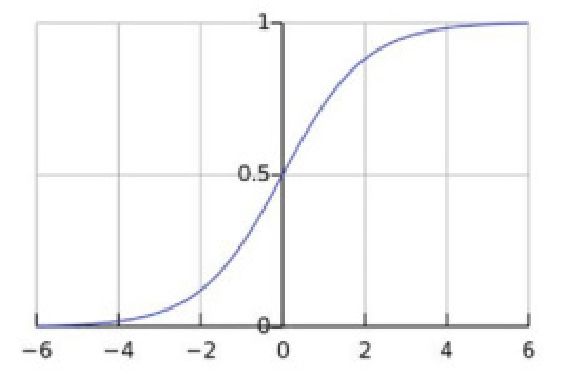
-
损失函数(loss)
用来表示预测值(y)与已知答案(y_)的差距。在训练神经网络时,通过不断改变神经网络中所有参数,使损失函数不断减小,从而训练出更高准确率的神经网络模型。常用的损失函数有均方误差、自定义和交叉熵等。 均方误差 mse:n 个样本的预测值 y 与已知答案 y_之差的平方和,再求平均值。
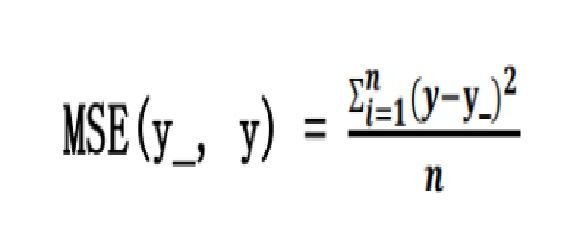
三.实验过程
- 数据收集
收集4位常见中药,分别是白术、大枣、枸杞子、茯苓,并进行数据清洗,图像均为(100,100,3)。确定最终每味药训练集31份,测试集每味4份,图片均来自Google image。
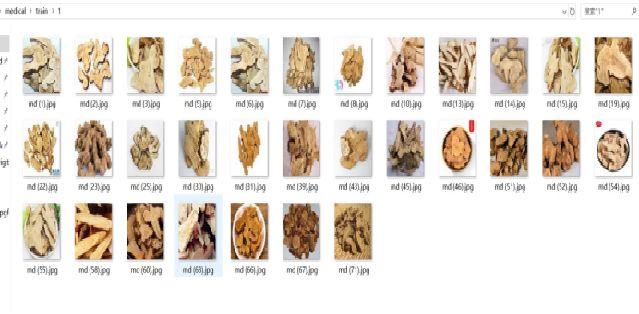
收集白术数据并标记为1
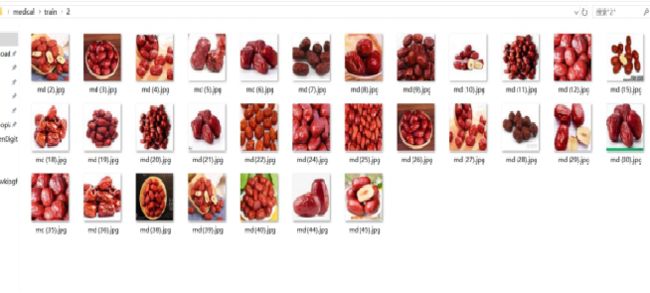
收集大枣数据并标记为2

收集枸杞子数据并标记为3

收集茯苓数据并标记为4
- 代码设计
%% 准备工作空间
clc
clear all
close all
%% 导入数据
digitDatasetPath = fullfile('./', 'train/');
imds = imageDatastore(digitDatasetPath, ...
'IncludeSubfolders',true,'LabelSource','foldernames');% 采用文件夹名称作为数据标记
%,'ReadFcn',@mineRF
% 数据集图片个数,每味31个,确保变量大小、数量一样
countEachLabel(imds)
numTrainFiles = 22;% 每一味中药有31个样本,取22个样本作为训练数据
[imdsTrain,imdsValidation] = splitEachLabel(imds,numTrainFiles,'randomize');
% 查看图片的大小
img=readimage(imds,1);
size(img)
%% 定义卷积神经网络的结构,LeNet-5设计模式
layers = [
% 输入层 输入: 原始的图像像素矩阵(长、宽、色彩), 大小为 100*100*3。
imageInputLayer([100 100 3])
% 卷积层 卷积层参数: 过滤器尺寸为 5*5,深度为 6,不使用全 0 填充,步长为1。
convolution2dLayer(5,6,'Padding',2)
% 批标准化 BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
batchNormalizationLayer
% 激活函数 主要是做非线性变化 ReLu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
reluLayer
% 池化 保留主要的特征同时减少参数(降维)和计算量,防止过拟合,提高模型泛化能力
maxPooling2dLayer(2,'stride',2)
convolution2dLayer(5, 16)
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'stride',2)
convolution2dLayer(5, 120)
batchNormalizationLayer
reluLayer
% 最终层
fullyConnectedLayer(4)
softmaxLayer
classificationLayer];
%% 训练神经网络
% 设置训练参数 使用adam优化器
options = trainingOptions('adam',...
'maxEpochs', 50, ...
'ValidationData', imdsValidation, ...
'ValidationFrequency',9,...
'Verbose',false,...
'Plots','training-progress');% 显示训练进度
% 训练神经网络,保存网络
net = trainNetwork(imdsTrain, layers ,options);
save 'CSNet1.mat' net
%% 标记数据(文件名称方式,自行构造)
mineSet = imageDatastore('./test/', 'FileExtensions', '.jpg',...
'IncludeSubfolders', false);%%,'ReadFcn',@mineRF
mLabels=cell(size(mineSet.Files,1),1);
for i =1:size(mineSet.Files,1)
[filepath,name,ext] = fileparts(char(mineSet.Files{i}));
mLabels{i,1} =char(name);
end
mLabels2=categorical(mLabels);
mineSet.Labels = mLabels2;
%% 使用网络进行分类并计算准确性
% 预测数据
YPred = classify(net,mineSet);
YValidation =mineSet.Labels;
% 计算正确率
accuracy = sum(YPred ==YValidation)/numel(YValidation);
% 绘制预测结果
figure;
nSample=5;
ind = randperm(size(YPred,1),nSample);
for i = 1:nSample
% 运行初始时随机生成权重w和偏置b,经过神经网络隐含层,不断拟合,【就是炼丹】
% 不断反向验证(从后往前调整w,b),不断优化(损失值,调整w,b),直到损失最小输出概率值的过程
% 也可以当调参侠,使用别人的模型,比如迁移学习
subplot(2,fix((nSample+1)/2),i)
imshow(char(mineSet.Files(ind(i))))
title(['预测:' char(YPred(ind(i)))])
if char(YPred(ind(i))) ==char(YValidation(ind(i)))
xlabel(['真实:' char(YValidation(ind(i)))])
else
xlabel(['真实:' char(YValidation(ind(i)))],'color','r')
end
end
- 运行结果
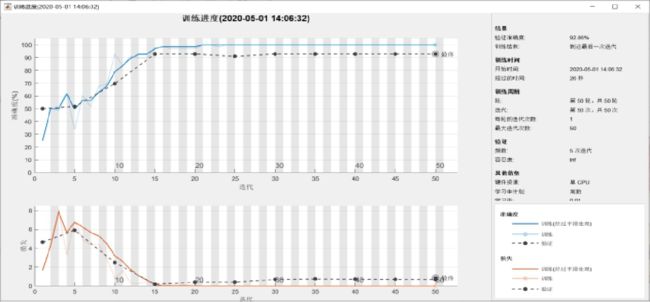
如下图所示,经过50轮,5次迭代,学习率0.01验证集准确率为92.86%,训练结果良好。
- 测试结果
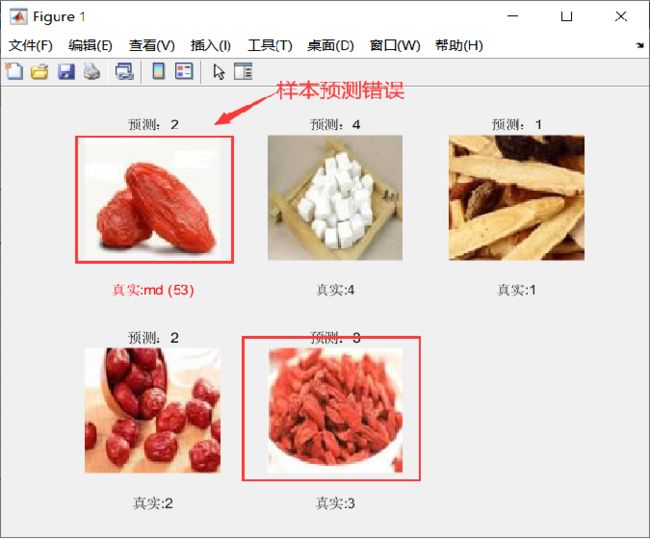
我们根据训练的mat,进行预测,在设置预测样本的时候,选择了一个放大的枸杞子药材,结果意料之内预测成大枣。其余样本均正确。
 ]
] - 实验反思
通过对4种中药有监督的深度学习训练,能得到非常高的准确率是预料范围之内的,毕竟种类少,且药材区分明显;但是将放大的枸杞子药材识别成大枣也是由于算法的局限性和数据量的原因,参考了目前最新的算法是通过opencv+微调进行特征提取再进行分类识别区分效果明显。同时在大规模的中药饮片识别显然LeNet-5是不合适的,用得较多的是opencv+微调+迁移学习(xception,v3)。
四. 写在后面
如果你对我的代码感兴趣,或者想和我做一样的事情,欢迎私聊我,让我们一起为中医药事业奋斗吧。
附录:
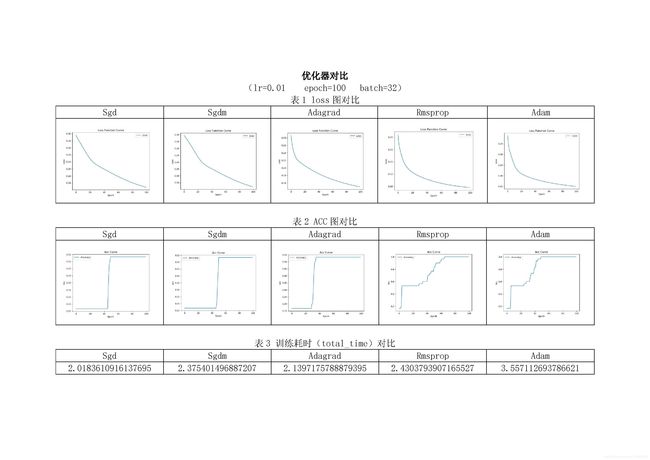
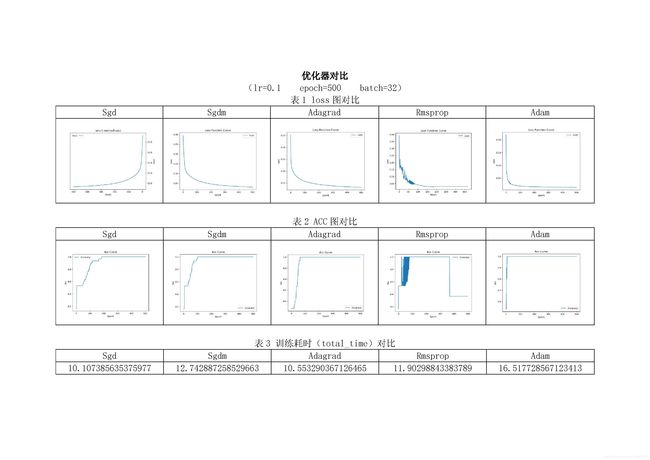
不同学习率,不同优化器的对比
GITHUB开源