python3 爬虫实战案例 (抓取淘宝信息)(淘宝加了搜索必须登录的验证,此方法所到的结果都是0)
需求:对比足球,篮球,乒乓球,羽毛球,网球,相关物品的销售量保存到excle中
和抓取淘宝关键字相关信息的销售量,这和之前抓取csdn网站浏览量取不同,抓取csdn浏览量主要是通过bs4Tag标签,而淘宝的信息都是通过数据js动态生成的,所有通过python抓取的是未经js转换过得源码。如下图

好在我们所需要数据都在页面可以直接看出g_page_config中是页面用来渲染的json数据直接上代码
#爬取taobao商品
import urllib.request
#import pymysql
import re
import pandas as pd
import time
import http.cookiejar
import urllib
#response = opener.open(url)
#cookie.save(ignore_discard=True, ignore_expires=True)
#打开网页,获取网页内容
def url_open(url):
headers=("user-agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
opener=urllib.request.build_opener()
#filename = "cna=5nwpFAEbERgCAXjDQrdTP1Dz; t=f766158a33c167d517e2961c7ebd2113; cookie2=1e56c7ac2b8a135482dda3a225589132; v=0; _tb_token_=f37b33b73a6ee; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; unb=653658897; sg=%E5%95%8A7b; _l_g_=Ug%3D%3D; skt=fc227a63b8e77656; cookie1=Uofl1Kybf%2FPlpA4ncwYjE2Pxp4nkpfoJFgtvM0Og9n0%3D; csg=c2a952b2; uc3=vt3=F8dByRuWs%2By2a6iX%2FjY%3D&id2=VWoinsWLhr4u&nk2=2GGSaaN2CqQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D; existShop=MTUzNzQwOTEwOQ%3D%3D; tracknick=%5Cu8FD8%5Cu597D%5Cu5566%5Cu554A; lgc=%5Cu8FD8%5Cu597D%5Cu5566%5Cu554A; _cc_=W5iHLLyFfA%3D%3D; dnk=%5Cu8FD8%5Cu597D%5Cu5566%5Cu554A; _nk_=%5Cu8FD8%5Cu597D%5Cu5566%5Cu554A; cookie17=VWoinsWLhr4u; tg=0; enc=AEaEWNLOcKhQW2iAZACfi90XustEFxJ0YH5KyimPrnjfOIUTh%2FXKDfmK9xkjzUU62o0j3Asj%2BTWWeF0DqKXjgg%3D%3D; alitrackid=login.taobao.com; lastalitrackid=login.taobao.com; mt=ci=65_1; swfstore=257129; uc1=cookie16=V32FPkk%2FxXMk5UvIbNtImtMfJQ%3D%3D&cookie21=UtASsssme%2BBq&cookie15=VFC%2FuZ9ayeYq2g%3D%3D&existShop=false&pas=0&cookie14=UoTfLJFJ%2F0HdMg%3D%3D&tag=8&lng=zh_CN; isg=BIGB_p7DvnOEjdOh4wKbN48WkM1bBveBbdkzWOPWfQjnyqGcK_4FcK_IqH4pQo3Y; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; whl=-1%260%260%261537411994033; JSESSIONID=12F73C6E6DAA8858A9D82913BB8880DD"
#cookie = http.cookiejar.MozillaCookieJar(filename)
#handler = urllib.request.HTTPCookieProcessor(cookie)
#opener = urllib.request.build_opener(handler)
opener.addheaders=[headers]
urllib.request.install_opener(opener)
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
return data
#将数据存入mysql中
def data_Import(sql):
conn=pymysql.connect(host='127.0.0.1',user='test',password='123456',db='python',charset='utf8')
conn.query(sql)
conn.commit()
conn.close()
# 文件存储
def text_save01(content, filename, mode='a'):
# Try to save a list variable in txt file.
file = open(filename, mode,encoding='utf-8')
file.write(content)
file.close()
# 文件存储Excel
def setExcle(goodsName,seller,sale,city):
########################数据框#################################################
data=pd.DataFrame({'商品名称':goodsName,"价格":seller,"销量":sale,"城市":city})
#print data
# 写出excel
############################文件名称记得修改######################################################
writer = pd.ExcelWriter(r'C:\\taobao'+listb[drnIndex]+'.xlsx', engine='xlsxwriter', options={'strings_to_urls': False})
data.to_excel(writer, index=False)
writer.close()
def setExcleCount(goodsName,sale):
########################数据框#################################################
data=pd.DataFrame({'商品名称':goodsName,"销量":sale,})
#print data
# 写出excel
############################文件名称记得修改######################################################
writer = pd.ExcelWriter(r'C:\\taobao.xlsx', engine='xlsxwriter', options={'strings_to_urls': False})
data.to_excel(writer, index=False)
writer.close()
goodsName=[]
seller=[]
sale=[]
citys=[]
drnIndex=0
salesAllArr=[]
if __name__=='__main__':
#try:
#定义要查询的商品关键词
listb=["足球","篮球","乒乓球","羽毛球","网球"]
for drnIndex in range(len(listb)):
keywd=listb[drnIndex]
keywords=urllib.request.quote(keywd)
print(keywd)
#定义要爬取的页数
num=100
goodsName=[]
seller=[]
sale=[]
citys=[]
for i in range(num):
if float (i)>float(num):
break
#print('正在爬取第'+str(i)+"页...")
url="https://s.taobao.com/search?q="+keywords+"&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180920&ie=utf8&style=grid&sort=sale-desc&s="+str(i*44)
data=""
drnT=0
##由于淘宝有防抓取机制,访问经常访问不到,所有增加循环强行访问
while len(data)<100 and drnT<999999:
drnT=drnT+1
try:
data=url_open(url)
except:
print("-------"+keywd)
continue
#print(len(data));
#打印下请求到页面信息请求了几遍
print(drnT);
print("**************"+str(i))
#定义各个字段正则匹配规则
img_pat='"pic_url":"(//.*?)"'#商品图片
name_pat='"raw_title":"(.*?)"'#商品名字
nick_pat='"nick":"(.*?)"'#淘宝店铺名称
price_pat='"view_price":"(.*?)"'#商品价格
fee_pat='"view_fee":"(.*?)"'#运费
sales_pat='"view_sales":"(.*?)人收货'#收货人数
comment_pat='"comment_count":"(.*?)"'#商品评论数,
city_pat='"item_loc":"(.*?)"'#淘宝店所在城市
detail_url_pat='detail_url":"(.*?)"'#商品详细地址
totalPage='totalPage":(.*?),'#商品总页数
#查找满足匹配规则的内容,并存在列表中
if i==0:
totalPageNum=re.compile(totalPage).findall(data)
if len(totalPageNum):
num=totalPageNum[0]
else:
num=100;
#imgL=re.compile(img_pat).findall(data)
nameL=re.compile(name_pat).findall(data)
#nickL=re.compile(nick_pat).findall(data)
priceL=re.compile(price_pat).findall(data)
#feeL=re.compile(fee_pat).findall(data)
salesL=re.compile(sales_pat).findall(data)
#commentL=re.compile(comment_pat).findall(data)
cityL=re.compile(city_pat).findall(data)
#detail_urlL=re.compile(detail_url_pat).findall(data)
j=0;
for j in range(len(nameL)):
#img="http:"+imgL[j]#商品图片链接
#name=nameL[j]#商品名称
#goodsName.append(name);
#nick=nickL[j]#淘宝店铺名称
#price=priceL[j]#商品价格
#seller.append(price)
#fee=feeL[j]#运费
try:
sales=salesL[j]#商品付款人数
except:
sales=0
sale.append(sales)
#detail_url=detail_urlL[j]#商品链接
#comment=commentL[j]#商品评论数,会存在为空值的情况
#if(comment==""):
# comment=0
#city=cityL[j]#店铺所在城市
#citys.append(city)
#print('第'+str(i)+"页,第"+str(j)+"个商品信息..."+name+"以结束")
#text_save01((name+"---有"+sales+""),"taobao.txt");
salesAll=0
#统计总数
for saleSign in range(len(sale)):
salesAll=salesAll+int(sale[saleSign])
salesAllArr.append(str(salesAll))
print(listb[drnIndex]+":"+salesAllArr[drnIndex])
#分条打印进入excle,并且每个内容一个文件
#setExcle(goodsName,seller,sale,citys)
#只打印总条数打印到excle
setExcleCount(listb,salesAllArr)
print("任务完成")
如果运行中出现No module named "xxx",就直接pip install xxx,就可以了。
对安装pip有疑问可以看之前的文章:
https://blog.csdn.net/ruiti/article/details/78870004
写的很详细。希望对你有用
补:淘宝做了修复,应该是存token之类的验证,复制地址如果浏览器没有打开过淘宝直接跳转搜索页面https://s.taobao.com/search?q=足球&imgfile=&js=1&style=list&stats_click=search_radio_all:1&initiative_id=staobaoz_20181211&ie=utf8,现在会跳到登录页,拿到的也都是登录页的页面数据,正则查找自然全都是0。
之前连续访问淘宝会不返回信息,所以我加了while,发现返回的数据短就继续获取,,,
现在跳转login,如果想要让他不跳转login,那么就需要把页面需要的数据在跳转的时候传给他,应该就是RequestHeaders 中的cookie信息,先通过页面,从请求信息中拿到cookie复制,在查询时传过去,会有点麻烦。后期有时间在进下添加。
这个cookie 是要先登录,然后搜索,然后F12或鼠标右键检查,NetWork,,看下图cookie
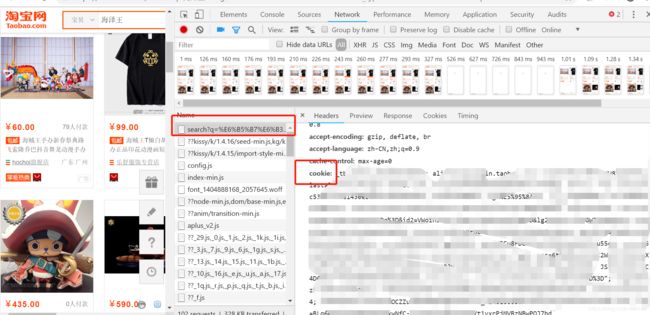
找了几个链接,供学习https://www.cnblogs.com/lsdb/p/9071015.html
https://www.jianshu.com/p/a5460bc773c8