【实例分割论文】 SOLO:Segmenting Objects by Locations(更新代码)
===========更新 2020/3/28=========
作者源代码已经开源,因此更新了结合作者源代码分析的网络实现部分;
此外,SOLO v2论文已经发布 https://arxiv.org/abs/2003.10152,
=================================
论文名称:《SOLO: Segmenting Objects by Locations》
论文链接:https://arxiv.org/abs/1912.04488
参考代码:https://github.com/WXinlong/SOLO
目录
综述
背景介绍
总体思路
位置(location)
尺寸(size)
网络实现
FPN
Category Branch
Mask Branch
操作流程(附源代码)
后处理
实验结果
Decoupled SOLO
综述
作者提出了一种非常简单、直接的实例分割方法。通过引入“实例类别”这一概念,将实例分割的问题转化为两个分类问题。实例类别则是根据实例中的每一个像素的位置和尺寸来确定标签的,思路非常巧妙。作者提出的模型精度不错,在COCO上超越了Mask R-CNN和其他单阶段实例分割模型,但思路是我觉得最值得follow的。
背景介绍

实例分割(Instance Segmentation)是视觉四任务中相对最难的一个,它既具备语义分割(Semantic Segmentation)的特点,需要做到像素层面上的分类,也具备目标检测(Object Detection)的一部分特点,即需要定位出不同实例,即使它们是同一种类物体。因此,实例分割的研究长期以来都依赖较为复杂的两阶段的方法,两阶段方法又分为两条线,分别是自下而上的基于语义分割的方法和自上而下的基于检测的方法。
自上而下的实例分割方法的思路是:首先通过目标检测的方法找出实例所在的区域(bounding box),再在检测框内进行语义分割,每个分割结果都作为一个不同的实例输出。
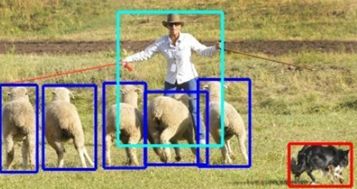
自下而上的实例分割方法的思路是:首先进行像素级别的语义分割,再通过聚类、度量学习等手段区分不同的实例。

作者认为,这些两阶段方法都是step-wise和indirect的,因此提出疑问,实例分割与语义分割为何在解决方法上相差如此之大?是否有办法更加简单地完成实例分割?
总体思路
这里引用作者的回答来理解作者的动机与思路。
SOLO的出发点很简单,怎么样简单直接的做实例分割?语义分割和实例分割,大家都是分割,为什么解决起来大相径庭?
语义分割,其实就是逐像素的语义类别分类:预测每个像素所在的物体的语义类别。类比下来,是不是可以进行逐像素的实例类别分类:预测每个像素所在的物体的实例类别。
那么核心问题就是, 什么是物体的实例类别?物体的语义类别是由人为的定义来区分的,是由人来标注的。那图片里物体的什么属性可以用来区分实例呢?—— 位置和形状。
如果一张图片里出现的两个物体,位置和形状完全一样,那这就是同一个实例。两个不同的实例,位置或者形状不一样。这里指的广义的形状:包括尺寸,角度,这些和位置无关的,每个物体都有的属性。由于泛泛的形状不好描述,我们采用尺寸来近似替换。
要理解本文的思想,重点就是要理解SOLO提出的实例类别(Instance Category)的概念。作者指出,实例类别就是量化后的物体中心位置(location)和物体的尺寸(size)。下面就解释一下这两个部分。
位置(location)
SOLO将一张图片划分S×S的网格,这就有了S*S个位置。不同于TensorMask和DeepMask将mask放在了特征图的channel维度上,SOLO参照语义分割,将定义的物体中心位置的类别放在了channel维度上,这样就保留了几何结构上的信息。
本质上来说,一个实例类别可以去近似一个实例的中心的位置。因此,通过将每个像素分类到对应的实例类别,就相当于逐像素地回归出物体的中心、这就将一个位置预测的问题从回归的问题转化成了分类的问题。这么做的意义是,分类问题能够更加直观和简单地用固定的channel数、同时不依赖后处理方法(如分组和学习像素嵌入embedding)对数量不定的实例进行建模。
尺寸(size)
对于尺寸的处理,SOLO使用了FPN来将不同尺寸的物体分配到不同层级的特征图上,依次作为物体的尺寸类别。这样,所有的实例都被分别开来,就可以去使用实例类别去分类物体了。
网络实现
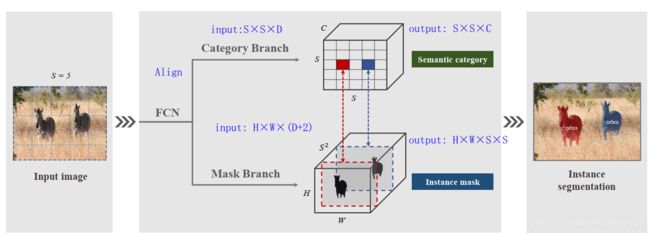
SOLO将图片划分成S×S的网格,如果物体的中心(质心)落在了某个网格中,那么该网格就有了两个任务:(1)负责预测该物体语义类别(2)负责预测该物体的instance mask。这就对应了网络的两个分支。
FPN
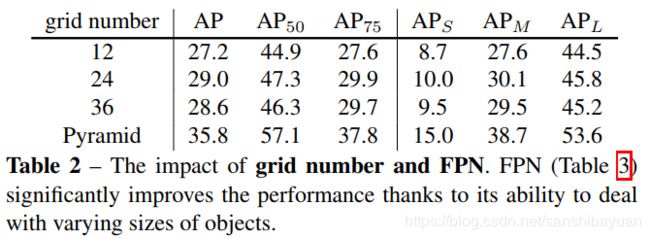
SOLO在骨干网络后面使用了FPN,用来应对尺寸。FPN的每一层后都接上述两个并行的分支,进行类别和位置的预测;同时,FPN每个层级接的分支的网格数目也按照金字塔的形式变化(P2->P6, 40,36,,24,16,12),实现了多尺度预测(multi level prediction)。
消融实验证明,单一尺度的SOLO已经有了不错的检测精度(27.2 ap),但加入了FPN多尺度预测后的提升巨大。
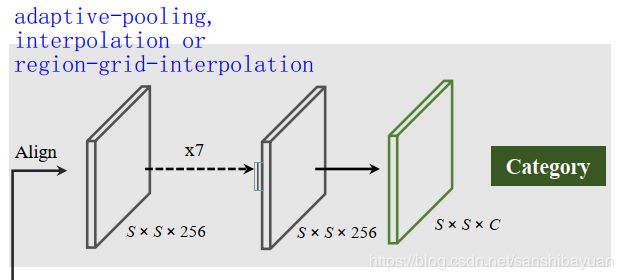
Category Branch
Category Branch负责预测物体的语义类别,每个网格预测类别S×S×C,这部分跟YOLO是类似的。输入为Align后的S×S×C的网格图像,输出为S×S×C的类别。这个分支使用的损失函数 ![]() 是focal loss。
是focal loss。
那如何设计标签呢?当网格(i,j)与物体的中心区域有大于阈值的重叠则认为是正样本。这里的中心区域定义在中心点(这里定义的中心点是物体的质心)周围的![]() 倍区域(来源于center sampleing)。对于每个正样本,都会有对应类别的instance mask,这就由后面的Mask Branch来预测。
倍区域(来源于center sampleing)。对于每个正样本,都会有对应类别的instance mask,这就由后面的Mask Branch来预测。
此外,Category Branch需要将H*W的输入调整为S*S的网格输入,因此需要用到插值。作者实验了三种方法:直接插值、adpative pooling和区域网格插值,效果都差不多。
Mask Branch
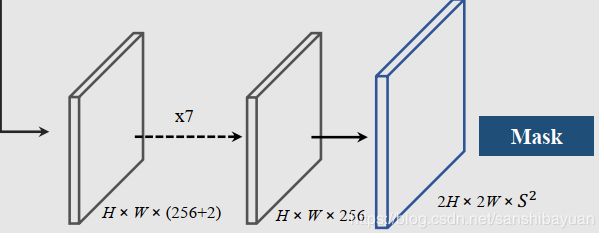
每个正样本(有类别输出的网格)都会输出对应类别的instance mask,这里的通道channel和网格的对应关系是:第k个通道负责预测出第(i,j)个网格的instance mask,k = i*S+j。因此输出维度是H×W×S×S 。这样的话就有了一一对应的语义类别和class-agnostic的instance mask。
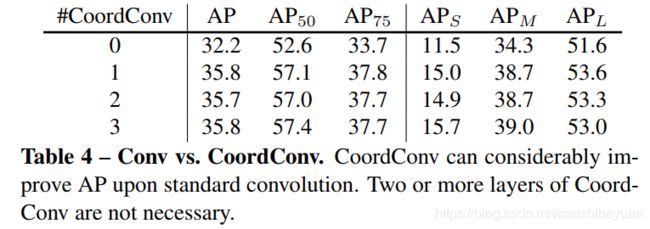
预测instance mask的一个直观方法是类似语义分割使用FCN,但FCN是具有空间不变性(spatiallly invariant)的,而我们这边需要位置上的信息。因此,作者使用了CoordConv,将像素横纵坐标x,y(归一化到[-1,1])与输入特征做了concat再输入网络中。这样输入的维度就是 H*W*(D+2)了。
消融实验证明,一个的CoordConv就能带来3.6的ap提升,说明CoordConv的存在确实融入了位置变化信息。更多的CoordConv反而提升不大。
在这个分支中,损失函数为 ![]() 。针对d_mask,作者尝试了三种计算GT和预测mask像素的损失函数:Binary Cross Entropy (BCE), Focal Loss 和 Dice Loss,最终选择了Dice Loss。最后网络的总损失就是
。针对d_mask,作者尝试了三种计算GT和预测mask像素的损失函数:Binary Cross Entropy (BCE), Focal Loss 和 Dice Loss,最终选择了Dice Loss。最后网络的总损失就是 ![]()
消融实验证明,Focal Loss的效果要比BCE好,原因是实例mask中的大部分像素属于背景(负样本);然而,Dice Loss在无需调参的情况下取得了更好的效果。,

操作流程(附源代码)
SOLO的两个分支光看论文可能会比较迷糊,还好作者昨天开源了源代码,通过代码可以更加清晰地了解head部分的操作流程。总结如下:
(1)首先经过backbone网络和FPN,得到不同层级的图像特征;
(2)对于Category分支,首先将FPN最高层的特征从H×W×256对齐至S×S×256(256为特征通道数),然后经过一系列卷积(7个3×3卷积)提取特征,最后再经过一个3×3卷积将输出对齐到S×S×C(C为预测类别-1);
# cate branch
for i, cate_layer in enumerate(self.cate_convs):
if i == self.cate_down_pos:
seg_num_grid = self.seg_num_grids[idx]
cate_feat = F.interpolate(cate_feat, size=seg_num_grid, mode='bilinear')
# 将FPN最高层的特征从H*W*feat_channel 对齐到 S*S*feat_channel
cate_feat = cate_layer(cate_feat) # 7个卷积
cate_pred = self.solo_cate(cate_feat) # 从 S*S*feat_channel 到 S*S*num_classes(3)对于Mask分支,首先对FPN最高层的特征做一个CoordConv,然后同样经过一系列卷积(7个3×3卷积)提取特征,此时维度为H×W×256,再做一步上采样至2H×2W×256,最后就是对齐到2H×2W×S^2的输出(Decoupled SOLO此处则为2H×2W×S)
# ins branch
# concat coord
x_range = torch.linspace(-1, 1, ins_feat.shape[-1], device=ins_feat.device)
y_range = torch.linspace(-1, 1, ins_feat.shape[-2], device=ins_feat.device)
y, x = torch.meshgrid(y_range, x_range)
y = y.expand([ins_feat.shape[0], 1, -1, -1])
x = x.expand([ins_feat.shape[0], 1, -1, -1])
coord_feat = torch.cat([x, y], 1)
ins_feat = torch.cat([ins_feat, coord_feat], 1) # CoordConv
for i, ins_layer in enumerate(self.ins_convs): # 7个3*3 Conv 提取特征
ins_feat = ins_layer(ins_feat) # H*W*feat_channel
ins_feat = F.interpolate(ins_feat, scale_factor=2, mode='bilinear') # 上采样到2H*2W*feat_channel
ins_pred = self.solo_ins_list[idx](ins_feat)
# 从2H*2W*feat_channel到2H*2W*(S^2) S^2的复杂度,这里也是Decoupled 和 Solo v2的优化之处后处理
有了上面两个任务,接下来就是完成实例分割任务,得到最终的实例分割结果。很自然的,最终的结果就是所有网格的instance mask(即输出的每个通道)叠加的结果。最后再使用NMS过滤掉,不需要其他的后处理手段。

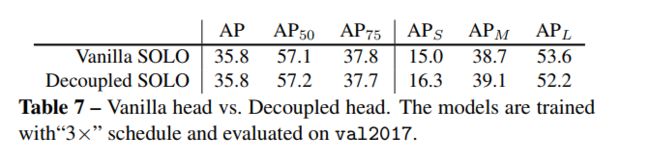
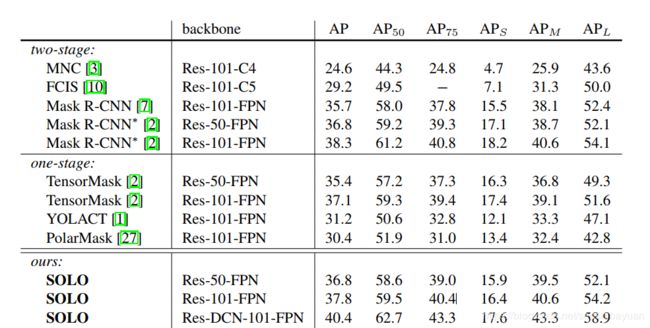
实验结果
可以看到,SOLO的精度已经超越了Mask R-CNN,相较思路类似的PolarMask也有较大的优势。
Decoupled SOLO
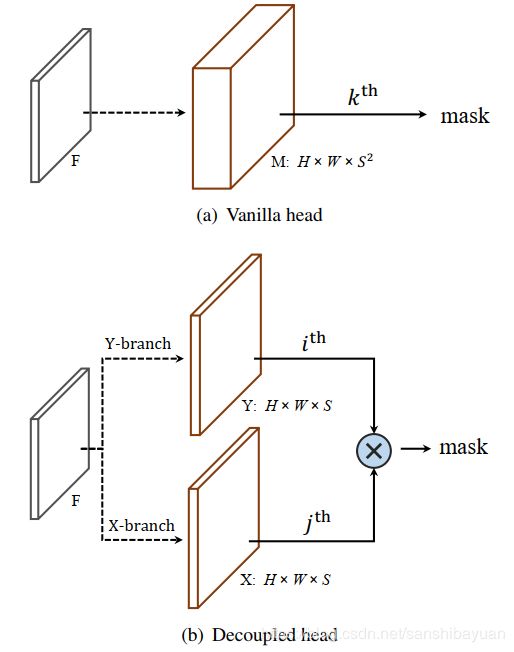
原始的SOLO对于 S×S的网格需要S×S的输出通道,这对计算量是比较大的要求,但其实图片中通常并不会有这么多的实例,这里头有很多通道是多余的。因此,作者提出了更有效率的变种Decoupled SOLO。
通过将原始的输出![]() 替换成了
替换成了 ![]() 和
和 ![]() 的element-wise multiplication,Decoupled SOLO将输出通道降成了S+S,大大降低了输出的维度和所需的GPU内存,同时精度上没有损失。
的element-wise multiplication,Decoupled SOLO将输出通道降成了S+S,大大降低了输出的维度和所需的GPU内存,同时精度上没有损失。