Python数据分析 | (8)NumPy数组的索引和切片
本篇博客所有示例使用Jupyter NoteBook演示。
Python数据分析系列笔记基于:利用Python进行数据分析(第2版)
目录
1.基本的索引和切片
2.切片索引
3.布尔型索引
4.花式索引
5.花式索引的等价函数
1.基本的索引和切片
NumPy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式很多。
- 一维数组
一维数组很简单,表面上和Python列表的功能差不多:
import numpy as np
arr = np.arange(10)
print(arr)
print(arr[5])
print(arr[5:8]) #切片 访问第5-7个位置的元素(从0开始)
arr[5:8] = 12 #对切片进行赋值 广播 该值会传播到整个选区
print(arr)
数组和列表最重要的区别是,数组切片是原始数组的视图(指向同一块内存),列表的切片是原始列表的一个副本(指向不同的内存,内存中的值相同)。这意味着数据不会被复制,视图上的任何修改都会直接反应到源数组上。
#列表
l = [1,2,3,4,5]
l_slice = l[3:5] #列表不支持广播操作 数组有广播操作
l_slice[0] = 100 #对列表切片进行修改 不会影响原始列表 列表的切片是原始列表的副本 指向不同内存
print(l_slice)
print(l)
print("-----------------------")
#数组
arr_slice = arr[5:8]
print(arr)
print(arr_slice)
print("**")
arr_slice[0] = 10000 #对数组切片进行修改 会影响原始数组 数组的切片是原始数组的视图 指向同一块内存
print(arr)
print(arr_slice)
print("**")
arr_slice[:] = 12345 #数组支持广播 [:]全切片 对所有值进行赋值
print(arr)
print(arr_slice)
由于NumPy的设计目的是处理大数据,所以假如NumPy坚持要将数据复制来复制去的话会产生何等性能和内存问题。如果你想要得到的是ndarray切片的一份副本而不是视图,需要明确的进行复制操作:
print(arr)
arr_slice = arr[0:3].copy() #使用copy() 切片是数组的副本
arr_slice[0] = -100000 #对切片进行修改 不影响原始数组
print(arr)
- 高维数组
对于高维数组,能做的事情更多。在一个2维数组中,各索引位置上的元素不再是标量而是一个一维数组:
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(arr2d[0])
#可以对各个元素进行递归访问 以下两种方式等价
print(arr2d[0][2])
print(arr2d[0,2]) #以逗号隔开的索引列表 ,前对第一维取值 后对第2维取值
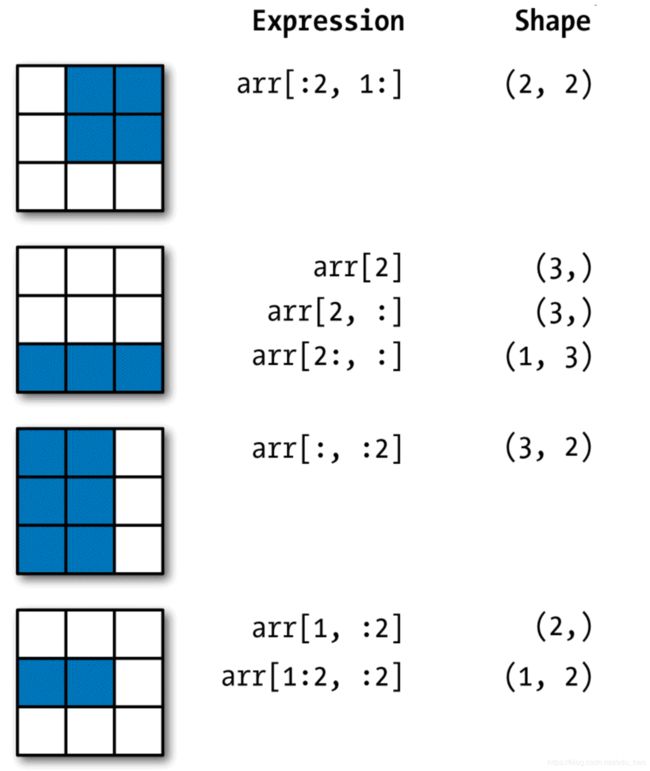
下图说明了2维数组的索引方式:
在高维数组中如果省略了后面的索引,则返回对象会是一个维度低一点的ndarray:
arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]]) #三维数组 2*2*3
print(arr3d)
print(arr3d[0]) #2*3的2维数组
print("------------")
old_value = arr3d[0].copy()
arr3d[0] = -100 #可以把标量赋给arr3d[0]
print(arr3d)
arr3d[0] = old_value #也可以把数组赋值arr3d[0]
print(arr3d)
相似的,arr3d[1,0] 可以访问索引以(1,0)开头的值,以一维数组的形式返回:
#以下几种方式等价
print(arr3d[1,0])
print(arr3d[1][0])
#分步访问
x = arr3d[1]
print(x)
print(x[0])
注意,选取数组子集(切片)的例子,返回的都是数组的视图,可以使用copy()返回副本。
2.切片索引
ndarray的切片语法和Python列表这样的一维对象差不多:
print(arr)
print(arr[1:6]) #不包含结尾 位置1-5 (从0开始)
print(arr[1:6:2]) #可以设置步长 (start,end,step) 默认步长为1
print(arr[-1]) #也可以使用负索引 总之和列表的索引方式基本相同
对于之前的2维数组arr2d,切片方式略有不同:
print(arr2d)
print(arr2d[:2]) #2维数组沿0轴切片 可以看作取前两行
print(arr2d[:2,1:]) #可以传入多个切片 和传入多个整数索引一样 可以看作取前两行和第1列之后的所有列 相交的部分
print("-------------------")
#整数索引和切片可以混合使用
print(arr2d[1,:2]) #第2行的前两列
print(arr2d[:2,2]) #第三列的前两行
print("-------------------")
#只有:是取整个轴
print(arr2d[:]) #取所有元素
print(arr2d[:,1]) #取第一列

注意对数组的整数索引和切片索引都是返回数组的视图。
自然对切片表达式的赋值会被扩散到整个选区(广播):
print(arr2d)
arr2d[:2,1:] = 0
print(arr2d)
3.布尔型索引
假设有一个用于存储数据的数组以及一个存储姓名的数组(有重复项).
name = np.array(['bob','joe','will','bob','will','joe','joe'])
data = np.random.randn(7,4)
print(name)
print(data)
print("------------------")
#假设每个名字对应data数组的中一行
#和算术运算一样,数组的比较运算也是矢量化的
#选出对应bob的data中的所有行
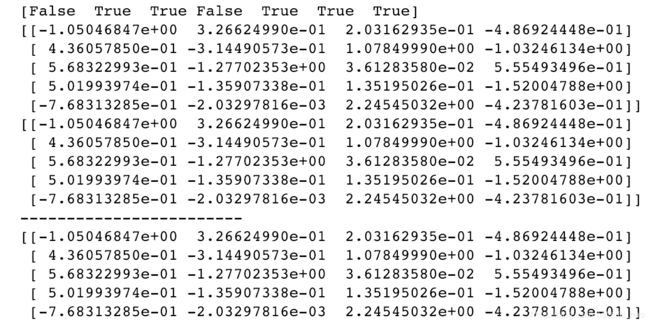
print(name == 'bob') #返回一个布尔数组
print(data[name=='bob']) #布尔数组可以用于数组索引
布尔型数组的长度必须跟被索引的轴长度一致。此外还可以将布尔型数组和切片、整数索引或整数序列(之后讲)混合使用.
注意,如果布尔型数组的长度不对,布尔型选择就会出错,因此使用时一定小心。
print(data[name == 'bob',2:]) #用布尔型数组对0轴(行)进行索引,用切片对1轴(列)索引
print(data[name == 'bob',3]) #用布尔型数组对0轴(行)进行索引,用整数对1轴(列)索引
要选择除‘bob’之外的其他值,既可以使用!=,也可以通过~对条件进行否定:
print(name!='bob')
print(data[name!='bob'])
print(data[~(name=='bob')])
print("------------------------")
cond = name=='bob'
print(data[~cond])
组合应用多个布尔条件使用&,|之类的布尔运算符即可:
mask = (name=='bob') | (name=='will')
print(mask)
print(data[mask])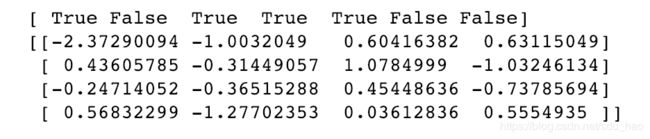
通过布尔型索引选取数组中的数据,和整数索引和切片索引不同,总是创建数据的副本,即使返回一摸一样的数组也是如此。
arr = np.array([1,-1,1])
a = arr[arr<0] #a是arr的副本 不是视图 和整数和切片索引不同
print(a)
a[0] = 100
print(a)
print(arr)
print("-------------")
b = arr[arr>-2]
print(b)
b[:] = 10000
print(b)
print(arr)
注意Python关键字and or在布尔型数组中无效,要使用&,|。
通过布尔型数组索引设置值是一种常用的手段:
print(data)
data[data<0] = 0 #把data数组中小于0的值 设置为0
print(data)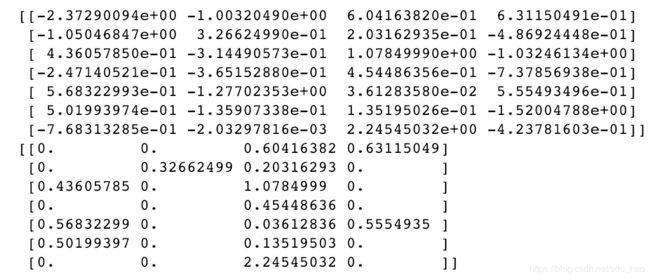
通过一维布尔数组设置整行/列的值也很简单:
print(data)
data[name!='joe'] = 7 #用一维布尔数组name!=‘joe’ 索引data数组的0轴(行) 0轴长度与一维布尔数组长度要相等
print(data)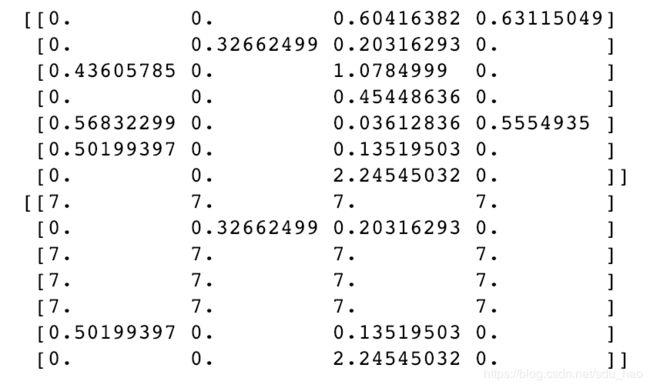
之后我们会学习到,这类2维数据的操作也可以用pandas更方便的来做。
4.花式索引
花式索引(Fancy indexing)是一个NumPy术语,指的是利用整数数组进行索引。
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
print(arr)
以特定顺序选取行子集,只需要传入一个用于指定顺序的整数列表或数组即可:
print(arr[[4,3,0,6]])
print(arr[[-3,-5,-7]]) #也可以使用负数索引
一次传入多个索引数组会有一些特别,返回一个一维数组,其中的元素对应各个索引元素:
arr = np.arange(32).reshape((8,4))
print(arr)
print(arr[[1,5,7,2],[0,3,1,2]]) #,前对0轴索引 ,后对1轴索引 返回一维数组 包含(1,0) (5,3) (7,1) (2,2)
无论数组是多少维,花式索引总是一维的。
print(arr)
print(arr[[1,5,7,2]])
print(arr[[1,5,7,2]][:,[0,3,1,2]])
花式索引(整数数组/列表)可以和之前的整数索引、切片索引以及布尔型数组索引混合使用。
注意花式索引和布尔型数组索引相似,和切片/整数索引不同,赋给新数组的话,新数组是原数组的副本而不是视图:
brr = arr[[1,5]]
brr[:] = 10000
print(arr)
print("-------------")
arr[[1,5]] = 2
print(arr)
5.花式索引的等价函数
获取和设置数组子集的一个办法是可以把整数数组/列表作为数组的花式索引:
arr = np.arange(10)*100
inds = [7,1,4,2]
arr[inds]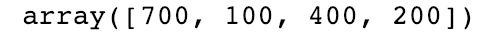
ndarray还有其他方法用于获取单个轴向上的选区:
print(arr.take(inds))
print(arr)
arr.put(inds,-333)
print(arr)
arr.put(inds,[-1,-2,-3,-4])
print(arr)
在其他轴上使用take时,只需要传入axis关键字即可:
inds = [2,0,2,1]
arr = np.random.randn(2,4)
print(arr)
print(arr.take(inds,axis=1)) 
put不接受axis参数,它只会在数组的扁平化版本(一维,C顺序)上进行索引。因此,在需要用其他轴向索引设置元素时,最好使用花式索引。