HashMap与ArrayMap(和SparseArray)的比较与选择
HashMap之外的Map实现
HashMap应该是java中使用最多的Map实现了,ArrayMap为Android SDK提供的另一个Map接口的实现。
SparseArray的实现思路和ArrayMap是一致的,所以捎上说一下
补充说明
ArrayMap在v4包中有兼容的实现,需要兼容低版本不要导错包
android.util.ArrayMap
android.support.v4.util.ArrayMap
HashMap的实现
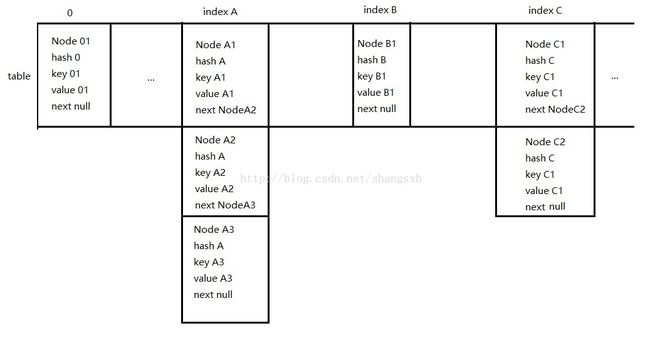
HashMap是通过数组+链表的形式存储数据,内部有一个名为table的Node类型的数组用以存放数据,每一个Node都可以向后构成一个单向链表,用于在hash重复而key不相同时保存新的键值对
Node类的结构:
static class Node<K,V> implements Entry<K,V>{
final int hash; //key对象的hashCode值
final K key; //key对象
V value; //value对象
Node next; //指向下一个Node对象的引用
} HashMap通过Key对象的hashCode方法返回int型hash值,经过系列计算在数组中的下标。
下面分析一下hash->index的转换过程
Key对象->table下标转换
第一步,调用key对象的hashCode方法获取int值
通过Key对象的hashCode方法,获取int型的Hash值,如果key对象为null则为0。
这里就涉及到了HashMap和HashTable的一个区别:HashMap允许null Key而HashTable不允许。这是因为HashTable直接调用了Key对象的hashCode方法而缺少了null时的判断。
将”HashMap通过key对象的hashCode方法获取的int型hash值”起名为hash,后面提到hash均为此。
在Key对象为null时直接赋值为0进行第三步,不为0时多则进行第二步对hash修正
第二步,对hash修正
hash = hash ^ (hash>>>16)将hash和自己的高16位xor。为什么多了这一步的操作的原因在下一步操作中说。
第三步,hash->数组下标转换
如何保证计算出来的下标一定在数组长度范围内?最简单的方法就是hash%table.length,取余的结果一定在[0,table.length)区间内,这也是HashTable使用的方法。
但是计算机中除法和取余运算是最慢的,而位运算是最快的,所以HashMap使用位运算来转换,这也是为什么HashMap的table长度一定是2n的原因。
我们知道2n对应的二进制是1后面n个零,以HashMap的table默认初始长度16为例,此时数组长度24对应二进制是
10000
减1可以得到
01111
index = 01111&hash,位与得到的结果index一定<=01111,也就是一定在[0,table.length)区间内。
HashMap用位运算实现了和HashTable取余同样的效果(注意这里是等效不等价的),这也是除了同步锁以外HashMap比HashTable效率高的另外一个原因。HashTable中hash值到index转换是
index = (hash&0x7FFFFFFF)%table.length 使用符号位后和table.length取余,HashMap的位运算自然要比HashTable的取余运算效率高。
对第二步hash修正的说明
说回第二步中对hash的修正,hashCode方法返回的原始hash值存在一种可能,大部分1都在高位,此时数组又比较小的话,直接用原始hash值和table.length-1位与可能会丢掉太多1,导致hash大量碰撞,所以将高16位无符号右移并与低16位异或,这是为了让高16位在数组长度比较小的情况下也能参与计算,降低hash碰撞概率
存取
获取到数组下标后可以获取对应位置的数组元素了,如果为空则表示不存在,可以直接存放新值。如果不为空就是Node链表的头节点,此时需要遍历Node对象,通过Key对象的equals检查是否相符。增删特性和链表相同不再细说。
ArrayMap的实现
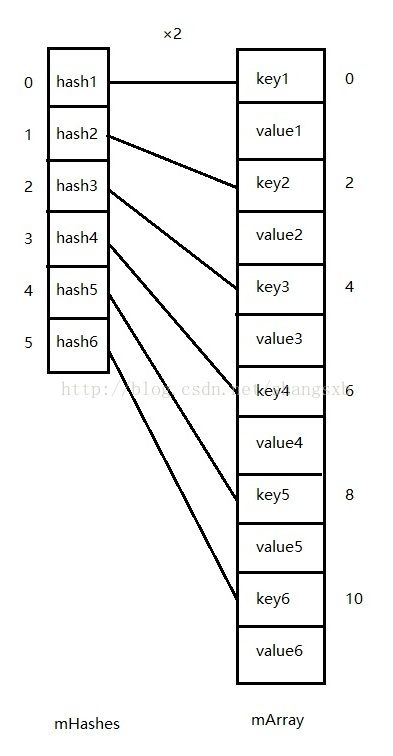
ArrayMap内部通过两个数组保存映射关系,其中int[] mHashes按大小顺序保存Key对象hashCode值,Object[] mArray按mHashes的顺序y用相邻位置保存Key对象和Value对象。可以发现ArrayMap使用一个数组同时保存key和value对象,所以mArray长度一定是mHashes长度的2倍,通过两个数组的初始化代码也能看出
mHashes = new int[size];
mArray = new Object[size<<1]; ArrayMap相对于HashMap,无需为每个键值对创建Node对象,并且在数组中连续存放,这就是为什么ArrayMap相对HashMap要节省空间。
ArrayMap也是通过Key对象的hashCode方法返回int型hash值,通过一系列计算获取对应在数组中的下标。下面分析ArrayMap中hash->index的转换过程
Key对象->mArray下标转换
第一步,调用key对象的hashCode方法获取int值
通过Key对象的hashCode方法,获取int型的Hash值,如果key对象为null则为0。这里和HashMap是完全一样的。
和之前一样,将”key对象的hashCode方法获取的int型hash值“起名为hash
第二步,通过二分法查找获取hash在mHashes数组中的下标index
mHashes中的hash值是按照有小到大的顺序(自然排序)连续摆放的,通过binarySearch获取对应hash的下标index,去mArray中查找键值对
第三步,mHashes下标查找mArray键值对
mHashes中的index*2即为mArray中的Key下标,index*2+1为Value的下标。由于存在hash碰撞的情况,而二分法查找到下标可能是多个连续相同hash值中的任意一个,所以此时需要用equals比对对命中的Key对象是否相符,不相符时,从当前index先向后再向前遍历所有相同hash值。
存取
由于是用数组中连续位置存放的,数组各元素中没有空余位置,空间占用更优。最好的情况时在最尾部增删,如果在中间增删则需要移动数组元素,这里和ArrayList原理相同不再细说。
index是通过二分法查找或者向后遍历获取的,插入时可以直接使用。
SparseArray
SparseArray和ArrayMap的实现原理是完全一样的,都是通过二分法查找Key对象在Key数组中的下标来定位Value,SparseArray相比ArrayMap进一步优化空间提高性能。
SparseArray的目的是专门针对基本类型做优化,Key只能是可排序的基本类型,比如int型key的SparseArray,long型key的LongSparseArray,对于Value,除了泛型Value,对每种基本类型都有单独的实现,比如SparseBooleanArray,SparseLongArray等等。
- 无需包装
直接使用基本类型值,不需要包装成对象。 - 无需hash,无需比对Key对象
直接使用基本类型值排序索引和判断相等,无碰撞,无需调用hashCode方法,无需equals比较。 - 更小的内部数组
相比于ArrayMap,无需单独的hash排序数组,内部只需等长的两个数组分别存放Key和Value - 延迟删除
对于移除操作,SparseArray并不是在每次remove操作直接移动数组元素,而是用一个删除标记将对应key的value标记为已删除,并标记需要回收,等待下次添加、扩容等需要移动数组元素的地方统一操作,进一步提升性能。 - 有序
所有键值对均是按照基本类型key的自然排序,支持下标访问(keyAt方法和valueAt方法),迭代遍历和数组相同
总结
1. 空间
HashMap的内部数组长度必须是2n,需要大一些降低碰撞概率(可以通过负载因子调节),数组元素是跳跃的,需要为键值对创建Node对象在碰撞时拉链。
ArrayMap则是通过牺牲性能换取空间,没有2n限制,数组长度无需太长,size范围内没有闲置位置,无需为键值对创建Node对象。
2. 查找
HashMap在元素非常多时性能要高于ArrayMap。
HashMap直接通过hash值位运算计算出下标,ArrayMap需要通过二分法查找;hash碰撞时HashMap只需遍历链表,ArrayMap需要分别向后向前遍历数组。
3. 增删
这个几乎就是LinkedList和ArrayList的区别了
4. 扩容
这个是ArrayMap优于HashMap的地方。
HashMap的下标位置是和数组容量相关的,带来一个问题,每次数组容量改变都需要重新计算所有键值对的下标,也就是rehash。而ArrayMap则没有这个问题,只需要创建一个更大的数组,用System.arrayCopy把元素复制过去。
5. 遍历
HashMap需要遍历数组和数组中的每一个单向链表,并且数组元素是跳跃的;ArrayMap则只用遍历一个连续的mArray数组即可
6.选择
可以看出ArrayMap适合数量不多、对内存敏感、频繁扩容的地方,而在元素比较多时HashMap更优
一些闲的蛋疼的想法
- 可不可以让HashMap有序?
所有hashCode方法都返回0就成了一个单向链表了 - 可不可以让ArrayMap有序?
控制hashCode方法的返回值为想要的顺序就有序了