网易前端微专业课程讨论区问答精选
Javascript程序设计部分
注:以下内容大部分来自网易云课堂《前端微专业》课程讨论区,下问内容较多,可打开标题下方的[目录]索引,便于定位查看。
arguments.callee()方法?
[严老师]功能:arguments.callee是当前被调用函数自身引用,主要用于匿名函数调用时访问函数本身,比如用匿名函数计算某个整数阶乘这样的功能。
产生原因及现状:早期的js版本不允许命名函数表达式,因此不能构造一个递归的函数表达式,为此引入了arguments.callee这样一个属性,但实际上这是一个糟糕解决方案,ES3通过命名函数表达式方式解决了函数递归的问题。callee在ES5严格模式中是被禁用的。
[daniel补充]“命名函数表达式”参考链接
instanceof 中提到的“不能判别原始类型” 这个“原始类型”是指 前面的6个“标准类型”吗?
当前ECMAScript 中数据类型有6种:String, Number, Boolean, Null, Undefined, Object. Object是引用类型,前5种统称为原始(primitive)类型。JavaScript data types and data structures
instanceof总结:
1. 判别内置对象类型
2. 不能判别原始类型
3. 判别自定义对象类型 
[陈同学归纳] 
类型判断方法问题
function type(obj){
return Object.prototype.toString.call(obj).slice(8, -1).toLowerCase();
}[严老师]
1. call是Function的原型对象方法(类似方法还有apply),用于指定Function实例对象(即函数)的调用者和参数并实现函数调用。apply和call会在“内置对象-Function”课程中为同学详细讲解,请关注。
2. slice和toLowerCase都是String的原型对象方法,即所有String类型对象(或字符串字面量)都能直接调用到的方法。具体功能参见ls同学回答。当然String的原型对象方法远不止这两个,同学可以去W3C或MDN网站了解各个原型方法功能和语法。
[daniel补充]MDN对arguments.callee的描述
单个JS文件如何调试
[严老师]有两种方式,一种是把js写在html文件内,然后用浏览器调试该文件,在相应的语句处设置断点,当断点被断住时,就能查看到当前运行环境各种变量值。
另一种方法是直接在chrome console中执行,用”debugger”执行调试,同样也能在“Scope Variables”查看到当前运行环境各种变量值;也方便观测方式是可以在“Watch Expressions”中添加需观测变量。如下图
函数值传递问题
以下代码执行后,president.name=?
function setName(obj){
obj.name = "obama";
obj = {name:"clinton"};
}
var president = {name:"bush"};
setName(president);[daniel]输出obama
进入setname后,obj 和 president指向堆内存中同一对象,对obj的修改会反应到president上,而第二行执行后,obj指向一个新的对象clinton,此时president依然指向obama
[严老师]js中=实现就是值类型复制,当对方是引用类型时复制的就是该引用类型的地址值。你例子中,当setname方法被调用时,参数obj接收到的值是对象{name:”soul”}的地址,当然你可以更改该对象内的name属性。但是当执行obj={name:”new name”}时,obj被修改为{name:”new name”}地址值,显然这两个地址实际指向不同对象,因此外面nameobj不会受到影响。不知这样解释是否明白了
[yinchenhao0]函数调用策略的补充
从语言的层面上说, 这种函数调用策略叫call by sharing
与之相对的叫 call by value 和 call by reference
proto 与 prototype 的区别 ?老师参与
function Point(){}
var p = new Point();
// 能解释一下:
Point.__proto__ // Function Empty()
Point.prototype // Point {}
p.__proto__ // Point {}
p.prototype // undefined[严老师]prototype是构造器对象属性,构造器实例化对象时,prototype会被实例对象的proto所引用。比如
var s = new String("abc");
s.__proto__ === String.prototype; // true[yinchenhao0] 
注:
这节论坛回复中,严老师贴了很多站内链接,现在全部失效了。。。
关于prototype和constructor的疑问
- 什么样的对象具有prototype属性?是否所有对象都有这个属性(包括对象直接量)?
- 什么样的对象具有constructor属性?是否只有用new加构造器构造出来的对象有?
- prototype和constructor有什么样的联系呢?还是独立的概念没有联系
[严老师]
1. 构造器对象有prototype(即原型对象)属性,普通对象没有。(普通对象只有引用了prototype的proto隐藏属性)
2. prototype(即原型对象)有constructor属性。普通对象可以隐式的通过原型链(proto)访问到constructor。
3. constructor是prototype的一个属性。
栈内存,堆内存指什么?
[严老师]
因为js中开发则不能直接操作内存,因此js栈内存可以简单的理解为原始类型值和引用类型地址存储区域(如果是临时变量,用完后会被回收),堆内存表示引用类型值存储区域。
在数据结构知识体系里,栈表示先进后出(First-In/Last-Out)的一种数据结构,堆表示队列优先级的一种数据结构。
1、在C/C++内存存储知识体系里:栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
console调试器如何使用?
[不要叫我同学]
很有用,推荐看下。链接
请问在内置对象->Function中, 把参数赋值为null是为了释放内存么
var define = function(name, deps, callback){
var node, context;
if(typeof(name) !== "string"){
// foo code
// 下面这三行没太看懂, 是为了释放内存么?
callback = deps;
deps = name;
name = null;
}
};[严老师]
define是require.js中定义模块的函数。define函数允许调用者传1个参数,2个参数和3个参数的情况
传1个参数时,默认这个参数须是callback函数
传2个参数时,默认一个是deps数组,另一个是callback函数
传3个参数时,分别对应name名称,deps数组和callback函数
比如我下面这样调用时
define([],function{});刚进入函数执行时,name=[],deps=function(){},callback=undefined,此时如果不做更改,函数后面的逻辑就会出错。
if(typeof(name) !== "string"){
callback = deps;
deps = name;
name = null;
}上面的代码就是通过对参数类型识别将实参的值赋值给正确的得形参,以保证函数后面逻辑正确的执行。其实就是基于参数个数和类别的函数功能重载。
另外name是define函数定义的临时变量,显式将它置为null,通常可能有两个原因:
1. 后面处理name时,便于判断,而不需要再次通过类型识别去判别。
2. 有可能name会在后面代码中会被其他全局变量引用到,这样的话确实可能会影响到浏览器内存回收。
建议lz去require.js中读下这个代码,可能比我直接讲理解更深入,还能了解下require.js啊。
闭包的概念及用法
[严老师]
闭包的作用是对对象私有属性或方法进行封装(参考C++和JAVA中的公有、私有属性区别和目的),有些只跟对象自身相关的属性或方法不希望让对象使用者直接访问到时我们就需要使用闭包。
比如有台空调,它有个内部状态属性(两个值:0表示不运行,1表示运行中),但是使用者不能直接更改这个属性,因为0(不运行)-〉1(运行中)状态切换时,可能还有很多其他工作要做(比如要读取上次空调的设置(制冷还是制热)等一系列动作),直接更改状态位很可能导致空调内部状态混乱甚至运行错误。因此使用者只能调用空调对象开放出来的开关方法switchOn()、switchOff()来进行空调的开关控制(这些方法往往代表一个完整的控制逻辑)。
这个例子中,空调的状态位就应该用闭包将其封装为私有属性。如果你设计开发的对象、库、框架设计会被其他人使用,就很有必要对此进行合理的封装。
上面提到的是闭包的通常使用场景。闭包准确的定义是函数执行作用域上的一个扩展作用域,
function func(){
var count = 0;
function innerFunc(){
count++; // 代码执行到这里时,innerFunc的作用域链上除了Local,Gobal之外还会出现一个Closure作用域,就是我们所说的闭包。
console.log(count);
//debugger; // 调试查看Scope,试一试。
}
innerFunc();
}
func();不过这种闭包的定义,其实是把我们常规的关于变量作用域的理解复杂化了,换句话就是说这种状态下不用闭包的概念我们其实完全能理解。但是下面这种情况:
function func(){
var count = 0;
return function(){
count++; // 代码执行到这里时,innerFunc的作用域链上除了Local,Gobal之外还会出现一个Closure作用域(里面只有一个count变量),就是我们所说的闭包。
console.log(count);
//debugger; // 调试查看Scope,试一试。
}
}
var innerFunc = func();
innerFunc();
innerFunc();replace函数的一些高级用法
[严老师]replace的功能很强大,第一个参数可以使用正则表达式匹配字符串,第二个参数可以是待替换的字符串,比如
"2a3b4c5d".replace(/\d/g, "X"); // "XaXbXcXd"
"2a3b4c5d".replace(/\d/g, "$&x"); // 用$&表示匹配到的字符串,返回"2Xa3Xb4Xc5Xd"当然replace第二个参数可以是返回字符串的函数,这个功能就非常强大了
"2a3b4c5d".replace(/\d/g, function(a){
switch(a) {
case '2':
return "X";
break;
case '3':
return "Y";
break;
case '4':
return "Z";
break;
case '5':
return "5";
break;
}
}); // 返回 "XaYbZc5d"函数可以有三个参数,分别表示如下含义:
"2a3b4c5d".replace(/\d/g, function(a,b,c){
console.log(a); // a表示匹配到的字符串
console.log(b); // b表示匹配到的字符串起始位置
console.log(c); // c表示整个字符串
})此时发现没有参数表示匹配索引,但是这是经常要用到的功能,我们如何解决呢,答案是闭包,如下
var arr = ['O','P','Q','R']; // 需要将匹配的字符串替换成数组内的字符串
"2a3b4c5d".replace(/\d/g, (function(){
var index = 0; // 通过index这个闭包变量来记录匹配到次数
return function(){
return arr[index++];
}
})()); // 返回"OaPbQcRd"几乎所有字符串替换需求都可以通过上面几种方法实现。
只要innerFunc不被删除,innerFunc作用域链上的Closuer作用域(里面只有一个count变量)会一直存在,就像一个全局(或静态)变量一样(区别是count不能被外部调用者访问到),就必须用闭包的概念去理解了。
DOM编程艺术部分
注:笔记内容大部分来自网易云课堂《前端微专业》课程讨论区
请问关于apply的原理
circle调用了point.move方法,却改变了circle自身的相同属性名的属性值,为什么?
[魏老师]apply可以认为是借用,我先做一个比喻,然后在针对性的讲这段代码。
比如我有个豆浆机可以打豆浆,你现在要开party要借我的豆浆机打豆浆,当然你必须要有黄豆。
point.move.apply(circle, [2,1])对照这个比喻可以等价于”我.用我的豆浆机打豆浆功能.借给(你,你的黄豆)”
调用的结果就是做出了你的豆浆,party女王就喝到了你的豆浆。
function.prototype.apply/bind 在实际开发中的用处
在Function这一节的视频当中,您用在坐标里移动点这个例子作apply & bind 的讲解。我想问的是:这样子做有什么好的地方?
circle其实可以理解一个对象,一个圆去用一个点的方法,我自己很难接受的……感觉很奇怪。。。。会不会出Bug,这个方法能不能正确的操作circle(假如例子更加复杂的话)。
如果是我的话,我会造一个geometry这样一个对象, 就像您之后提到的子类构造器那样(但我想造一个父类…..)。这个对象是point和circle的父对象,将move方法写在它之下,这样point和circle都能继承,而且也更好理解。所以总结下来apply在视频当中用到了:一个对象调用另一个对象的方法 & 普通函数的指定对象调用。
那重新回到问题,apply或者bind这样一种让一个对象调用另一个对象(跨作用域)的方法,在开发中是怎么用的呢?或者说用了能够优化哪些地方呢?
[严老师]js对象会有很多通用属性,但是并没有为他们提供基于场景方法(因为不清楚使用场景或者开发者习惯),比如开发者想用一组属性以特定逻辑组织起来实现一个特定功能,理想的状况是为每个对象添加方法来实现。但是很多时候并不合适,比如下面例子:
function changeStyle(attr, value){
this.style[attr] = value;
}
var box = document.getElementById('box');
window.changeStyle.call(box, "height", "200px");另外有些父类方法在继承时已经被子类的方法覆盖了,但是某些场景下子类对象又想调用父类的方法,这时就只能用apply或call来调用,比如Object.prototype.toString方法;
this关键字有哪些使用方式,不知道在什么情况下使用
[魏老师]this比较难以理解是因为在js中this不同的情况下有不同的值,下面我们逐一说明:
1. 全局上的this就是window对象,例如
alert(this===window); // true2.函数中的this
2.1 如果函数不当做构造函数使用,this指调用它的对象。如果没有调用对象,this指window,例如有对象jerry定义如下:
var jerry = {
name: "jerry",
age: 12,
introduce: function(){
return "My name is " + this.name + '. My age is ' + this.age + '.';
}
}2.1.1 调用 jerry.introduce(); 时,this为 jerry, 返回值就为 ’ “My name is jerry. My age is 12.’。
2.1.2 如果我们这样调用:
var fn = jerry.introduce;
fn(); 这里的fn没有调用对象,那么this指向window。
2.1.3 当然我们还可以通过apply,call指定调用对象,来修改this
2.2 如果函数当做构造函数使用,那么this指向当前创建的对象,例如:
function Person(name, age){
this.name = name;
this.age = age;
}
var jerry = new Person('jerry', 1);在执行Person构造函数时,this指向新创建的对象,也就是后来返回的jerry对象。
3. 事件响应函数中的this,指向当前触发时间的元素,例如:
<div id="nav" onclick="alert(this.id)">点我div>点击是会打印 nav
以下元素的element.children.length为啥是1?
<div>欢迎<a href="/profile">Jerrya>同学!div>上述DOM节点是element,那么element.children.length的值为何是1,可浏览器缺是childNodes: NodeList[3]
[魏老师]是因为childNodes和children是两个属性,childNodes表示子节点,children表示子元素可以在调试工具里面看下,如下图 
[厨师老王]节点和元素的概念不一样吧,节点包含元素,节点有元素节点、文本节点等
[不会结束]
<div id="parent">
"">
<div class="chi">div>
div>
console.log("parent的children.length: " + parent.children.length);
console.log("parent的childNode.length: " + parent.childNodes.length);的确元素的children指的是元素节点,然后childrenNode还包括了其他节点,包括文本节点,注释节点等等。
上面的代码中,第一行js输出的结果为2,第二行为5,这是一般的现代浏览器中的结果。因为除了a和div以外,还有三个文本节点,这是因为换行符的问题,就如inline-block环境下换行符也会被当做一个字符显示在浏览器中。
然后将上面html代码缩写成一下代码,就会发现第二行js输出也为2。
但是在IE6-7下,childNodes会忽略空白的文本节点,同时children会将注释节点识别为元素节点,到了8以上就不会这样了。IE真是万年坑。
关于事件类型和事件对象还有事件名称
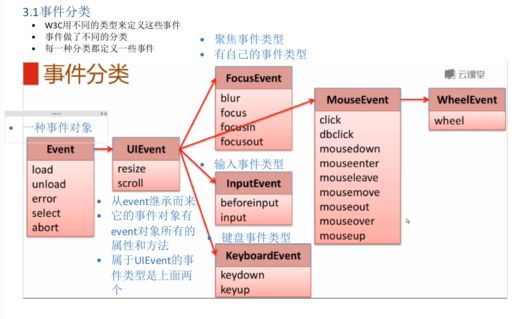
1. 粗体的是事件类型吧,那么Event是不是也是事件对象?
2. 如果是,它们的区别是什么,为什么老师首先说它是事件对象,不说它是事件类型?
3. 粗体下面的是事件名称还是事件对象还是事件类型(看第四问)?
4. 聚焦事件类型有自己的事件类型是指下面的那4个吗?
[魏老师]
我们来看一个例子就清楚了,代码如下
document.onclick = function(event){
debugger;
};打开页面,大概调试工具,点击页面,会发现页面停在debugger处,这时在调试工具右侧的局部变量里展开event,看到如下图(部分属性我略去了): 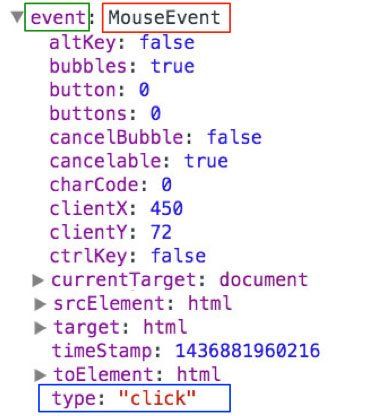
图中绿线框出的就是代码中的event,它是一个事件对象,是类MouseEvent(图中红线框出)的一个对象,这个事件对象的类型是”click”(图中蓝线框出)。因为类(class), 类型(type) 中文比较类似,所以容易混淆。
浏览器容错性
<div id="myDiv"data-id = "12345" data-name = "jhon">div>在解释器解释的时候是不是将格式标准化成
<div id="myDiv" data-id="12345" data-name="jhon">div>这样了[魏老师]浏览器具有很强的容错性,但是不要依赖浏览器的容错能力。最好是源码里面就写成标准格式
为什么浏览器的兼容性那么重要
老师: 为什么兼容问题那么重要,不管课堂讨论,作业和考试都在做兼容问题?
一般情况下,打开电脑都会提示使用者获取高版本的浏览器,并且更新到最新的版本是很容易的事情,难道现在还有谁在固执地用低版本的浏览器吗?
还是有什么其他的原因?
[蔡老师]主要因为你是你是追求新事物的人
不升级的原因很多,为什么微软都声明了不再维护xp了,但是还是有人要出钱继续支持xp呢? 所以我们没法保证所有的人用的浏览器都是最新的,而产品要支持到什么样的浏览器也取决于面对的用户群是什么,这个是百度统计的数据 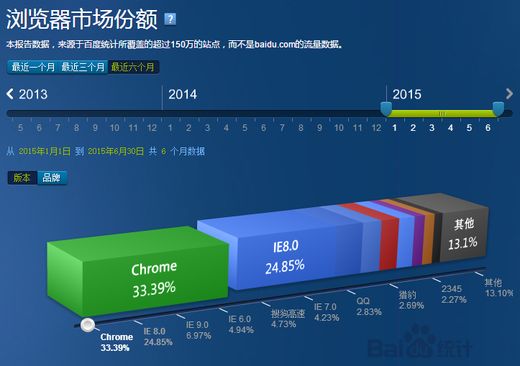
近几年前端技术的环境已经有了很大的改善,很多产品都已经不再要求兼容到ie6-了,甚至ie8-, 所以我们课程中其实已经弱化兼容性的内容,只是在课程里提一下,或者讨论区里讨论一下,但是对于技术而言了解其他平台的实现情况也是扩展一下自己就的知识面,说不定哪天你的工作环境就需要你去针对这些平台做开发
getElementsByClassname一个疑问
在节点操作单元作业中,按照老师的方法 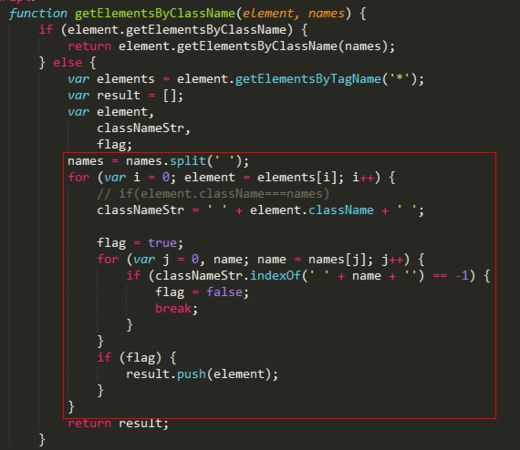
但是这种方式似乎也行(至少我测试的几个是可以的),就不知道这种方式是不是有哪些地方欠考虑,还请各位帮忙 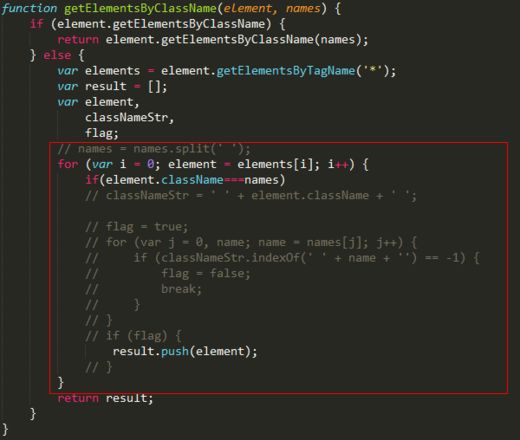
[蔡老师]首先我们先说明一下 getElementsByClassname 这个接口(else部分)需要实现的功能是什么
根据输入的样式名称names,找到element下所有同时包含names中样式的节点
多个样式用空格分隔,与样式先后顺序无关
还是上面的例子,比如我们输入的 names 是 “u-btn-1 u-btn-0”,这表示我们需要找出element下所有同时包含u-btn-1和u-btn-0两个样式的节点,这里注意两个点:同时、包含
同时:比如有个节点 node.className 是 “u-btn-0 u-btn”,是不是符合同时的条件呢?我们说显然不符合,因为他只有u-btn-0而没有u-btn-1
包含:比如有个节点 node.className 是 “u-btn-0 u-btn-1 u-btn”,是不是符合包含的条件呢?很明显他是符合的,因为他的三个样式u-btn-0、u-btn-1、u-btn中有u-btn-0、u-btn-1两个样式
再来看一下如果直接用node.className===names这种方式去检查节点是否符合条件的话那“u-btn-0 u-btn-1”和“u-btn-1 u-btn-0”能匹配么?显然,他们是不匹配的,但是这个节点却是符合我们的条件的
那么案例代码中是怎么来检查节点的呢?主要是以下几个步骤
先把names按照空格拆分,比如这里的“u-btn-1 u-btn-0”会被拆分成单个样式的数组 [“u-btn-1”,“u-btn-0”]
给node.className前后加两空格,为的是后续匹配的时候可以匹配到起始和结果的样式
拿[“u-btn-1”,“u-btn-0”]这个列表中的每一个样式,比如“u-btn-1”,先前后加空格,然后再在className中搜索是否包含这个样式
如果出现某个样式没有被包含则退出匹配过程并忽略这个节点
如果匹配结束所有的样式都在className中找到了,那么这个节点就是我们要找的节点
最后返回这些找到的节点列表
最后建议在学习过程中把这些代码手动写一遍,然后根据前面学习的调试工具课程的知识在浏览器的开发工具里做一下调试,单步跟进一下,看看各个变量的值的变化,可以加深你的理解和掌握
除了DOM编程艺术,还有什么书推荐吗?
[蔡老师]我在网盘里共享了一些中英文的电子书,没有基础的可以看看head first系列,有基础的可以看看pro系列,进一步想了解一些设计相关的可以看看 模式相关的。链接
捕获过程与何时使用捕获行为?
在给元素添加事件时可以选择是否为捕获过程,但是捕获过程究竟是什么?合适需要将捕获过程设为 true 呢?
[蔡老师]首先我们再回顾一下事件的三个过程: 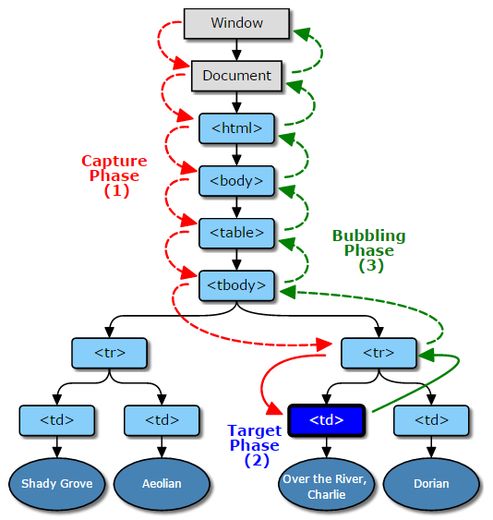
也就是说在支持三个阶段的事件触发时肯定会遵循 Capture -> Target -> Bubbling 的顺序
举个例子:比如我们现在在这些节点上添加事件
// 添加Capture阶段事件
document.addEventListener('click',function(){
alert('capture:'+1);
},true); // 第三个参数表示在捕获阶段执行
tableNode.addEventListener('click',function(){
alert('capture:'+2);
},true);
tdNode.addEventListener('click',function(){
alert('capture:'+3);
},true);
// 添加Bubbling阶段事件
docuemnt.addEventListener('click',function(){
alert('bubble:'+1);
});
tableNode.addEventListener('click',function(){
alert('bubble:'+2);
});
tdNode.addEventListener('click',function(){
alert('bubble:'+3);
});那么我们用图来表示一下添加完事件之后的情形 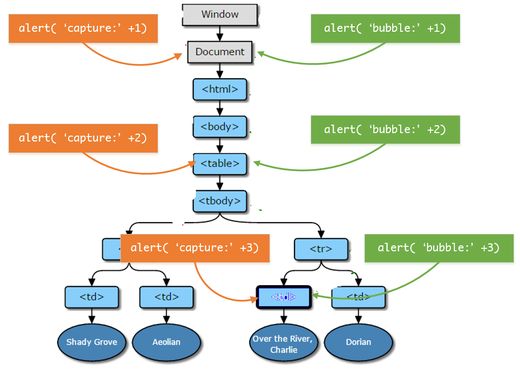
这个时候当用户点击了3的那个td节点我们结合上面说的三个阶段的顺序,那么输出的结果应该是
capture:1
capture:2
capture:3
bubble:3
bubble:2
bubble:1这个结果没有任何异议,前面说到执行顺序,那么问题来了 如果对同一个节点添加同一阶段的多个事件他的执行顺序是怎么样的呢? 比如
// 对document添加了三个bubbling阶段的事件
document.addEventListener('click',function(){
alert(1);
});
document.addEventListener('click',function(){
alert(2);
});
document.addEventListener('click',function(){
alert(3);
});那当我点击document的时候1,2,3是按照一个什么顺序打印出来的呢?
由于早期并没有规范定义说必须要用什么顺序打印,因此各浏览器实现也是五花八门,有1,2,3的,也有3,2,1的,到了DOM3的规范中已经有明确的规定同一节点同一阶段事件按照执行函数注册顺序执行,所以目前高级浏览器都采用1,2,3的顺序输出
在实际项目过程中,某些情况下比如若干的组件或者模块都需要监听某个节点的某个事件,但是组件或者模块的生成(即添加事件的时机)是不一定保证顺序的,所以这个情况下如果某个组件对这个节点的这个事件的优先级特别高(需要保证必须先触发这个组件里的这个事件),而这个平台又支持这个阶段事件的话,可以添加capture阶段事件,用三阶段的顺序来保证,比如移动平台模拟手势的实现会添加document上touchXXX的capture阶段事件,以优先识别手势操作
当然,实践过程中考虑到不同浏览器对三阶段支持的情况的差异,大部分情况下都采用的是bubbling阶段的事件
单页式网页应用的实现原理?
[蔡老师]在说明单页应用之前我们先简单了解一下普通的刷新页面的应用的一个简单流程,以下图为例
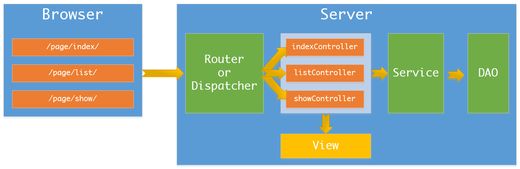
刷新页面的应用要显示出一个页面经过的流程大致包括:
- 刷新页面应用的每个页面都有一个地址(URL)与其对应
- 当用户在浏览器输入某个页面的地址时,浏览器发请求到我们的服务器上
- 服务器通过路由器或者调度器(Router/Dispatcher)将对应的地址(URL)映射到指定的控制层实现逻辑中
- 控制层使用服务层(Service)获取页面需要的数据模型(通常会借助数据层相关操作)
- 控制层还需要使用视图层(View)将数据整合到页面中生成一个完整的页面,然后返回给浏览器
- 最后通过浏览器来绘制整个页面并与用户进行交互
要显示出这么一个页面不管是刷新页面还是单页面这些过程都是不能省的,那单页面应用怎么组合这些过程呢?我们说上面的这个过程服务器端介入的时机在我们切换地址的时候,那如果我们让服务器端介入时间往后推是不是就可以实现单页应用了呢? 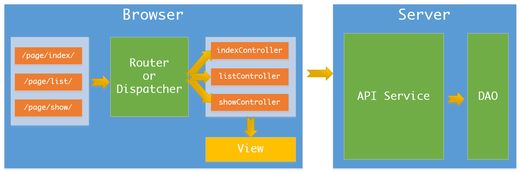
所以一个常见的单页应用主要会包含以下及部分内容 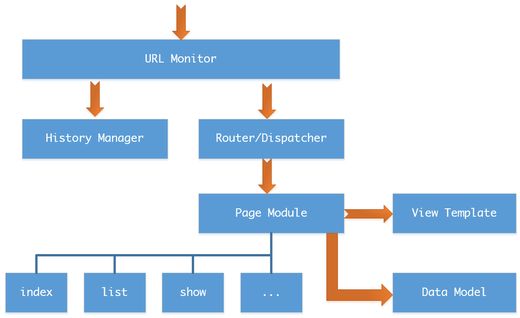
- URL Monitor:检测URL地址的变化
- History Manager:管理单页访问历史
- Router/Dispatcher:根据URL地址决定调度显示哪个页面
- Page Module:每个页面的实现逻辑,会使用到Data Model和View Template来完成页面组装
- Data Model:数据管理层,负责内存数据维护、跟服务器的API Service通信交换数据等
- View Template:页面视图模板,无数据,最终可以与不同的数据整合生成页面
当然单页面应用涉及很多其他相关内容,单纯的几段文字也没法详尽的描述清楚,最简单的代码实现示例
页面结构
<div>
<a href="#1">模块1a>
<a href="#2">模块2a>
div>
<div>
<div id="module-1" style="display:none;">
module 1 content here
div>
<div id="module-2" style="display:none;">
module 1 content here
div>
div>代码示例
var last;
// URL Monitor
window.addEventListener('hashchange',function(){
// Router
var id = location.hash.substr(1);
var mNode = document.getElementById('module-'+id);
// hide last module
if (!!last){
last.style.display = 'none';
last = null;
}
// show current module
if (!!mNode){
last = mNode;
mNode.style.display = '';
// TODO page module implementation
}
});getElementChildren的一个实现
MDN里面是这样说的: Internet Explorer 6 - 8 支持该属性,但是可能会错误地包含注释 Comment 节点。
https://developer.mozilla.org/zh-CN/docs/Web/API/ParentNode/children
[蔡老师]
这个方法做兼容要考虑几点:
- 返回的结果类型一致
- 返回的结果内容一致
在实现过程中如果出现这种代码的,肯定不符合第一个条件
if (element.children){
return element.children;
}这里 element.children 是个节点集合,而你自己实现的方法中返回的是个数组,这两个不是同一个类型,虽然 element.children 也有length,可以用索引取元素等等这些类似数组的特性,但是他没有数组原型链上的方法,因此如果你拿这个结果后续当数组用,比如调用一些数组方法 ret.splice 等等时在不同平台下就会出现异常
一个参考的实现方式可以这样
function getElementChildren(element){
var ret;
// 先拿出所有的子节点
if (element.children){
ret = element.children;
}else{
ret = element.childNodes;
}
// 转换类型,把集合转成数组
ret = [].slice.call(ret,0); //此处有同学反映有兼容问题,后来建议改成push实现
// 检查子节点的类型
for(var i=ret.length-1;i>=0;i--){
// 过滤掉非Element元素
if (ret[i].nodeType!==1){
ret.splice(i,1);
}
}
return ret;
}slice兼容问题
一般在localstorage里存储什么样的数据呢?如何判断,一个数据应该是存到cookie中还是存到localstorage里?
[蔡老师]我们说在访问一个网页时某些状态信息不会被记录(比如我们看网页时滚动条的位置),也就是说当我们关闭页面下次重新进入的时候滚动条位置始终从起始位置开始,那么像此类用户浏览网页的状态信息如果我们的产品需要都必须记录的话(比如每次打开网页从上一次离开的滚动位置开始),那么我们就需要有一种存储机制可以用来保存这些信息,而这些信息不会因为关闭浏览器而消失,浏览器中这些存储机制就包括 cookie、storage 等,那么cookie与storage的主要区别是什么?
- 存储容量:cookie的存储信息容量要远小于storage,cookie只能存几百K信息,而storage可以存几M的信息(具体数据因浏览器的实现差异而不同)
- 对请求影响:当页面发起请求时当前域及其父域的cookie信息会被写入Header发送到服务器,而storage里的信息不会影响页面请求,那么这样的cookie机制会导致什么问题呢? 一般cookie里写入的是一些个人隐私相关的信息,如登录验证信息等等,而此类信息大部分情况下只有在需要验证的那些请求才会用到,而比如像我们的css、js、image等等这些静态资源很多时候都是不需要的,那么如果在cookie里写入太多信息的话也意味我们的这些请求都必须额外携带这么多多余的信息,进而增加请求的上行流量,这对于用户量大的产品这也是一笔不少的成本开销,所以实际环境下会用很多方式来优化这部分内容
浏览器提供的sotrage机制又分为两种,一种是会话期间的sessionStorage(只要浏览器不关闭,无论你怎么切换页面,始终可以取到这里存的信息),一种是持久的localStorage(浏览器关闭后再打开仍旧可以继续拿到这里存储的信息),具体你要选择使用哪种存储机制根据项目实际情况来选择就可以了
页面架构部分
产品前端架构部分
有哪些比较优秀的前端社区?
[郑老师]随便列几个吧。
国内: http://div.io . http://segmentfault.com/ . http://www.w3cplus.com/ http://www.html-js.com/(现在入门的为主)
国外: http://stackoverflow.com/ (学会自己查找问题)
模块化是什么
[郑老师]Commonjs module, es6 module , AMD 三个规范 是目前最常用的模块规范。 因为当前版本的JS并没有天然的模块支持, 所以了解这些模块化解决方案对你今后的前端学习是非常有帮助的。 课程由于时间原因,不可能将提到的四种方案都 事无巨细的介绍清楚。 同学如果有疑虑, 可以把这个repo下的DEMO fork下来。 再有问题 可以在这个帖子下 回复 你有哪些具体的不明白之处。https://github.com/leeluolee/frontend-modular
大量微型项目没有必要利用模块化呢?
[郑老师]即使小项目比如直邮页、活动页, 至少也应该使用IIFE 来创建一个局部作用域, 对于不清楚是否会被复用的模块, 我建议是都需要进行模块化的
本地代理 配置 老师你使用的什么工具
[郑老师]老师自己用的puer. 下个版本会加强代理的规则支持(未发布), 现在只能全局代理, 但是由于代理级别比本地mock的低,你仍然可以复写一些接口来调试已有的项目。
具体可以看 http://leeluolee.github.io/2014/10/24/use-puer-helpus-developer-frontend/
除此之外, 仍有其它更普遍的工具, 比如fiddler,参考阿里这篇 使用Fiddler提高前端工作效率 (实例篇)
阿里的这篇文章写的是js文件的代理, 对于json响应也是一样, 你将 /api/blogs/10的请求 定位到一个本地json文件即可
还有一个和fiddler类似的nodejs工具, 腾讯开发的, https://github.com/rehorn/livepool 不过由于fiddler的代理侵入性更强, 而live-poll需要建立一个代理服务器。
课程中提到服务端模版freemark
相对于服务端模版freemark, 目前也有其他客户端模版。
1)服务端模版和客户端模版 在目前大公司的使用情况(网易内部的使用情况如何,服务端模版和客户端模版在网易项目中使用比例怎样)?
2)作为开发者,一个项目选择 服务端模版还是客户端模版 有什么准则作为依据?
[郑老师]
服务端模板 和 客户端模板 占比 是根据产品本身形态的不同。
- 比如云音乐客户端这种app, 没有页面刷新, 显然几乎100% 都是客户端模板
- 而一些内容型页面, 比如网易的网站部,它们对SEO的要求非常高,一般都是使用服务端模板, 甚至它们会对很多页面做直接的静态化来提高加速速度和SEO.
即例如单页系统这种富逻辑的前端产品肯定是客户端模板为主, 否则是后端模板为主。
准则:
根据经验吧, 如果产品形态对交互要求不高, 我们部门的开发者目前普遍偏向于使用客户端模板构建单页应用, 因为这样可以方便我们进行分离开发。与后台的沟通也仅限于业务数据的交流,大大减低沟通成本。 但是这样对前端人员的技术要求就较高,要靠框架和规范来约定。单页系统会有大量的临时状态需要我们处理或清理, 这些在非单页系统中是无需关心的。
本地开发几个问题
- 对本地服务器有一点了解,海波老师开发了一个puer的静态服务器。但不是很了解本地代理,为什么需要本地代理呢?
- 同步请求被本地服务器拦截,为什么异步请求的时候是被本地代理拦截的?
- 想动手实际操作一下用本地服务器模拟数据,看完还不是很明白是怎样搭建出一个这样的环境的?
[郑老师]
1. 本地代理服务器由于是一个独立功能的server,可以方便你加入功能, 比如脚本注入、远程调试、代理、本地mock等等。
2. 都是本地服务器拦截的,puer会获得所有请求,然后根据配置决定是直接返回mock数据,还是代理到其它服务器。其实没有同步、异步的说法, 改为针对页面和数据的请求 可能更加合适一些, 在请求上这两者极为不同,因为对页面的请求通常会经过模板层(发生在后端,这个很难mock),所以一般是直接代理到后端服务器。 但是异步请求就方便多了, 因为一般来讲前端只关心返回的是json对象即可, 所以可以很方便的通过静态服务器代理。
3. 看下puer目前这个简单版本的文档说明,就可以搭建出简单的分离开发的版本。下个版本未发布。会更加一致些,都会抽取到rewrite特性里
git命令行跟git客户端能做的事有区别吗?
老师我想了解一下,github有个客户端,他跟git命令行有什么异同呢,有没有什么事情是git命令行能做的,但是客户端做不到的。或者说,git命令行相对于github客户端的优势有哪些。
[郑老师]
首先声明的是, 讲师本人(我)并没有使用过github客户端, 但是今天我看到此问题大概使用了30分钟, 我简单谈下看法。
首先github是基于git创建的代码托管工具 和社区, 也就是现在最热门的同性交友网站。作为服务端而言,你可以将github看成是富功能的远程git 仓库, 比如,它的server端封装了一个独特的fork特性 (并不是原git 直接提供的功能), 即在你的.git 目录下是没有这个信息的, 这个独有的信息记录在github服务器中,并且只能应用于github上的远程仓库之间
这个客户端非常优秀, 可以极大的改善你操作github的使用体验,特别是在你项目比较多的情况下。弹指一挥间可以帮你进行同步以及信息查看。
- 所有的git客户端必然是依赖于(封装自)底层的git command. 它提供了一些便利的操作,并提供了友好的界面显示。github客户端同样如此
- git命令提供能力更加全面,而客户端由于是基于这些命令的封装, 功能性有余而灵活度不足
- 无论你最终是否决定使用git客户端, 首先理解所有的git命令是首要前提,否则你真正遇到问题时会一头雾水。如果你想解答未来实习生妹子的关于git的问题, 好好学好原生的git吧, 就和我们推荐你先学好javascript + dom, 而不是沉溺于jQuery给你带来的便利
前端开发相关工具有哪些?
[蔡老师]我们按照开发各流程涉及的工具简单看一下有哪些可以选择 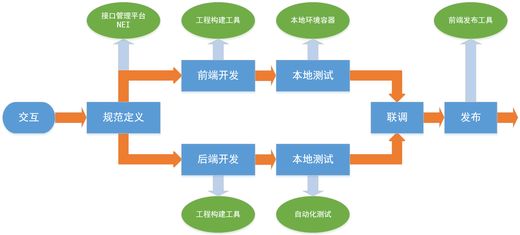
接口管理平台:这个目前ms没看到有什么开源系统可以直接拿来用
工程构建工具:这个会依赖接口管理平台的数据做自动化构建,如果没有接口管理平台简单点团队可以自己写个工具把一些规范代码做成模板自动化生成一下,模拟数据估计还得每个人自己写
本地环境容器:这个可以分成两部分:服务器、代理,同时支持这两部分的如puer(https://github.com/leeluolee/puer),如果已经有服务器(后端已提供运行环境),可以选择具有请求自动响应功能的代理工具如fiddler(http://www.telerik.com/fiddler)
前端发布工具:比较简单的如toolkit(https://github.com/genify/toolkit2),只需要配置一下项目的输入输出即可帮你进行发布,如果项目比较特殊可以自己写个工具,主要做的事情无非就是样式、脚本的合并压缩、版本处理、图片处理、域名配置等等
当然如果想要一整套的规范及工具的可以参考了解下百度的F.I.S(http://fis.baidu.com/),不过最终的解决方案估计还得根据公司实际情况来定制
什么是同步请求和异步请求?
[蔡老师]同步:假设两件事情A和B,A事情做的时候应用禁用了所有对其他事情的响应,只响应A事情,B事情只能等A做完之后才能开始做,比较常见的情形如
alert('111111');
console.log('111111')这里我们说alert和log就是两个同步的事情,当浏览器弹出alert框时你唯一能做的是响应alert的事情(比如 看一下alert的内容,点击确定关闭alert等),只有当你关闭alert后浏览器才能继续去做log的事情
异步: 有了同步的概念后,异步就比较简单了,无非就是A事情在做的时候,没有结束之前,B事情也可以开始做了,两个事情是同时进行的,而至于谁先做完无法确定,通常这种情况下需要有个回调来通知各事情结束的状态
对于请求也一样,同步请求就是浏览器在发送请求、接收数据过程中不会响应用户的任何行为,只有等请求结束后才能继续后续的响应,如果我们使用了同步请求与服务器端进行通信的话,一旦出现网络异常、或者服务异常的情况导致这个请求需要很长时间才能结束,那么就会导致浏览器的假死状态,不管你怎么操作页面都不会有响应,所以实际情况下AJAX中很少用同步请求方式来通信
如果要区分课程里的同步数据和异步数据的话可以这么理解:
当我们在浏览器里输入一个地址回车时,如果数据是跟着这个页面一起回来的(此时你可以通过右键查看源码看到的),我们称之为同步数据,一般在服务器端模板中直接填出来
如果数据是页面通过ajax方式调用某个api取到的(此时你可以通过开发工具的网络选项看到这个请求),我们称之为异步数据,一般需要服务器端提供这个接口
前端人员最终提交的是哪种页面?是模板文件吗?
[蔡老师]对于使用服务器端模板来分离控制层和视图层的项目,前端除了输出webRoot下的内容(如css、js、html等)外,同时还需要输出服务器端模板(常见的服务器端java模板如 freemarker、velocity 等)
后续补充
模板机制是一种通用的用于将数据与结构进行分离的解决方案,各种语言都可以实现自己的模板机制,包括 @yjcyxky 提到的Jinja就是用python实现的模板引擎,而我们范例里面提到的freemarker、velocity等等这些就是java实现的模板引擎,用javascript实现的就更多了,如 @yjcyxky提到的JQuery中的tmpl模板引擎、Handlebars、easyTemplate、underscoreTemplate、Mustache 等等,后面技术选型课程里也会有提到
@不会结束 提到的希望前后端使用统一的模板,这也不是说不行,主要看你们公司项目开发的协作方式,如果控制层用的是nodejs,那么我们在后端动态页面生成的过程也可以选择使用js的模板引擎来,而至于怎么选择模板引擎我们在技术选型课程里的模板技术里也会有说明
@nicholaslcj 问的服务器端的模板使用情况,主要要看服务器端控制层用的什么技术、什么语言来实现的,然后再选择对应的模板,像网易因为大部分产品后端都是java,所以用freemarker和velocity会比较多,而之于这两者怎么选型主要考虑的是技术的熟练程度和已有的实践积累,像杭州研究院这边会以freemarker为主,因为从06年开始就已经使用这个模板技术,该碰到的问题也都碰到过了,像网易广州、网易北京可能用的velocity会比较多,因为他们对这方面的积累会比较多,而且内部有些效率工具也会有针对性的对这些特定的模板做一些支持
模板机制除了这里我们看到的字符串拼接的模板外,还有一种是数据双向绑定的模板,比如 网易出品的 regularjs ( http://regularjs.github.io/ )等,我们在课程中也有讲解,这是两种完全不同的编程体验,有兴趣的可以进一步深入了解一下
模板机制可以帮助我们:
- 分离结构和数据,各自的变化不会应到到彼此
- 重用结构,通用的结构可以用模板语言做进一步的组件封装
- 最重要的就是增加了页面的后续维护性