运维必备--如何彻底解决数据库的锁超时及死锁问题
之前有介绍过,我主要是做数据仓库运维的,业余也会动手写 python 程序,django 应用,vue 的 app,有兴趣可以加我好友一起学习。最近比较让我头疼的是数据仓库的 datastage 作业经常报 911 错误,最终问题得到了解决,在此总结一下,希望能帮到要解决 911 错误的朋友们。
先介绍下数据仓库的概念:
一个面向主题的、集成的、非易失性的、随时间变化的数据的集合,以用于支持管理决策过程,是一个典型的 OLAP(Online analytical processing)系统。
数据仓库的架构如下图所示:
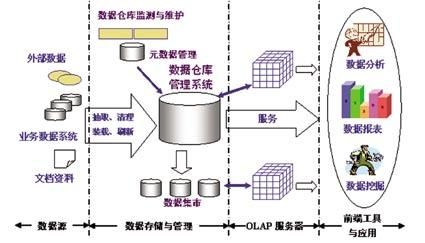
上图中从数据的抽取、加工转换、到数据集市、到最后的数据分析、报表,有数以万计的加工程序,数据库连接的进程也是成百上千,这也是最容易出现 911 报错的场景。
1、什么是 911 ?
911 是 db2 数据库的一种错误码,表示锁超时或死锁。锁超时就是一个事务 A 需要的资源正在被别的事务 B 占有,假如数据库设置的超时时间为 60 秒,超过了 60 秒,事务 B 仍没有释放资源,那么事务 A 将报锁超时错误并回滚。而死锁就是事务 A 需要的资源正在被事务 B 占有,事务A 等待,事务 B 需要的资源正在被事务 A 占有,事务 B 也等待,那么就发生了死锁,此时数据库会选一个成本较小的事务进行回滚。
2、什么情况会发生 911
我们已经知道 911 是关于锁的一种错误,要么是锁超时,要么是死锁。那么就需要对锁有一个细致地了解,上一篇文章介绍过【运维必备之db2 的锁】,默认情况下,db2 的 select 语句的隔离级别是【游标稳定性(Cursor Stability)】,即 select * from table with cs , 这种隔离级别会在查询的行上加上 NS 锁,NS 锁的中文名称叫【下一键共享锁(Next Share)】,拥有者与其他程序都可以读取该行,但不能进行修改。比如当一个进程(事务) A 正在查询该行时,进程(事务) B 试图更新(update)该行,那么进程(事务) B 就会等待,如果超过 60 秒(假如数据库设置超时为 60 秒),进程(事务) A 仍在查询中,没有释放,那么进程(事务) B 就会回滚,并报 911 错误,有些进程还会提示原因码为 68。
而有些工具为了支持并发,如 datastage ,会将一个批量更新或插入的语句拆分成多个进程同时执行,从而提高效率。如果多个进程同时 update 相同的多行数据。 比如:一个进程(事务) A 已经修改行 1,但未提交,准备修改行 2 后一起提交,但行 2 上有排他锁 X , 进程(事务) B 已经修改行 2,但未提交,准备修改行 1 后一起提交,但行 1 上有排他锁 X,此时 A 与 B 互相等待,进入死锁,死锁后,数据库会选择一个事务进行回滚,一般选择已花费成本较少的那个回滚,被回滚的那个事务会报 911 错误。
3、解决的过程
解决 911 的过程,就是要找到避免发生 911 的根本原因,减少事务发生 911 的条件。
定位问题
首先要定位出导致锁等待或锁超时的事务,db2 提供了锁定事件监控器以捕获其锁定数据的活动。 这些类型包括:
- SQL 语句,例如:DML 、DDL 、CALL
- LOAD 命令
- REORG 命令
- BACKUP DATABASE 命令
- 实用程序请求
锁定事件监控器会自动捕捉引起锁等待、锁超时、死锁的详细信息,如锁的拥有者,锁的请求者,导致以上三种事件的SQL语句等。
数据库相应的配置参数如下:
| 参数 | 捕捉类型 |
|---|---|
| MON_LOCKWAIT | 锁等待 |
| MON_LOCKTIMEOUT | 锁超时 |
| MON_DEADLOCK | 死锁 |
还有一个参数 MON_LW_THRESH 是控制 MON_LOCKWAIT 的事件之前等待锁定时花费的时间,以微秒为单位。
通过 db2 get db cfg 命令可以看到这些参数的值 :
$ db2 get db cfg
......省略
Lock timeout events (MON_LOCKTIMEOUT) = HIST_AND_VALUES
Deadlock events (MON_DEADLOCK) = HIST_AND_VALUES
Lock wait events (MON_LOCKWAIT) = NONE
Lock wait event threshold (MON_LW_THRESH) = 30000000
......省略
MON_LOCKTIMEOUT 和 MON_DEADLOCK 取值范围与 MON_LOCKWAIT 相同,含义类似:
- NONE,不会在任何分区中收集工作负载的锁定超时数据。
- WITHOUT_HIST,发生锁定事件时,会将关于锁定事件的数据发送到任何活动的锁定事件监视器。不会将过去的活动历史记录以及输入值发送到事件监视器。
- WITH_HIST,对于所有此类锁定事件,都可以收集当前工作单元中的过去活动历史记录。活动历史缓冲区将在达到最大大小限制后回绕。这意味着,要保留的过去活动数的缺省限制是 250。如果过去活动的数目高于此限制,那么将只报告最新的活动。
- HIST_AND_VALUES,对于那些包含输入数据值的活动,会将那些输入数据值发送到任何活动的锁定事件监视器。这些数据值不包括 LOB 数据、更改开始 LONG VARCHAR 数据、LONG VARGRAPHIC 数据、更改结束结构化类型数据或 XML 数据。
开启锁定事件监视器
自 DB2V9.7 版本之后,IBM 不推荐继续使用早期的死锁事件监视器(CREATE EVENT MONITOR FOR DEADLOCKS 语句和 DB2DETAILDEADLOCK),同时不推荐使用锁定超时报告功能(DB2_CAPTURE_LOCKTIMEOUT 注册表变量)。不过在新创建的数据中,默认还是创建了 DB2DETAILDEADLOCK 事件,因此如果我们希望使用锁定事件监视器,最好执行下面语句予以删除。
清单 1. 删除默认死锁事件监视
#请使用实例用户执行 **inst
db2 "SET EVENT MONITOR DB2DETAILDEADLOCK state 0 "
db2 "DROP EVENT MONITOR DB2DETAILDEADLOCK"
#下面是执行示例
$ db2 "SET EVENT MONITOR DB2DETAILDEADLOCK state 0 "
DB21034E The command was processed as an SQL statement because it was not a
valid Command Line Processor command. During SQL processing it returned:
SQL0204N "DB2DETAILDEADLOCK" is an undefined name. SQLSTATE=42704
$ db2 "DROP EVENT MONITOR DB2DETAILDEADLOCK"
DB21034E The command was processed as an SQL statement because it was not a
valid Command Line Processor command. During SQL processing it returned:
SQL0204N "DB2DETAILDEADLOCK" is an undefined name. SQLSTATE=42704
如果出现以上的输出信息,说明默认的死锁事件监视器已经被删除了,可不理会。
清单 2. 修改锁事件监控配置参数,并开启事件监视器
#设置锁定事件监视器的参数
$ db2 "update db cfg using MON_LOCKTIMEOUT HIST_AND_VALUES MON_DEADLOCK HIST_AND_VALUES MON_LOCKWAIT NONE"
DB20000I The UPDATE DATABASE CONFIGURATION command completed successfully.
#创建锁定事件监视器
$ db2 "create event monitor locktimeoutdeadlock for locking write to UNFORMATTED EVENT TABLE"
DB20000I The SQL command completed successfully.
#开启锁定事件监视器
$ db2 "set event monitor locktimeoutdeadlock state 1"
SQL20156W The event monitor was activated successfully, however some
monitoring information may be lost. SQLSTATE=01651
$ db2 get db cfg
------------------------------- 省略 -------------------------
Unit of work events (MON_UOW_DATA) = NONE
Lock timeout events (MON_LOCKTIMEOUT) = HIST_AND_VALUES
Deadlock events (MON_DEADLOCK) = HIST_AND_VALUES
Lock wait events (MON_LOCKWAIT) = NONE
Lock wait event threshold (MON_LW_THRESH) = 5000000
上述示例中设置了 MON_LOCKWAIT 为 NONE,表示不捕捉锁等待事件,当然也可以设置为捕捉,但锁等待事件较多时会引起下述表记录数的快速增长。
$ db2 list tables for all | grep -i locktimeoutdeadlock
LOCKTIMEOUTDEADLOCK TESTINST T 2018-12-05-11.57.47.835768
表 TESTINST.LOCKTIMEOUTDEADLOCK 保存了捕捉到的事件信息,但是非格式化的,这样做的目的是减少锁事件监控器对数据库的性能消耗。为了更清楚地看出我们捕捉到的事件信息,有两种方法:
方法一、生成格式化的表
db2 "call EVMON_FORMAT_UE_TO_TABLES ( 'LOCKING', NULL, NULL, NULL, NULL, NULL, 'RECREATE_FORCE', -1, 'SELECT * FROM locktimeoutdeadlock ORDER BY event_timestamp')"
会生成以下和个格式化的表
$ db2 list tables for all | grep -i "lock_"
LOCK_ACTIVITY_VALUES TESTINST T 2018-12-03-14.51.20.975705
LOCK_EVENT TESTINST T 2018-12-03-14.51.20.849810
LOCK_PARTICIPANT_ACTIVITIES TESTINST T 2018-12-03-14.51.20.912028
LOCK_PARTICIPANTS TESTINST T 2018-12-03-14.51.20.878247
里面的信息已经非常清楚了,读者可以自行查询分析,如果仍无法自行分析的,可参考官网的查询语句进行分析:DB2 V9.7 锁事件监控
方法二、生成格式化的文本文件
db2 自代的 java 环境和生成格式化文本的工具 db2evmonfmt。
在db2 的安装目录下找到 DB2EvmonLocking.xsl,db2evmonfmt.java,复制到自己的目录中:
cp /opt/IBM/db2/V9.7/samples/java/jdbc/db2evmonfmt.java ~/mydir
cp /opt/IBM/db2/V9.7/samples/java/jdbc/DB2EvmonLocking.xsl ~/mydir
然后将 db2evmonfmt.java 编译为 class 文件:
cd ~/mydir
/home/testinst/sqllib/java/jdk64/bin/javac db2evmonfmt.java
最后生成格式化的文本文件:
/home/testinst/sqllib/java/jdk64/bin/java db2evmonfmt -d testdb -ue locktimeoutdeadlock -ftext >/tmp/lockinfo.txt
查看 /tmp/lockinfo.txt 即可得到相关的锁事件信息,从而精准定位出锁超时和死锁的原因。下图为 lockinfo.txt 的一个片断,从中可以清楚地看到锁的拥有者和请求者。

对策
定位出原因后就要想对策了。如果临时处理:如果请求者事务的优先级高,那就让拥有锁的事务回滚,可以通过db2 "force application (agent id) “ 来结束事务,从而从拥有者那里释放锁。再次开启请求者事务即可。
长远规划 :
- 针对 911 超时:
1、如果数据库的事务普遍比较耗时,可适当增加 db2 数据库的锁超时时间
$ db2 get db cfg| grep -i lock
Lock timeout (sec) (LOCKTIMEOUT) = 120
2、如果事务的时效性要求并不高,可采取出错重试的方式来解决,现在的调度工具都提供出错重试功能,当一个任务偶尔报911 错误时可以设置重出错自动重试,比如重试次数为 3 ,每次间隔 5 分钟。
3、提升事务的隔离级别,假如有两个事务 A和 B
,A 为更新操作,B 为读取操作,默认情况下,如果 A 在更新时,B 读取,如果B 读取的时间过长,那么 A
很有可能报锁超时错误,此时可以提升 A 的隔离级别,可提升至
可重复读级别,此时 A 在更新时, B 只能等待,或者允许 B 脏读,即 select 语句 后面加 with ur,此时 B 读取表时并不加行锁。
4、优化 SQL 语句,提升查询事务的效率,减少 SQL 执行时间;对于大数据量的更新或插入操作,可分步 commit ,减少锁的占用。
- 针对 911 死锁:
提升事务的隔离级别也可有效避免死锁,最有效的办法还是找出导致死锁的事务或进程,安排在不同地时间段执行。
(完)
公众号 somenzz 坚持原创,和你一起学习技术。
