数据源:融360-用户贷款风险预测
参考资料:https://www.jianshu.com/p/aba5685c580a
流程如下:
项目目标
数据解读
数据预处理
-
特征工程
1.基于业务理解筛选
2.基于机器学习筛选
模型建立
一、项目目标
通过举办方提供的用户基本信息,消费行为,还款情况等,建立准确的逾期预测模型,以预测用户是否会逾期还款。
二、数据解读
相关专业名词可以去举办方融360官网上搜索https://www.rong360.com/ask/
1.数据概述:
用户的基本属性user_info.txt
银行流水记录bank_detail.txt
用户浏览行为browse_history.txt
信用卡账单记录bill_detail.txt
放款时间loan_time.txt
逾期行为的记录overdue.txt
(注意:并非每一位用户都有非常完整的记录,如有些用户并没有信用卡账单记录,有些用户却没有银行流水记录。同时需要注意的是数据做过脱敏处理:(a) 隐藏了用户的id信息;(b) 将用户属性信息全部数字化;(c) 将时间戳和所有金额的值都做了函数变换。)
2.数据详细描述:
(1)用户的基本属性user_info.txt。共6个字段,其中字段性别为0表示性别未知。 用户id,性别,职业,教育程度,婚姻状态,户口类型 6346,1,2,4,4,2
(2)银行流水记录bank_detail.txt。共5个字段,其中,第2个字段,时间戳为0表示时间未知;第3个字段,交易类型有两个值,1表示支出、0表示收入;第5个字段,工资收入标记为1时,表示工资收入。 用户id,时间戳,交易类型,交易金额,工资收入标记 6951,5894316387,0,13.756664,0
(3)用户浏览行为browse_history.txt。共4个字段。其中,第2个字段,时间戳为0表示时间未知。 用户id,时间戳,浏览行为数据,浏览子行为编号 34724,5926003545,172,1
(4)信用卡账单记录bill_detail.txt。共15个字段,其中,第2个字段,时间戳为0表示时间未知。为方便浏览,字段以表格的形式给出。 文件示例如下: 用户id,账单时间戳,银行id,上期账单金额,上期还款金额,信用卡额度,本期账单余额,本期账单最低还款额,消费笔数,本期账单金额,调整金额,循环利息,可用金额,预借现金额度,还款状态 3147,5906744363,6,18.626118,18.661937,20.664418,18.905766,17.847133,1,0.000000,0.000000,0.000000,0.000000,19.971271,0 上期账单金额: 上月需要向信用卡还款的金额 上期还款金额:上月用户已还款的金额 信用卡额度:信用额度(即信用卡最高可以透支使用的限额)+ 存入信用卡的金额。 本期账单余额:指截止到出账单日,本期账单还未还的金额。 本期账单最低还款额:最低还款额=信用额度内消费款的10%+预借现金交易款的100%+前期最低还款额未还部分的100%+超过信用额度消费款的100%+费用和利息的100% 消费笔数:用户在账单期内的消费记录总数 本期账单金额:本期需要向信用卡还款的金额 调整金额:有可能是原先多还的款项, 在下期还款时会去掉这部分的金额 循环利息:当您偿还的金额等于或高于当期帐单的最低还款额,但低于本期应还金额时,剩余的延后还款的金额银行会计算相应的利息。 可用余额:信用额度-未还清的已出账金额-已使用未入账的累积金额 预借现金额度:是指持卡人使用信用卡通过ATM等自助终端提取现金的最高额度 还款状态:0--未还款,1--已还款
(5)放款时间信息loan_time.txt。共2个字段,用户id和放款时间。 用户id,放款时间 1,5914855887 银行发放贷款的时间
(6)顾客是否发生逾期行为的记录overdue.txt。共2个字段。样本标签为1,表示逾期30天以上;样本标签为0,表示逾期10天以内。注意:逾期10天~30天之内的用户,并不在此问题考虑的范围内。用于测试的用户,只提供id列表,文件名为testUsers.csv。 用户id,样本标签 1,1 此处可理解为1是逾期、0是未逾期
号:923414804 群里有志同道合的小伙伴,
互帮互助。群里有视频学习教程和PDF,一起学习,共同进步!
加群免费获取数十套PDF资料,助力python学习
三、数据预处理
导入数据,检查缺失,统计用户id量、
看下缺失值情况:

没有缺失,再看用户id情况:
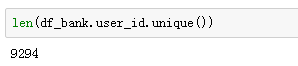
有9294个用户有银行流水记录
同理导入其他表格信息:

看下,个表格的用户id数:

各个表格的id数不一样,说明并非每个用户都有银行卡流水,账单等信息;所以下一步就是整合6张表格,然后根据共有用户id匹配完整信息,没有完整信息的id去掉。
说明:我们要预测的测试集是没有放款的客户,因此训练集分析使用客户放款之前的信息,将有时间截的表与放款表交叉,只筛选放款前的客户id

通过上面各个表的信息情况,可以看到除了放款时间表外有时间字段的是银行流水记录表、账单记录表、浏览信息表。
time_x表示流水记录时间,time_y表示放款时间:
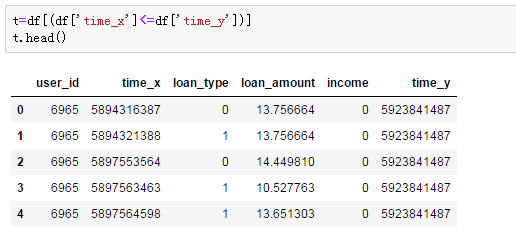
去重客户数:
9271个客户
同理其他表格也做此处理:

得出5735个用户的记录是完整的。然后通过这5735个id筛选每张表的记录,并进行字段预处理。
数据预处理:
(1)银行流水表:整理收入,支出,工资:
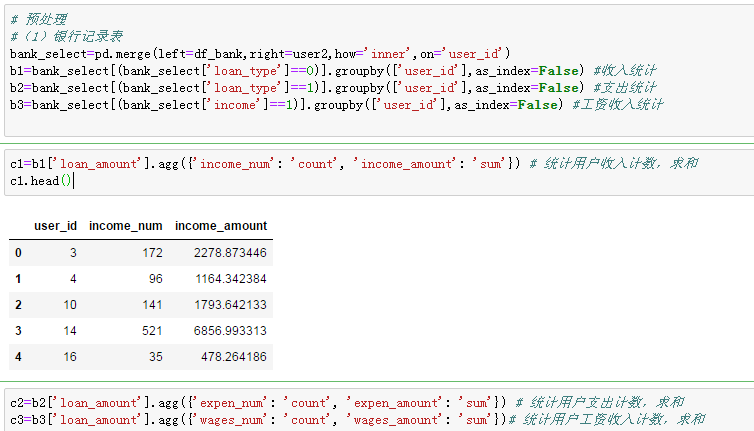
把收入支出工资分别与用户表交叉(只筛选5735个完整用户的信息):

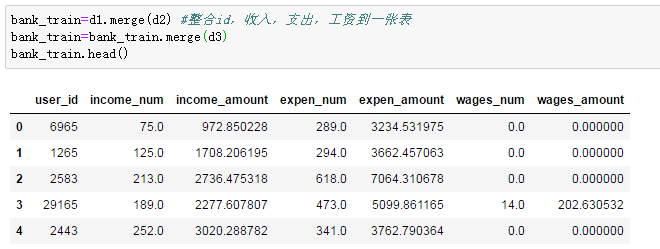
把收入支出工资整合到一个表里(注意此处是左链接how='left'):
(2)浏览表:先剔除5735以外的数据,再统计每个用户的浏览记录(count)

统计浏览条数(count):

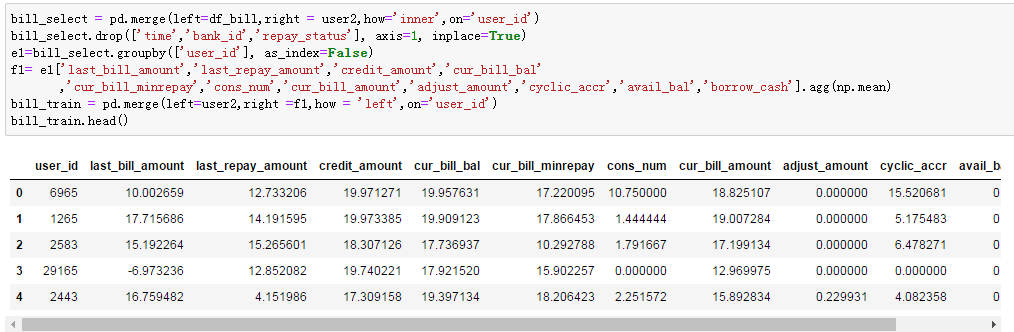
(3)账单表:
去掉了时间、银行id、还款状态这几个变量,按用户id分组后对每个字段均值化处理
(4)逾期表,用户表:
直接匹配5735个最终用户即可

把前面整理好的表整合:
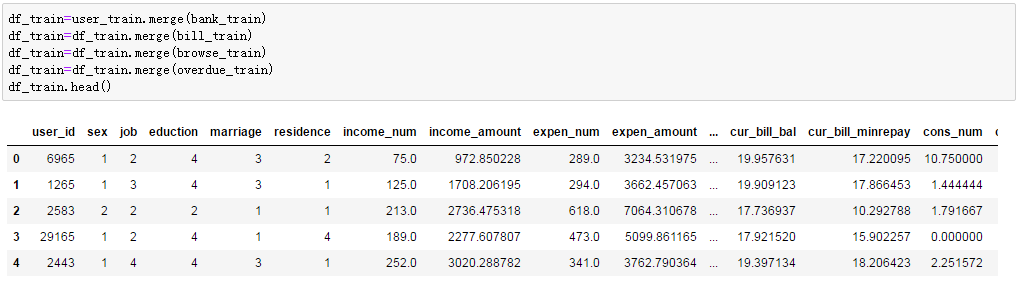
查看最后表信息:

一共有25个字段
四、特征工程
(1)基于业务理解筛选
主要看相关性
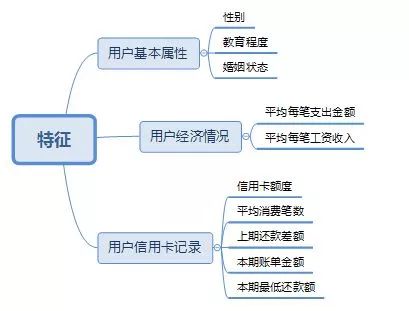
对特征做一下分类:

首先看一下用户的基本属性:
基于我自己的理解,跟逾期行为相关的因素有:性别,年龄,教育程度,婚姻情况,收入,用户是否有放贷,车贷等其他经济情况。案例数据里我们可以先筛选出:性别,教育程度,婚姻状况。
(职业,户口类型这两个特征虽然能反映用户的收入情况,但不确定性很大,所以不考虑筛选进来,我们可以从用户在银行的收入/支出记录来侧面反映用户的经济情况)
所以第一步筛选的特征为:
sex ,education,marriage,income_num,income_amount,expen_num,expen_amount,wages_num,wages_amount。
再看下这些特征的相关性:
银行流水:

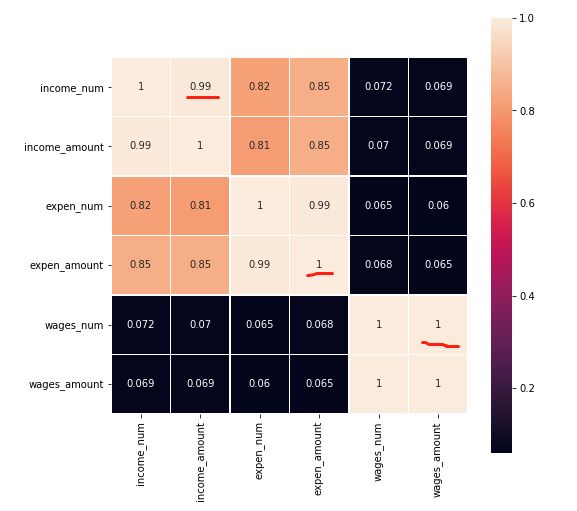
可见收入、支出、工资三个指标的金额跟笔数是线性关系,那么后续将构建一个新的特征:笔均=金额/笔数,取工资笔均;而且收入、支出是强相关(0.82),所以只取一个即可,支出笔均。
账单:


从图中可以看出俩俩之间相关性程度比较高的特征有:
上期账单金额last_bill_amount,上期还款金额last_repay_amount
,本期账单金额cur_bill_amount, 额度credit_amount这四者之间,另外还有本期余额cur_bill_bal 与 本期最低还款cur_bill_minrepay。
说明:
本期应还金额 = 上期账单金额-上期还款金额 + 本期账单金额 - 本期调整金额 + 循环利息
这个公式的意思是:
上期还款金额 <上期账单的最低还款额(一般是账单金额*10%)或者不还,就视为逾期,而且本期的还款要加上循环利息和上期未还款的那部分。
上期最低还款额<上期还款金额<上期账单金额,不视为逾期,但本期的还款要加上循环利息
上期还款金额 >上期账单金额,也就是说用户还多了,那么本期的还款会减去一个调整金额(多还的那部分),循环利息不计。
所以上期的账单金额与还款金额是密切相关的,相关系数也高,可以引入一个新的特征:
上期还款差额 =上期账单金额 - 上期还款金额, 上期还款差额还会直接影响用户的信用额度以及本期的账单金额。
本期的账单余额与最低还款额具有高度共线性,决定只选用最低还款额。
另外调整金额和循环利息是跟“上期的还款差额”有关的:
还款差额>0,需要计算循环利息,调整金额不计
还款差额<0,需要计算调整金额,循环利息不计
所以可以将还款差额进行“特征二值化”来代替这两个特征。
可用余额=银行核定的信用卡额度-尚未交还的账单上欠款-未入账但已发生的交易金额-其他相关利息、费用。所以可用余额与信用卡额度,上期还款差额,循环利息等都有一定的关系,但让我感到奇怪的是,相关系数图上并没有表现出来,所以暂时不筛选进这个特征。
预借现金额度,是指持卡人使用信用卡通过ATM等自助终端提取现金的最高额度,取现额度包含于信用额度之内,一般是信用额度的50%左右,所以可以不用这个特征,选择信用额度即可。
讲了这么多,现在可以筛选出我们要的信用卡记录特征了:
last_repay_diff(上期还款差额),credit_amount,cur_bill_minrepay,cur_bill_amount,cons_num这5个特征。
最后我们把基于业务理解的特征选择结果展示出来:
重新构建数据表:


(2)基于机器学习筛选
根据业务理解筛选的特征数仍有11个,故还需要用机器学习的方法对特征作进一步降维。
在筛选前我们将last_repay_diff这个特征作“二值化”(0,1)处理:
11个特征中sex,education,marriage,last_diff_label为分类变量,其它为连续型数值变量。
我们采取两种特征选择方法:filter法和Wrapper法
--Filter法筛选:


筛选的结果为:'sex' ,'education', 'expen_avg', 'wages_avg', 'cur_bill_minrepay'
--Wrapper法:

筛选结果为:'expen_avg', 'credit_amount', 'cur_bill_amount', 'cur_bill_minrepay', 'brows_beh'
发现俩种方法筛选的结果相差很大,wrapper法没有选择任何一个分类型变量,而filter法选择了“sex”和“education”两个分类型变量,相同点是都选择了expen_avg和cur_bill_minrepay。
用交叉检验的方法看一下哪种方法好吧:
from sklearn.model_selection import cross_val_score
x_test1 = df_select[['sex','education','expen_avg','wages_avg','cur_bill_minrepay']]
x_test1 = np.array(x_test1)
y_test1 = df_select[['overdue']]
y_test1 = np.array(y_test1)
m1 = DecisionTreeClassifier()
m1.fit(x_test1,y_test1)
scores = -cross_val_score(m1, x_test1, y_test1, cv=5, scoring= 'neg_mean_absolute_error')
print(np.mean(scores))
filter法结果为:0.24080262097612498
from sklearn.model_selection import cross_val_score
x_test2 = df_select[['expen_avg','credit_amount','cur_bill_amount','cur_bill_minrepay','brows_beh']]
x_test2 = np.array(x_test2)
y_test2 = df_select[['overdue']]
y_test2 = np.array(y_test2)
m2 = DecisionTreeClassifier()
m2.fit(x_test2,y_test2)
scores = -cross_val_score(m2, x_test2, y_test2, cv=5, scoring= 'neg_mean_absolute_error')
print(np.mean(scores))
Wrapper法结果为:0.2537052432049981
交叉检验的结果表明还是用Filter法好一点(越小越好),接下来就是建模了,既然筛选的5个特征既有分类型,又有连续型,用决策树。
五、数据建模
1.拆分训练集和测试集数据:比例为4:1
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 0)
\2. 设定决策树参数,进行建模
这里采用的是决策树里的CART法,之所以不用ID3和C4.5,是因为这两个方法不能处理连续型数据,必须转换成离散型。
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='gini', #划分属性的选择标准,基尼系数,entropy信息增益
splitter='best', #在节点中选择的分类策略(best 最好的)
max_depth=3, #树的最大深度
min_samples_split=10, #区分一个内部节点所需要的最少样本数
min_samples_leaf=5 #叶子节点所需要的最小样本数
)
clf = clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
y_pred = y_pred[:, np.newaxis]
y_pred

3.模型结果评价
看一下模型结果分析报告:
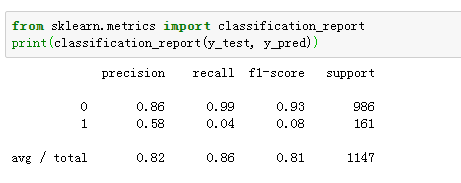
精确率0.82,召回率0.86,f1_score为0.81,模型的综合评价还是可以的。
接下来可以对模型进行调参,在这里我主要对树的深度进行了不同设置,发现当树的深度为3时,模型的结果是比较好的。
另外决策树最大的问题是会容易出现”过拟合”,我在网上看到的解决方法主要有俩种:
1.对树进行剪枝,包括预剪枝和后剪枝
2.用随机森林的方法,进行随机选取样本和随机选取属性