Python机器学习(二):Logistic回归建模分类实例——信用卡欺诈监测(上)
Logistic回归建模分类实例——信用卡欺诈监测
现有一个creditcard.csv(点此下载)数据集,其中包含不同客户信用卡的特征数据(V1、V2……V28、Amount)和标签数据(Class),利用Logistic回归建模,通过这个模型预测客户信用卡是否有被欺诈的风险。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
data = pd.read_csv('creditcard.csv')
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1,1))
data = data.drop(['Amount','Time'], axis=1)
#data.head()% matplotlib inline表示将图表嵌入到Notebook中。如果不加这一行代码,下面的图2中的柱状图会显示不出来。
将creditcard.csv中的数据读到data中,因为creditcard.csv中的数据中Amount这一列比较特殊,其他列都在(-1,1)的区间内,而Amount这一两列浮动范围比较的,要知道特征数据的浮动范围越大,在建模过程中对于预测结果的影响就越大,但就这组数据来说我们并有足够的先验信息来说明特征数据的重要程度,故我们要对所有特征数据一视同仁,让他们都在(-1,1)之间。所以我们要对数据进行一些预处理,首先就要通过sklearn.preprocessing中的StandardScaler模块将Amount这一列的数据进行归一化(标准化)操作。而后数据中有一列是Time,这一列数据是无用的,也就是说对于信用卡欺诈预测是没有用的,所以我们要将其删掉。
注意:data.drop([‘Amount’,’Time’], axis=1) 不会改变data本身,所以要将其赋值给data。笔者在用的时候以为它和reverse(),sort()这些函数一样会改变数据本身,在这儿踩了一脚坑。
data[‘Amount’].values.reshape(-1,1)中reshape后(-1,1)表示将这个数组变换成X*1的形式,至于X是多少就要看原始数组中到底有多少元素了。
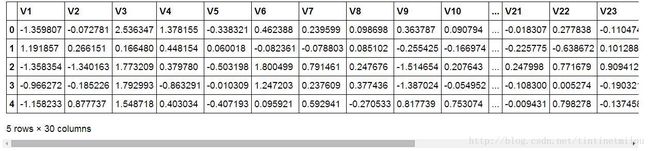
因为一般情况下,我们得到的原始数据集中都是不能直接拿来用的,它们要么有大量无用信息,要么有缺失数据……,总之对于原始数据的预处理是必不可少的。下面就是通过data.head()显示出来的处理完成的数据预览图。
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
print count_classes
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")通过matplotlib.pyplot来画一个图,统计一下数据中正负样本的个数,结果如下图所示:
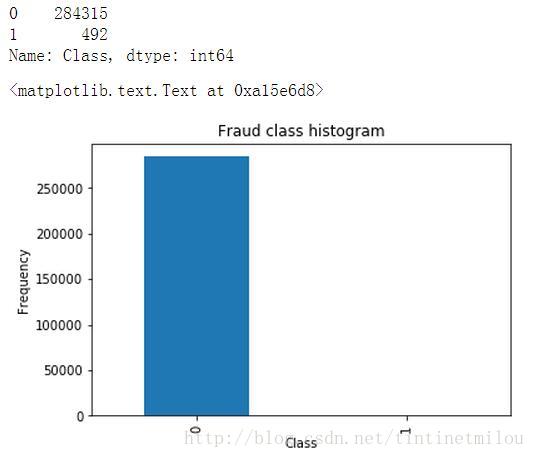
由图可知,我们的数据中的负样本(本例中1表示信用卡有被欺诈风险,为负样本)是很少的,这叫做样本不均衡,如果我们不进行处理,直接用这样的数据来进行训练建模,那得到的结果是很糟糕的(有多糟糕见下文)。所以我们要进行样本数据处理,这用两种方法:下采样和过采样。本篇博客主要介绍下采样的实现步骤,下一篇介绍过采样。
下采样
就是从数量比较多的那类样本中,随机选出和与数量比较少的那类样本数量相同的样本,最终组成正负样本数量相同的样本集进行训练建模。
X = data.ix[:,data.columns != 'Class']
Y = data.ix[:,data.columns == 'Class']
number_record_fraud = len(Y[Y.Class==1])
fraud_indices = np.array(data[data.Class == 1].index)
normal_indices = np.array(data[data.Class == 0].index)
random_normal_indices = np.array(np.random.choice(normal_indices,number_record_fraud,replace=False))
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
under_sample_data = data.iloc[under_sample_indices,:]
X_under_sample = under_sample_data.ix[:,under_sample_data.columns != 'Class']
Y_under_sample = under_sample_data.ix[:,under_sample_data.columns == 'Class']
from sklearn.cross_validation import train_test_split
X_train_under_sample,X_test_under_sample,Y_train_under_sample,Y_test_under_sample = train_test_split(X_under_sample,Y_under_sample,test_size=0.3,random_state=0)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)通过np.random.choice在正样本的索引(normal_indices)中随机选负样本个数(number_record_fraud )个索引。
np.concatenate将负样本和挑选的负样本索引进行合并成
根据上面得到的索引来去原始数据中提取特征(X_under_sample)和标签(Y_under_sample )
接下来是用klearn.cross_validation 模块中的train_test_split来将上面提取到的数据(特征,标签)分为训练集和测试集,测试占总体的30%。X_train, X_test, Y_train, Y_test是对原始未进行下采样的数据进行的同样操作得到的,这些数据后面测试的时候会用到。
交叉验证
机器学习中,当将要采用的机器学习算法确定后,模型训练的实质就是确定一系列的参数了(调参)。调参其实就是各种试,但也是有章可循的。首先要用一些数据和某个参数来训练得到一个模型,然后用另外一些数据来带入刚才训练好的模型,输出结果和标签进行比较,计算出来一个评价指标,根据这个评价指标来判断刚才带入的那个参数到底好不好。
先说上面的评价指标,最常见的评价指标为精度:
但精度很多时候并不靠谱,比如在样本数据不均衡时,负样本相对于所用样本很少,就算模型将全部样本都预测成正样本,那精度也是很高的,而事实上这个模型完全没用。
所用这里引入recall值:
其中TP(True Positive)表示预测对了且预测成正例的个数,FN(False Negative)则表示预测错了且预测成负例的个数。
综上:交叉验证就是先将训练数据分成n份(注意:是分训练样本,和测试样本没关系),其中n-1份用于训练模型,剩下的一份测试模型,得到一个recall值。n份样本遍历,每个都测试一次由另外n-1份样本训练得到的模型,这样就一共得到了n个recall值,求平均得到最终recall值。这就是交叉验证,它可以很大程度得降低样本中那些错误值和离群值对于模型评估和参数整定的影响。
这里还有一个概念正则化惩罚项:
为了防止模型的过拟合,就要求权重参数浮动稳定,所以,在目标(损失)函数后面加一项惩罚项。
L2正则化:
L1正则化:
C为惩罚力度,这样在训练的过程中,参数就会尽量向浮动稳定的方向收敛。
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold,cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
def printing_Kfold_scores(X_train_data,Y_train_data):
fold = KFold(len(Y_train_data),5,shuffle=False)
print fold
c_param_range = [0.01,0.1,1,10,100]
results_table = pd.DataFrame(index=range(len(c_param_range)),columns=['C_Parameter','Mean recall score'])
results_table['C_Parameter'] = c_param_range
j=0
for c_param in c_param_range:
print 'c_param:',c_param
recall_accs = []
for iteration,indices in enumerate(fold, start=1):
#print iteration,indices
lr = LogisticRegression(C = c_param, penalty = 'l1')
lr.fit(X_train_data.iloc[indices[0],:],Y_train_data.iloc[indices[0],:].values.ravel())
Y_pred_undersample = lr.predict(X_train_data.iloc[indices[1],:].values)
recall_acc = recall_score(Y_train_data.iloc[indices[1],:].values,Y_pred_undersample)
recall_accs.append(recall_acc)
print 'Iteration:',iteration,'recall_acc:',recall_acc
print 'Mean recall score',np.mean(recall_accs)
results_table.ix[j,'Mean recall score'] = np.mean(recall_accs)
j+=1
best_c = results_table.loc[results_table['Mean recall score'].idxmax()]['C_Parameter']
print 'best_c is :',best_c
return best_c
best_c = printing_Kfold_scores(X_train_under_sample,Y_train_under_sample)用KFload函数来生成交叉验证训练过程中训练和验证的数据的索引集合fold,其中参数5表示训练、验证集数量之比为4:1。fold相当于有5个元素,每个元素里面有两个array,分别为训练和验证数据的索引(可用for循环中的print iteration,indices查看)。
results_table为创建的DataFrame对象,来存储不同参数交叉验证后所得的recall值。
enumerate将一个可遍历对象(如列表、字符串)组成一个索引序列,获得索引和元素值,start=1表示索引从1开始(默认为0)。
LogisticRegression函数用来创建逻辑回归模型, penalty = ‘l1’,表示用L1正则惩罚项。
接下来是利用训练数据训练模型,用验证数据带入模型的结果求recall值。进而求得每个C参数的平均recall,以及最佳C参数。
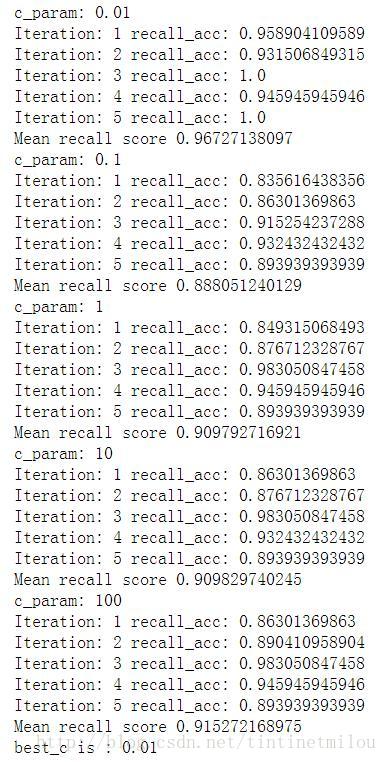
recall值来评价模型还是有一定的缺陷,现引入混淆矩阵来进一步对模型进行评估。
import itertools
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')现将下采样处理得到的测试数据带入模型,利用得到的预测结果和实际标签画出混淆矩阵
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train_under_sample,Y_train_under_sample.values.ravel())
Y_pred_undersample = lr.predict(X_test_under_sample.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(Y_test_under_sample,Y_pred_undersample)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", float(cnf_matrix[1,1])/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()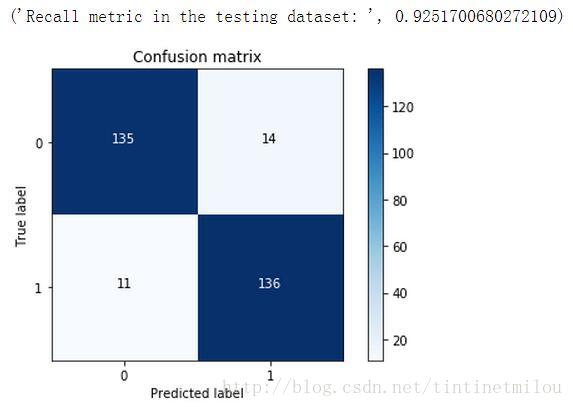
由图4所示的混淆矩阵可知recall和混淆矩阵的关系为:
可见recall只和TP和FN有关系,那当FP很大时(本来为0,没有欺诈风险,但预测为1,预测成有风险),所以在调参的时候不仅要看recall值,还要通过混淆矩阵,看看FP这个值。
上面是用下采样处理得到的测试数据来求recall和混淆矩阵的,因为下采样得到的数据相比于原始数据是很少的,所以这个测试结果没什么说服力,所以我们要用原始数据(没有经过下采样的数据)来进行测试。
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train_under_sample,Y_train_under_sample.values.ravel())
Y_pred = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(Y_test,Y_pred)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", float(cnf_matrix[1,1])/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
由上图可知,通过下采样处理数据得到的逻辑回归模型,虽然recall值挺高的,但NP值非常高,也就是误杀率非常高。这也是用下采样处理数据的一个弊端吧,如果采用过采样来处理数据,效果就会好很多。
前面说样本不均衡,如果不进行处理,直接用这样的数据来进行训练建模,那得到的结果是很糟糕,现在就看看到底有多糟糕。
best_c = printing_Kfold_scores(X_train,Y_train)
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train,Y_train.values.ravel())
Y_pred = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(Y_test,Y_pred)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", float(cnf_matrix[1,1])/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()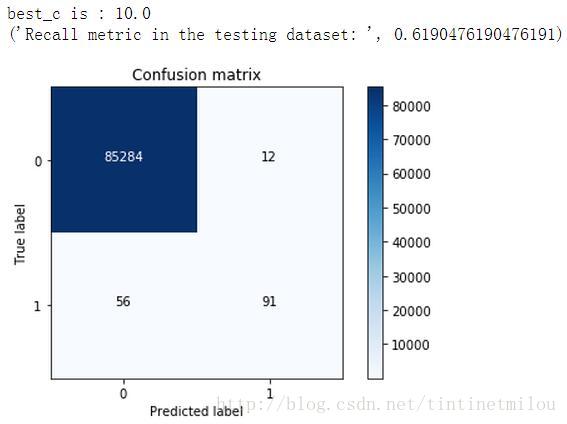
逻辑回归模型中除了惩罚力度参数C需要整定,Threshold也可以调调,默认不做处理相当于Threshold为0.5
lr = LogisticRegression(C = 0.01, penalty = 'l1')
lr.fit(X_train_under_sample,Y_train_under_sample.values.ravel())
y_pred_undersample_proba = lr.predict_proba(X_test_under_sample.values)
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10))
recall_accs = []
j = 1
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i
plt.subplot(3,3,j)
j += 1
# Compute confusion matrix
cnf_matrix = confusion_matrix(Y_test_under_sample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
recall_acc = float(cnf_matrix[1,1])/(cnf_matrix[1,0]+cnf_matrix[1,1])
print'Threshold>=%s Recall: '%i, recall_acc
recall_accs.append(recall_acc)
# Plot non-normalized confusion matrix
class_names = [0,1]
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Threshold>=%s'%i) 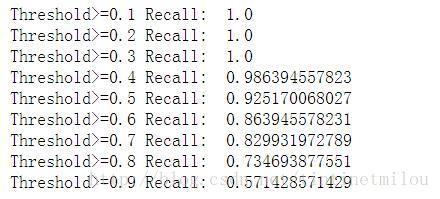
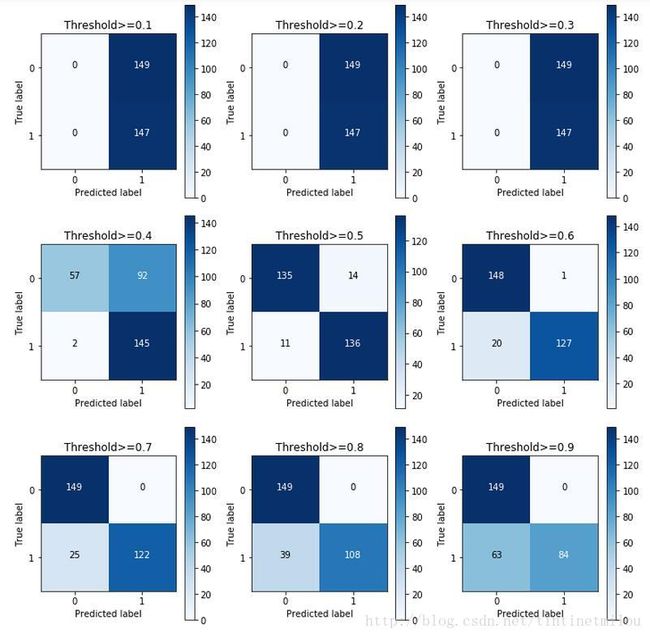
由上图看Threshold还是为0.5是较好。