论文阅读:Multi-view Convolutional Neural Networks for 3D Shape Recognition
Preface
今天阅读一篇ICCV2015的论文:《Multi-view Convolutional Neural Networks for 3D Shape Recognition》,简称:MVCNN。
这里是Paper Homepage
这里是Paper Code
这篇文章的创新点在于:
用物体的三维数据从不同“视角”所得到的二维渲染图,作为原始的训练数据。用经典、成熟的二维图像卷积网络进行训练,训练出的模型,对三维物体的识别、分类效果之好,比那些用三维数据直接训练出的模型好很多。原文用了“dramatically outperform”一词,可见效果之好。
相比于用三维立体数据直接训练,二维图像卷积网络成熟度、速度都是很大的优势。相当于将训练数据进行了“降维”处理,却还能有远超三维数据的效果。
Introduction
Although the simple strategy of classifying views independently works remarkably well (Sect. 3.2), we present new ideas for how to “compile” the information in multiple 2D views of an object into a compact object descriptor using a new architecture called multi-view CNN (Fig. 1 and Sect. 3.3).
尽管这个想法很简单,但是如何将一个物体的多视角下图像的特征信息进行“compile”(融合),也是个问题。由此,作者提出了Multi-view CNN(MVCNN)。
Moreover it facilitates efficient retrieval using either a similar 3D object or a simple hand-drawn sketch, without resorting to slower methods that are based on pairwise comparisons of image descriptors. We present state-of-the-art results on 3D object classification, 3D object retrieval using 3D objects, and 3D object retrieval using sketches (Sect. 4).
此外,这个MVCNN不光对于3D object classification有效,对于3D object retrieval using 3D objects、3D object retrieval using sketches也十分有效,都达到了state-of-art的效果。
Our multi-view CNN is related to “jittering” where transformed copies of the data are added during training to learn invariances to transformations such as rotation or translation. In the context of 3D recognition the views can be seen as jittered copies. The multi-view CNN learns to combine the views instead of averaging, and thus can use the more informative views of the object for prediction while ignoring others.
这地方,作者解释说,Multi-view CNN的思路类似于经典CNN网络训练前,对数据进行“jittering”(抖动)。
即对训练图像进行旋转、缩放、对称映射、平移等“copy”操作,一方面可以增加数据的量,另一方面可以CNN网络会自动去学习获得变换不变性(如旋转不变性、平移不变性)。
在3D识别分类的过程中,其Multi-view操作获得的多视角数据可以看成这种数据“jitter”的操作。
但是呢,MVCNN网络要去学习怎样去combine(结合)这些多视角的数据,而不是以前那样,仅仅在网络过程中对数据进行“averageing”,通过多视角图片的学习,可以获得更多的特征信息。
作者也通过实验证明了上述想法,MVCNN这种多视角与精心设计的学习比经典CNN的“数据抖动”,在sketch recognition benchmark上的表现,前者更优异。
Related Work
Our method is related to prior work on shape descriptors for 3D objects and image-based CNNs. Next we discuss representative work in these areas.
站在巨人的肩膀上。
Shape descriptors
Shape descriptors can be classified into two broad categories: 3D shape descriptors that directly work on the native 3D representations of objects, such as polygon meshes, voxel-based discretizations, point clouds, or implicit surfaces, and view-based descriptors that describe the shape of a 3D object by “how it looks” in a collection of 2D projections.
形状描述算子可以大致分为两大类:
1. 3D shape descriptors,直接在原始的三维数据上进行描述表示。
a. polygon meshes(多边形网格)
b. voxel-based discretizations(基于“体素”的离散化)
c. point cloud(点云)
d. implicit surfaces(隐式曲面)。隐式曲面我第一次碰到,如下图:

2. viewbased descriptors
用二维投影的方法去描述三维物体,“how it looks”,长得啥样。
With the exception of the recent work of Wu et al. [37] which learns shape descriptors from the voxel-based representation of an object through 3D convolutional nets, previous 3D shape descriptors were largely “hand-designed” according to a particular geometric property of the shape surface or volume. For example, shapes can be represented with histograms or bag-of-features models constructed out of surface normals and curvatures [15], distances, angles, triangle areas or tetrahedra volumes gathered at sampled surface points [25], properties of spherical functions defined in volumetric grids [16], local shape diameters measured at densely sampled surface points [4], heat kernel signatures on polygon meshes [2, 19], or extensions of the SIFT and SURF feature descriptors to 3D voxel grids [17].
上面“啪啦啪啦”说了一大堆……=。=……
除了Wu et al.从3D卷积网络中提取三维特征,之前三维特征主要是“hand-designed”,人手设计的特征,根据三维物体表面或立体形状的几何性质来“人工设计”。如:
1. represented with histograms or bag-of-features models constructed out of surface normals and curvatures [15]
2. distances, angles, triangle areas or tetrahedra volumes gathered at sampled surface points [25]
3. properties of spherical functions defined in volumetric grids [16]
4. local shape diameters measured at densely sampled surface points [4]
5. heat kernel signatures on polygon meshes [2, 19]
6. extensions of the SIFT and SURF feature descriptors to 3D voxel grids [17]
Developing classifiers and other supervised machine learning algorithms on top of such 3D shape descriptors poses a number of challenges.
First, the size of organized databases with annotated 3D models is rather limited compared to image datasets, e.g., ModelNet contains about 150K shapes (its 40 category benchmark contains about 4K shapes). In contrast, the ImageNet database [9] already includes tens of millions of annotated images.
Second, 3D shape descriptors tend to be very high-dimensional, making classifiers prone to overfitting due to the so-called ‘curse of dimensionality’.
这一段作者讲述了在监督学习算法设计中,直接在三维数据上提取描述算子的难度。
有两处,一处是有组织、标注的三维数据的数量相比于二维图像,太少了。仅仅一个ImageNet,就已是百万级别的了。相比之下,Princeton大学Wu et al. 建立的ModelNet三维形状库才有150K的形状数据(仅仅40个类别,每个类别大约40K个三维形状数据)。另一处难度便是著名的“curse of dimensionality”(维数灾难)。
On the other hand view-based descriptors have a number of desirable properties:
they are relatively low-dimensional, efficient to evaluate, and robust to 3D shape representation artifacts, such as holes, imperfect polygon mesh tesselations, noisy surfaces.
The rendered shape views can also be directly compared with other 2D images, silhouettes or even hand-drawn sketches.
其实我这一段没看懂他在说什么。因为缺少一些背景知识,像silhouette,翻译成“剪影”,不太明白说什么。先粗糙的讲下:
而另一方面,基于三维形状视角的描述算法则有很好的优点。
没有“维数灾难”的问题,更高效的评价,对人工的三维形状表示更鲁棒。
三维形状的渲染图也可以直接与其他如二维图像、“剪影”甚至手绘的草图相比较。
An early example of a view-based approach is the work by Murase and Nayar [24] that recognizes objects by matching their appearance in parametric eigenspaces formed by large sets of 2D renderings of 3D models under varying poses and illuminations.
Another example, which is particularly popular in computer graphics setups, is the LightField descriptor [5] that extracts a set of geometric and Fourier descriptors from object silhouettes rendered from several different viewpoints.
Alternatively, the silhouette of an object can be decomposed into parts and then represented by a directed acyclic graph (shock graph) [23].
Cyr and Kimia [8] defined similarity metrics based on curve matching and grouped similar views, called aspect graphs of 3D models [18].
Eitz et al. [12] compared human sketches with line drawings of 3D models produced from several different views based on local Gabor filters, while Schneider et al. [30] proposed using Fisher vectors [26] on SIFT features [22] for representing human sketches of shapes.
These descriptors are largely “hand-engineered” and some do not generalize well across different domains.
上面回顾了在三维特征提取表示方面的一系列工作,但都是“hand-designed”,人工设计的特征。与二维图像中的人工设计特征相同,这些人工设计特征的泛化能力不强,用在特定的领域。
Convolutional neural networks
Our work is also related to recent advances in image recognition using CNNs [20]. In particular CNNs trained on the large datasets such as ImageNet have been shown to learn general purpose image descriptors for a number of vision tasks such as object detection, scene recognition, texture recognition and finegrained classification [10, 13, 28, 7].
凡谈及CNN,必谈的话。一是什么我们的工作是基于CNN的,这里要么引用Yann LeCun大神的1989年的CNN论文,要么引用ImageNet 2012年名震江湖的AlexNet大作:《Imagenet classification with deep convolutional neural networks》等等。二是,现在CNN用的地方多的一塌糊涂,有碾压其他传统的方法,在举出一大堆代表性的论文。
Although there is significant work on 3D and 2D shape descriptors, and estimating informative views of the objects(or, aspect graphs), there is relatively little work on learning to combine the view-based descriptors for 3D shape recognition.
In contrast our multi-view CNN architecture learns to recognize 3D shapes from views of the shapes using image-based CNNs but in the context of other views via a view-pooling layer.
As a result, information from multiple views is effectively accumulated into a single, compact shape descriptor.
这段突出作者本文的特殊之处,一是作者研究的这个Multi-view based三维形状描述算子,目前研究较少;二是在将同一件三维形状的不同视角下的图,结合起来提取三维形状描述算子,怎么结合?作者提出了一个叫做“view-pooling layer”的结构,经过实验,发现三维形状数据经过多视角的图结合,经过CNN网络训练后,能够提取到单一、简单的形状描述算子。
Method
Our view-based representations start from multiple views of a 3D shape, generated by a rendering engine. A simple way to use multiple views is to generate a 2D image descriptor per each view, and then use the individual descriptors directly for recognition tasks based on some voting or alignment scheme. For example, a naive approach would be to average the individual descriptors, treating all the views as equally important. Alternatively, if the views are rendered in a reproducible order, one could also concatenate the 2D descriptors of all the views. Unfortunately, aligning a 3D shape to a canonical orientation is hard and sometimes ill-defined. In contrast to the above simple approaches, an aggregated representation combining features from multiple views is more desirable since it yields a single, compact descriptor representing the 3D shape.
从3D立体形状中,由一个渲染引擎渲染得到一系列该3D形状多视角的2D图像。那么该如何使用这些多视角的2D图像呢?一个简单的思路就是,由这些2D图像每张得到一个图像特征描述算子,再用某种投票或者排序机制对这些描述算子排序,以此使用这些独立的描述算子来做图像识别任务。
如,一个简单直接的思路就是取对每张独立的描述算子取平均,等同的看待这些算子。但是,该如何“排列安置”3D形状呢?某些很简单,如上面的椅子,直接按照平时的那样摆放,但是很多这种放置方向是很难定义的。因此,若有一种能够结合多视角的表示方法是非常必要的。
Our approach is to learn to combine information from multiple views using a unified CNN architecture that includes a view-pooling layer (Fig. 1). All the parameters of our CNN architecture are learned discriminatively to produce a single compact descriptor for the 3D shape. Compared to exhaustive pairwise comparisons between singleview representations of 3D shapes, our resulting descriptors can be directly used to compare 3D shapes leading to significantly higher computational efficiency.
我们的方法是通过一个叫做“view-pooling layer”的CNN架构去“自动学习”来结合多视角的特征,产生一个单一的、简洁的3D形状描述子。
Input: Multi-view Representation
3D models in online databases are typically stored as polygon meshes, which are collections of points connected with edges forming faces. To generate rendered views of polygon meshes, we use the Phong reflection model [27]. The mesh polygons are rendered under a perspective projection and the pixel color is determined by interpolating the reflected intensity of the polygon vertices. Shapes are uniformly scaled to fit into the viewing volume.
3D形状数据是以多边形网格的格式存储的。我们使用一种叫做“Phone reflection model”的方法,来由多边形网格产生渲染图。
To create a multi-view shape representation, we need to setup viewpoints (virtual cameras) for rendering each mesh.
We experimented with two camera setups.
For the 1st camera setup, we assume that the input shapes are upright oriented along a consistent axis (e.g., z-axis). Most models in modern online repositories, such as the 3DWarehouse, satisfy this requirement, and some previous recognition meth- ods also follow the same assumption [37]. In this case, we create 12 rendered views by placing 12 virtual cameras around the mesh every 30 degrees (see Fig. 1). The cameras are elevated 30 degrees from the ground plane, pointing towards the centroid of the mesh. The centroid is calculated as the weighted average of the mesh face centers, where the weights are the face areas.
为了产生3D形状的多视角渲染图,我们需要设定一个“视角”(虚拟相机)来产生网格的渲染图。
我们试验了两种视角初始化。
第一种,我们假设输入的3D形状是按照一个恒定的轴(Z-轴)正直的摆放的。这种情况下,我们每个3D形状产生了12张不同视角下的渲染图,也就是没30度,产生一个2D视角渲染图。如图1那样,相机“拍摄”时,是与水平面有30度的水平角(30 degrees from the ground plane)的,且径直指向3D网格数据的“中心”(centroid),这个中心的计算方法是,所有的网格面中心的权重加和,这个权重是各个网格面的面积。
For the 2nd camera setup, we do not make use of the assumption about consistent upright orientation of shapes. In this case, we render from several more viewpoints since we do not know beforehand which ones yield good representative views of the object. The renderings are generated by placing 20 virtual cameras at the 20 vertices of an icosahedron enclosing the shape. All cameras point towards the centroid of the mesh. Then we generate 4 rendered views from each camera, using 0, 90, 180, 270 degrees rotation along the axis passing through the camera and the object centroid, yielding total 80 views.
对于第二种视角初始化,此时就不假设3D形状沿着恒定的Z轴放置了。
在这种情况下,我们就需要从更多的“视角点”来“拍摄”3D形状,因为我们不能够确定哪一个视角点能够产生出好的2D渲染图。
我们通过围绕3D形状生成20面体(icosahedron),将“相机”放在20面体的“vertices”上。这地方很疑惑,20面体,就只有12个“顶点”,但有20个面,这地方难道指的是每个面(等边三角形)的中心么。
之后,每个相机在其“点位上”,有前后左右四个方向,也就是文章中所说的旋转0,90,180,270度方向再“拍摄”,每个“点位上”能够得到4个视角图。因此,最后共有80个视角图。
We note that using different shading coefficients or illumination models did not affect our output descriptors due to the invariance of the learned filters to illumination changes, as also observed in image-based CNNs [20, 10]. Adding more or different viewpoints is trivial, however, we found that the above camera setups were already enough to achieve high performance. Finally, rendering each mesh from all the viewpoints takes no more than ten milliseconds on modern graphics hardware.
注意到,使用不同的遮蔽系数(shading coefficients)或者光照度(illumination)模型并不能影响图像描述子,因为基于图像的CNN网络中,学习到的filters对光照变化具有不变性[20, 10]。
增加更多的视角点的图像是不必要的,我们发现通过上述的不同的视角点获得的图像已经足够满足要求了。最后,在现在图像处理硬件上,完成所有的视角点的每一张网格2D渲染图消耗不超过10万毫秒的时间( 1ms=11000s ),也就是100s。
Recognition with Multi-view Representations
We claim that our multi-view representation contains rich information about 3D shapes and can be applied to various types of tasks. In the first setting, we make use of existing 2D image features directly and produce a descriptor for each view. This is the most straightforward approach to utilize the multi-view representation. However, it results in multiple 2D image descriptors per 3D shape, one per view, which need to be integrated somehow for recognition tasks.
每一张视角图可以提取以此图像描述子(特征),但是问题来了,每一个3D形状产生12张或者80张图,怎么把这么多张图像的特征“整合”,来描述3D形状特征呢,这样下一步才能进行各种识别任务。
Image descriptors
We consider two types of image descriptors for each 2D view: a state-of-the-art “hand-crafted” image descriptor based on Fisher vectors [29] with multi-scale SIFT, as well as CNN activation features [10].
我们考虑两类2D图像描述算子,一种最新的基于Fisher Vector与multi-scale SIFT的人工设计描述算子,另一种则是CNN特征。
The Fisher vector image descriptor is implemented using VLFeat [36]. For each image multi-scale SIFT descriptors are extracted densely. These are then projected to 80 dimensions with PCA, followed by Fisher vector pooling with a Gaussian mixture model with 64 components, square-root and l2 normalization.
Fisher vector图像描述算子是用VLFeat实现的。
对于每一张图像,先用multi-scale SIFT提取特征。再用PCA投影成80维,之后就是Gaussian mixture model with 64 components,square-root与 l2 normalization的的Fisher vector。
For our CNN features we use the VGG-M network from [3] which consists of mainly five convolutional layers conv1,...,5 followed by three fully connected layers fc6,...,8 and a softmax classification layer. The penultimate layer fc7 (after ReLU non-linearity, 4096-dimensional) is used as image descriptor. The network is pre-trained on ImageNet images from 1k categories, and then fine-tuned on all 2D views of the 3D shapes in training set. As we show in our experiments, fine-tuning improves performance significantly. Both Fisher vectors and CNN features yield very good performance in classification and retrieval compared with popular 3D shape descriptors (e.g., SPH [16], LFD [5]) as well as 3D ShapeNets [37].
这一段描述了所用CNN的网络结构及其训练方法。这个CNN网络结构主要先是有5层卷积层( Conv1,2,3,4,5 ),随后就是3个全连接层( fc6,7,8 ),最后是Softmax分类层。
倒数第二(penultimate)层, fc7 层(随后由一个ReLU激活层,4096维),被用作图像描述算子。
整个网络先在ImageNet图像集上进行预训练,之后用之前采集到的多视角图像进行微调。通过我们的实验,微调能够显著的改善性能。Fisher vectors与CNN features都能在分类与检索任务上取得不俗的表现,相比较于先在流行的3D形状描述算子(如:SPH、LFD)以及3D ShapeNets。
Classification.
We train one-vs-rest linear SVMs (each view is treated as a separate training sample) to classify shapes using their image features. At test time, we simply sum up the SVM decision values over all 12 views and return the class with the highest sum. Alternative approaches, e.g., averaging image descriptors, lead to worse accuracy.
我们使用线性核SVM,一对多的方式去训练图像特征,来分类3D形状。在测试阶段,我们看一个3D形状的12个多视角图像的测试结果,返回最高值的类别。代替的方案是,求12个多视角图像的描述子的平均值,但效果不好。
Retrieval
A distance or similarity measure is required for retrieval tasks. For shape x with nx image descriptors and shape y with ny image descriptors, the distance between them is defined in Eq. 1. Note that the distance between two 2D images is defined as the l2 distance between their feature vectors, i.e. ||xi−yj||2 .
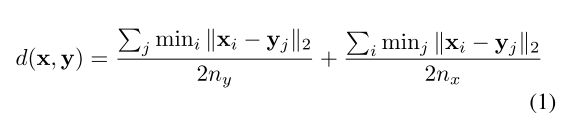
Retrieval任务需要定义一种距离、相似度的“度量”方式。对于3D形状 x ,其图像描述子为: nx ,对于3D形状 y ,其图像描述子为: ny ,这两者之间的“距离”定义如等式1。注意,两者之间的距离度量是用它们的特征向量的 l2 距离定义来计算的( ||xi−yj||2 )。
To interpret this definition, we can first define the distance between a 2D image xi and a 3D shape y as d(xi,y)=minj||xi−yj||2 . Then given all nx distances between x’s 2D projections and y , the distance between these two shapes is computed by simple averaging. In Eq. 1, this idea is applied in both directions to ensure symmetry.
We investigated alternative distance measures, such as minimun distance among all nx⋅ny image pairs and the distance between average image descriptors, but they all led to inferior performance.
解释一下上面的公式,我们可以首先定义一下2D图像( xi )与3D形状( y )的距离为:
那么,给出所有的( nx 个) x 的2D投影与 y 之间所有的距离,这两种形状之间的距离就是对 nx 求平均。
我们还试了其他的距离定义,但效果都不行。
Multi-view CNN: Learning to Aggregate Views
Although having multiple separate descriptors for each 3D shape can be successful for classification and retrieval compared to existing 3D descriptors, it can be inconvenient and inefficient in many cases. For example, in Eq. 1, we need to compute all nx×ny pairwise distances between images in order to compute distance between two 3D shapes. Simply averaging or concatenating the image descriptors leads to inferior performance. In this section, we focus on the problem of learning to aggregate multiple views in order to synthesize the information from all views into a single, compact 3D shape descriptor.
虽然对于3D形状,上面的多重的描述子相比较于现存的3D形状特征描述子,效果要好,但是在许多情况下,这种算法是低效的。因为如等式1中,我们要衡量两个3D形状之间的距离,需要计算 nx×ny 个距离(在3D形状对应的视角2D图像下计算),这本身需要大量的计算。
如前面所说,简单的求一个3D形状的多视角图像的特征描述子的平均值,或者简单的将这些特征描述子做“连接”(这地方可以想象成将特征简单的“串联”),会导致不好的效果。
所以,这一部分,我们集中于融合多视角2D图像产生的特征,以便综合这些信息,形成一个简单、高效的3D形状描述子。
We design the multi-view CNN (MVCNN) on top of image-based CNNs (Fig. 1). Each image in a 3D shape’s multi-view representation is passed through the first part of the network (CNN1) separately, aggregated at a view-pooling layer, and then sent through the remaining part of the network (CNN2). All branches in the first part of the network share the same parameters in CNN1.
We use element-wise maximum operation across the views in the view-pooling layer. An alternative is element-wise mean operation, but it is not as effective in our experiments. The view-pooling layer can be placed anywhere in the network. We show in our experiments that it should be placed close to the last convolutional layer (conv5) for optimal classification and retrieval performance. View-pooling layers are closely related to max-pooling layers and maxout layers [14], with the only difference being the dimension that their pooling operations are carried out on. The MVCNN is a directed acyclic graphs and can be trained or fine-tuned using stochastic gradient descent with back-propagation.

因此,我们设计了Multi-view CNN(MVCNN),放在基础的2D图像CNN之中。
如图所示,同一个3D形状的 每一张视角图像 各自独立地经过第一段的CNN1卷积网络,在一个叫做View-pooling层进行“聚合”。之后,再送入剩下的CNN2卷积网络。
整张网络第一部分的所有分支,共享相同的 CNN1里的参数。
在View-pooling层中,我们逐元素取最大值操作,另一种是求平均值操作,但在我们的实验中,这并不有效。
这个View-pooling层,可以放在网络中的任何位置。经过我们的实验,这一层最好放在最后的卷积层(Conv5),以最优化的执行分类与检索的任务。
View-pooling优点类似于max-pooling layer与maxout layer,不同点在于进行max操作时的维度不同,这里,所谓的“维度不同”,我看了好一会儿,我想应该是指,这里的max操作是“纵向的”,即在12个视角图像中,同一个位置的地方,进行max操作。而一般意义上所说的max-pooling,通常是指在一个 2×2 的领域像素单元内,取max像素值保留的操作,举个例子,下图是我自己画的,照我自己的理解(如果理解的不对,欢迎指正!):
MVCNN是一种有向无环图结构,可以反向传播中用随机梯度下降法训练或者微调。
Using fc7 (after ReLU non-linearity) in an MVCNN as an aggregated shape descriptor, we achieve higher performance than using separate image descriptors from an image-based CNN directly, especially in retrieval (62.8% → 70.1%). Perhaps more importantly, the aggregated descriptor is readily available for a variety of tasks, e.g., shape classification and retrieval, and offers significant speed-ups against multiple image descriptors.
An MVCNN can also be used as a general framework to integrate perturbed image samples (also known as data jittering). We illustrate this capability of MVCNNs in the context of sketch recognition in Sect. 4.2.
在MVCNN中,用 fc7 层作为一种聚合的3D形状特征描述符,我们得到了比用基础的CNN卷积网络从单独的图像中提取到的图像描述符,有更好表现的描述符,特别是在检索实验中,从62.8%提高到了70.1%.这种描述符可以直接用来进行其他3D形状的任务了,如分类、检索。
Low-rank Mahalanobis metric
Our MVCNN is fine-tuned for classification, and thus retrieval performance is not directly optimized. Although we could train it with a different objective function suitable for retrieval, we found that a simpler approach can readily yield a significant retrieval performance boost (see row 12 in Tab. 1). We learn a Mahalanobis metric W that directly projects MVCNN descriptors ϕ∈Rd to Wϕ∈Rp , such that the ℓ2 distances in the projected space are small between shapes of the same category, and large otherwise. We use the large-margin metric learning algorithm and implementation from [32], with p<d to make the final descriptor compact ( p=128 in our experiments). The fact that we can readily use metric learning over the output shape descriptor demonstrates another advantage of using MVCNNs.
MVCNN微调后是直接适用于分类,但但是并不是直接适用于检索。尽管我们可以训练一个适合于图像检索的目标函数,但是我们发现了一种简单的方法,可以容易的提升检索的性能。
我们学习一个马氏距离(Mahalanobis metric)W,直接将MVCNN的特征描述符 ϕ∈Rd 投影到马氏距离W ϕ∈Rp ,这样的话,相同类别3D形状之间的 ℓ2 距离在投影后的空间中就更小,而不同的类别之间的 ℓ2 在投影后会更大。
我们使用文献32中提出与实现的large-margin metric learning algorithm。
Experiment
3D Shape Classification and Retrieval
We evaluate our shape descriptors on the Princeton ModelNet dataset [1]. ModelNet currently contains 127,915 3D CAD models from 662 categories1 . A 40-class well-annotated subset containing 12,311 shapes from 40 common categories, ModelNet40, is provided on the ModelNet website. For our experiments, we use the same training and test split of ModelNet40 as in [37]2 .
Princeton大学的Wu建立的ModelNet数据集,ModelNet数据集现在包含127,915个3D CAD模型,662个类别。40个标注好的子类,共12,311个形状。
Our shape descriptors are compared against the 3D ShapeNets by Wu et al. [37], the Spherical Harmonics descriptor (SPH) by Kazhdan et al. [16], the LightField descriptor (LFD) by Chen et al. [5], and Fisher vectors extracted on the same rendered views of the shapes used as input to our networks.
对比对象:
(1)一个是文献[37]中,Princeton大学的Wu提出的3D ShapeNets;
(2)一个是文献[16]中,Kazhdan提出的Spherical Harmonics descriptor算子(SPH);
(3)文献[5]中,Chen提出的LFD算子(LightField);
(4)以及用相同的多视角图像提取的Fisher vectors描述符.
Results on shape classification and retrieval are summarized in Tab. 1. Precision-recall curves are provided in Fig. 2.
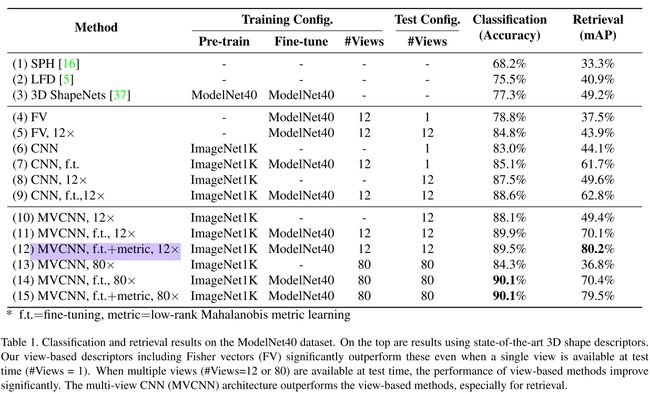
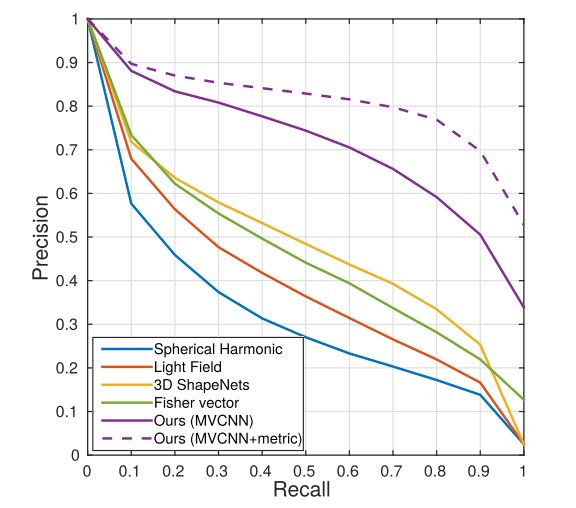
Remarkably the Fisher vector baseline with just a single view achieves a classification accuracy of 78.8% outperforming the state-of-the-art learned 3D descriptors (77.3% [37]). When all 12 views of the shape are available at test time (based on our first camera setup), we can also average the predictions over these views. Averaging increases the performance of Fisher vectors to 84.8%. The performance of Fisher vectors further supports our claim that 3D objects can be effectively represented using viewbased 2D representations. The trends in performance for shape retrieval are similar.
……
……
以上就是一些对照实验图标的结果说明。
就不一一详述了,对照了看,解释的很清楚。
Conclusion
实验的Retriveal部分我就不详述了,下面我就直接进入Conclusion部分。
Conclusion部分,我最关注的是作者的展望:
There are a number of directions to explore in future work. One is to experiment with different combinations of 2D views. Which views are most informative? How many views are necessary for a given level of accuracy? Can informative views be selected on the fly?
Another obvious question is whether our view aggregating techniques can be used for building compact and discriminative descriptors for real-world 3D objects from multiple views, or automatically from video, rather than merely for 3D polygon mesh models. Such investigations could be immediately applicable to widely studied problems such as object recognition and face recognition.
作者提出了几点疑问:
在多视角的2D图像表示3D特征时,哪一张视角图像是最重要的,或者说哪一张图像包含了主要的特征信息?多少涨视角图像可以满足给定的精度要求?可以在程序运行中提取选择有价值的视角图像吗?
另一个重要的问题就是,本文的实验都是在“虚拟的”3D形状上的,那么,这篇文章提出的MVCNN能够对于真实世界的3D物体(或者视频、而不仅仅是3D多边形网格模型),也能够建立简洁的特征描述子吗?
这类问题研究清楚了,MVCNN才能运用于实际问题,如物体识别与人脸识别。