MapReduce
hostname 查看系统主机名称
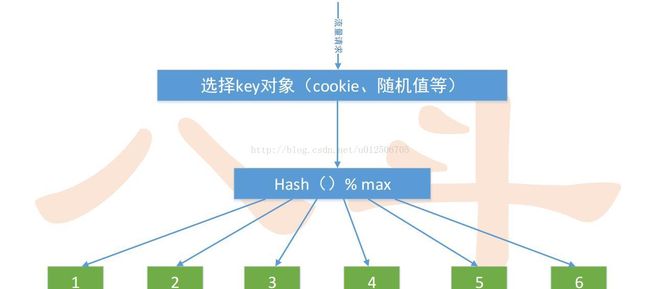
一、划分方法
1、传统Hash,最基本的划分方法
– 如何将大数据、流量均分到N台服务器
– 找到合理的key,hash(key)尽量分布均匀
– hash(key)mod N == 0 分到 第0台,
– hash(key)mod N == i 分到 第i台
– hash(key)mod N == N-1 分到 第N-1台
• 随机划分
• 一致性Hash:支持动态增长,更高级的划分方法
模拟hash算法
>>> import random
>>> print random.random()
0.223654873953
>>> print random.random()
0.800151701113
>>> print int(random.random()*100)
84
>>>
>>> print int(random.random()*100)
88
>>> print int(random.random()*100)%6
5
>>> print int(random.random()*100)%6
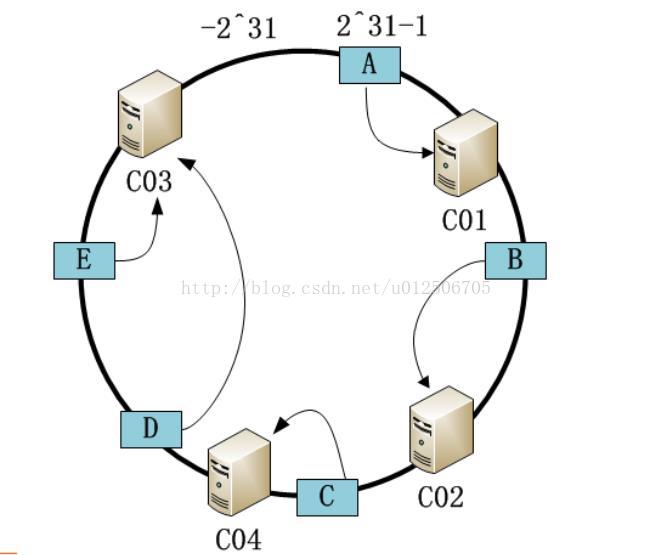
32、一致性Hash算法
• 一致性哈希算法设计目标是为了解决因特网中的热点(Hotspot)问题
几台机器成环状,哪个坏了移除哪个,数据由下一个节点处理,恢复后再由原节点处理
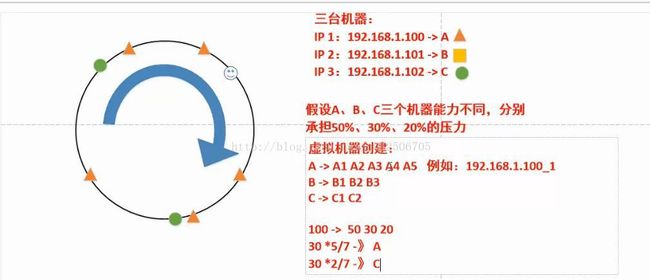
假设按照顺时针来,如果100个流量,基本会按照50 30 20划分,如果B挂了,剩下的30会按照50 20的比例划分,B恢复,流量归B
数据划分总结:
• 大数据量——按数据划分
– 早期搜索引擎中的网页存储系统,单机存储数千万网页,几十亿的网页需要通过几百台
单机服务器存储,url为key
– 分布式文件系统,按block(64-256M)来划分组织文件
• 大流量——按流量划分
– 覆盖的大流量互联网服务
– 南方流量分到电信机房,北方流量分到联通机房
– 搜索引擎将query作为key来分流
• 大计算——按输入数据,划分计算任务
– Map Reduce 按输入数据来划分
二、单机系统变为分布式集群系统
数据一致性
1)弱一致性
只要有个节点满足就提供服务
2)强一致性
必须每个节点都满足才提供服务
– 任何消息存在丢失的可能
– 任何单机存在故障的风险
四、MapReduce是一个用于处理海量数据的分布式计算框架
存储在hdfs上
HDFS
– 系统可靠性
– 可扩展性
– 并发处理
• 这个框架解决了
• 数据分布式存储
• 作业调度
任务排队,先入先出队列
• 容错
屏蔽些细节,不影响任务
• 机器间通信等复杂问题
1)分而治之
单点策略,一个人搞定
分治策略,多个人处理,后汇总
用于切割数据进行计算合并
总结
• 分治思想
– 分解
– 求解
– 合并
• MapReduce映射
– 分:map
• 把复杂的问题分解为若干“简单的
任务”
– 合:reduce
2)执行流程(重点)
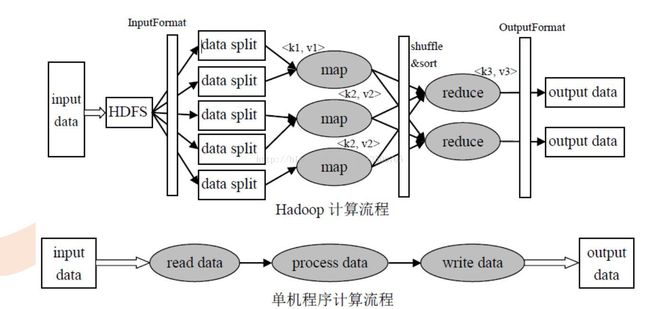
InputFormat处理器
功能为数据切割
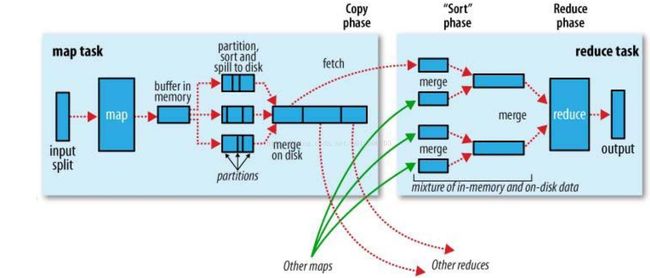
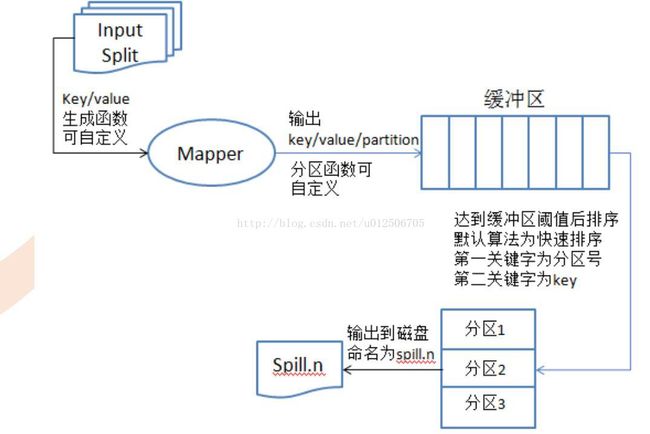
一个map对应一个split分片,map是个进程,需要开辟内存空间,默认100M,写到80%时,锁住80%数据,分割排序然后转储到磁盘上,归并排序,把指针指向各个文件头,比较,合并,每个子文件都被指向同一个,排好序的,才合并
3)编程模型
借鉴函数式的编程方式
• 用户只需要实现两个函数接口:
• Map(in_key, in_value)
-> (out_key, intermediate_value) list
• Reduce (out_key, intermediate_value list)
->out_value list
4)编程实例
WordCount实现过程
• 源数据
• Document 1
• the weather is good
• Document 2
• today is good
• Document 3
• good weather is good
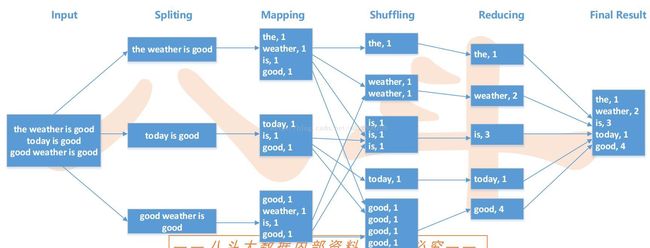
• Map 输出
• Worker 1
• (the 1), (weather 1), (is 1), (good 1)
• Worker 2
• (today 1), (is 1), (good 1)
• Worker 3
• (good 1), (weather 1), (is 1), (good 1)
• Reduce 输入
• Worker 1
• (the 1)
• Worker 2
• (is 1), (is 1), (is 1)
• Worker 3
• (weather 1), (weather 1)
• Worker 4
• (today 1)
• Worker 5
• (good 1), (good 1), (good 1), (good 1)
• Reduce 输出
• Worker 1
• (the 1)
• Worker 2
• (is 3)
• Worker 3
• (weather 2)
• Worker 4
• (today 1)
• Worker 5
• (good 4)
5)实现架构
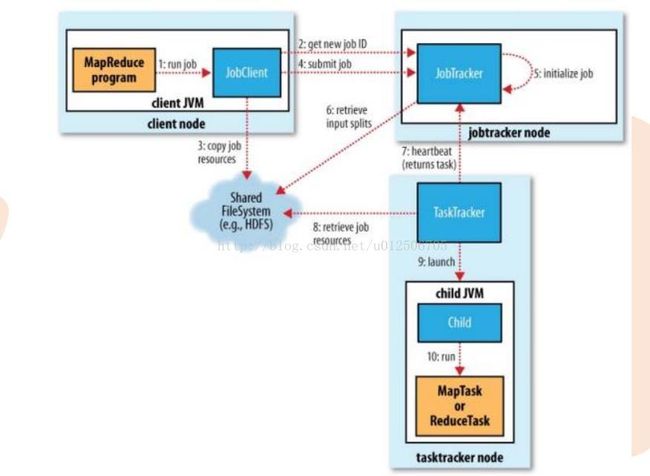
两个重要的进程
– JobTracker
• 主线程,负责接收客户作业提交,调度任务到作节点上运行,并提供诸如监控工作节点状态及任务进度等管理功能,一个MapReduce集群有一个jobtracker,一般运行在可靠的硬件上。
• tasktracker是通过周期性的心跳来通知jobtracker其当前的健康状态,每一次心跳包含了可用的map和reduce任务数目、占用的数目以及运行中的任务详细信息。 Jobtracker利用一个线程池来同时处理心跳和客户请求。
– TaskTracker
• 由jobtracker指派任务,实例化用户程序,在本地执行任务并周期性地向jobtracker汇报状态。在每一个工作节点上永远只会有一个tasktracker
两个重要的进程
– JobTracker
• 主线程,负责接收客户作业提交,调度任务到作节点上运行,并提供诸如监控工作节点状态及任务进度等
管理功能,一个MapReduce集群有一个jobtracker,一般运行在可靠的硬件上。
• tasktracker是通过周期性的心跳来通知jobtracker其当前的健康状态,每一次心跳包含了可用的map和
reduce任务数目、占用的数目以及运行中的任务详细信息。 Jobtracker利用一个线程池来同时处理心跳和
客户请求。
– TaskTracker
• 由jobtracker指派任务,实例化用户程序,在本地执行任务并周期性地向jobtracker汇报状态。在每一个工
作节点上永远只会有一个tasktracker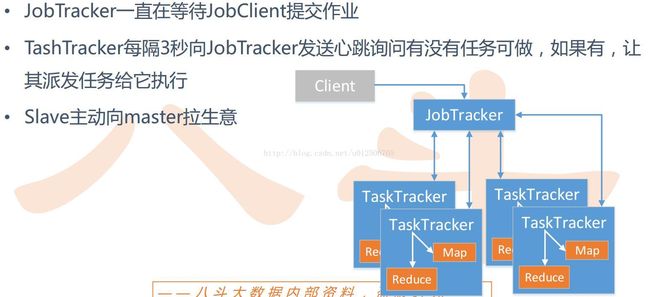
Wordcount实例
//strip去除隐含字符
[root@master mapreduce_wordcount_python]# cat map.py
import sys
for line in sys.stdin:
print line.strip()
[root@master mapreduce_wordcount_python]# cat 1.txt
111
222
222
333
[root@master mapreduce_wordcount_python]# cat 1.txt | python map.py
111
222
222
333
//第一段话
[root@master mapreduce_wordcount_python]# head -1 The_Man_of_Property.txt
Preface
//按照空格分割
[root@master mapreduce_wordcount_python]# cat map.py
import sys
for line in sys.stdin:
ss = line.strip().split(' ')
for word in ss:
print word.strip()
[root@master mapreduce_wordcount_python]# head -2 The_Man_of_Property.txt | python map.py
Preface
“The
Forsyte
//以制表符分割
[root@master mapreduce_wordcount_python]# cat map.py
import sys
for line in sys.stdin:
ss = line.strip().split(' ')
for word in ss:
print '\t'.join([word.strip(),'1'])
[root@master mapreduce_wordcount_python]# head -2 The_Man_of_Property.txt | python map.py
Preface 1
“The 1
Forsyte 1
Saga” 1
was 1
//输出
[root@master mapreduce_wordcount_python]# head -2 The_Man_of_Property.txt | python map.py | sort -k1 | python red.py |head
a 3
adopt 1
after 1
against 1
all, 1
all 2
and, 1
and 10
And 1
as 4
//输出
[root@master mapreduce_wordcount_python]# cat The_Man_of_Property.txt | python map.py | sort -k1 | python red.py > result.local
//统计行数
[root@master mapreduce_wordcount_python]# wc -l result.local
16984 result.local
//以第二栏数字排序
[root@master mapreduce_wordcount_python]# cat result.local | sort -k2 -n |head
., 1
.! 1
.?” 1
.” 1
‘. 1
’— 1
“. 1
10 1
10.45. 1
1. 1
//以第二栏数字反向排序
[root@master mapreduce_wordcount_python]# cat result.local | sort -k2 -rn |head
the 5144
of 3407
to 2782
and 2573
a 2543
he 2139
his 1912
was 1702
in 1694
had 1526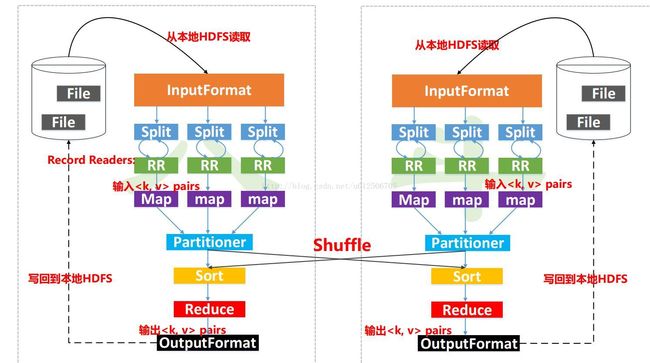
1、File:
文件要存储在HDFS中,每个文件切分成多个一定大小(默认64M)的Block(默认3个备份)存储在多个节点(DataNode)上
文件数据内容:
We are studying at badou.\n
We are studying at badou.\n
2、InputFormat:
MR框架基础类之一
• 数据分割(Data Splits)
• 记录读取器(Record Reader)
例子:
数据格定义,如果以“\n”分割每条记录,以格区分一个目标单词“we are studying at badou.” 为一条记录“are”“at” 等为一个目标单词
3、Split:
实际上每个split包含后一个Block中开头部分的数据(解决记录跨Block问题)
例子:
比如记录 “we are studying at badou.\n”跨越存储在两个Block中,那么这条记录属于前一个Block对应的split
4、RecordReader:
每读取一条记录,调用一次map函数
例子:
比如记录 “we are studying at badou.” 作为参数v,调用map(v)然后继续这个过程,读取下一条记录直到split尾部。
5、Map:
比如记录 “we are studying at badou”
调用执行一次map(“we are studying at badou”)
在内存中增加数据:
{“we”: 1}
{“are”: 1}
{“studying”: 1}
{“at”: 1}
{“badou”: 1}
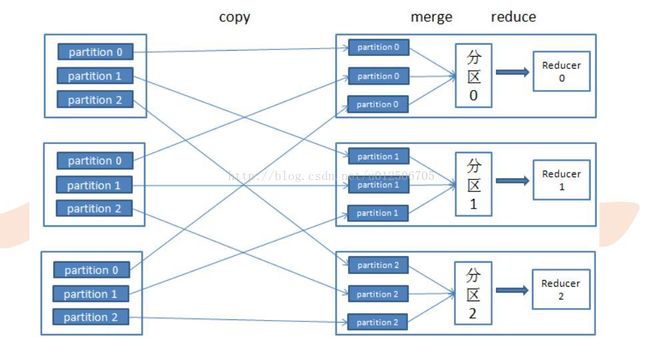
6、Partitioner:
决定数据由哪个Reducer处理,从而分区比如采用Hash法,有n个Reducer,那么数据{“are”: 1}的key“are”对n进行取模,返回m,而生成{partition, key, value}
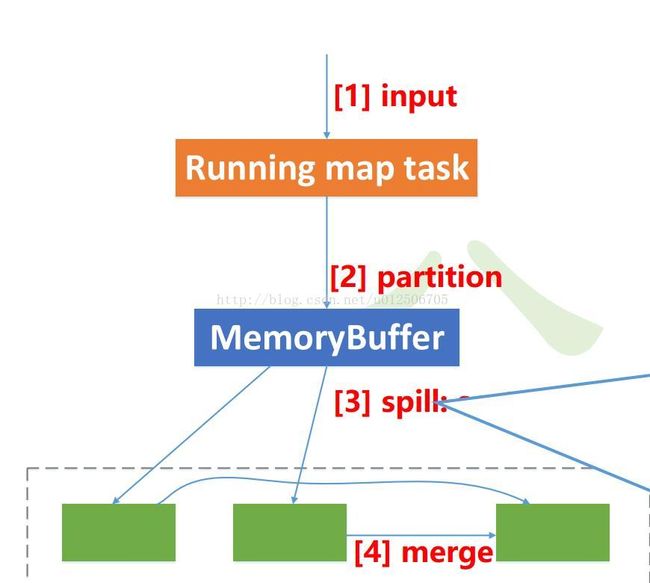
7、MemoryBuffer:
内存缓冲区,每个map的结果和partition处理的key value结果都保存在缓存中
缓冲区大小:默认100M
溢写阈值:100M * 0.8 = 80M
缓冲区中的数据:partition key value 三元组数据
{“1” , “are” : 1}
{“2” , “at” : 1}
{“1” , “we” : 1}
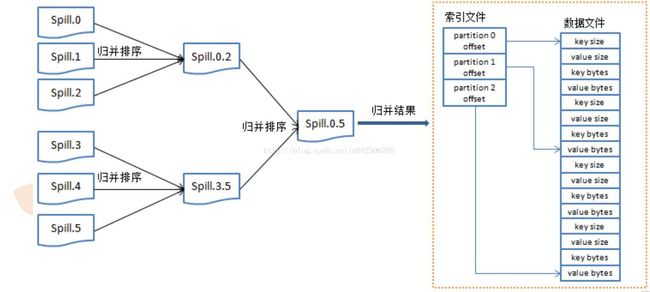
8、Spill:
内存缓冲区达到阈值时,溢写spill线程锁住这80M的缓冲区,开始将数据写出到本地磁盘中,然后释放内存。
每次溢写都生成一个数据文件。溢出的数据到磁盘前会对数据进行key排序sort,以及合并combiner发送相同Reduce的key数量,会拼接到一起,减少partition的索引数量。
9、Sort:
缓冲区数据按照key进行排序
{“1”, “are”, 1}
{“2” , “at” , 1}
……
{“1”, “are”, 1}
{“1”, “we” , 1}
{“1”, “are”, 1}
{“1” , “are” , 1}
{“1”, “we”, 1}
……
{“2”, “at”, 1}
10、Combiner:
数据合并,相当的key的数据,value值合并,介绍输
出传输量
Combiner函数事实上是reducer函数,满足
combiner处理不影响{sum,max等}最终reduce的
结果时,可以极大提升性能
{“1”, “are”, 1}
{“1”, “are”, 1}
{“1”, “we”, 1}
{“1”, “are”, 2}
{“1”, “we”, 1}
11、Reduce:
多个reduce任务输出的数据都属于不同的partition,因此结果数据的key不会重复。合并reduce的输出文件即可得到最终的结果
MapReduce多进程并发,延迟性高,适合离线性,低延迟的
ulimit查看系统文件
• map个数为split的份数
• 压缩文件不可切分
• 非压缩文件和sequence文件可以切分
• dfs.block.size决定block大小,默认64M
hdfs-site.xml中配置
控制map个数,通过压缩文件或修改block大小
三、Streaming 简介
• MapReduce和HDFS采用Java实现,默认提供Java编程接口
• Streaming框架允许任何程序语言实现的程序在HadoopMapReduce中使用
• Streaming方便已有程序向Hadoop平台移植
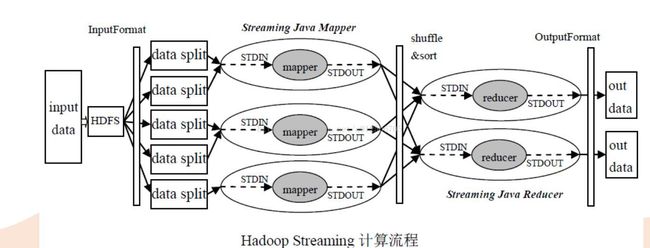
三、Streaming 简介
• MapReduce和HDFS采用Java实现,默认提供Java编程接口
• Streaming框架允许任何程序语言实现的程序在HadoopMapReduce中使用
• Streaming方便已有程序向Hadoop平台移植
优点
• 开发效率高
– 方便移植Hadoop平台,只需按照一定的格式从标准输入读取数据、向标准输出写数据就可以
– 原有的单机程序稍加改动就可以在Hadoop平台进行分布式处理
– 容易单机调试
• 程序运行效率高
– 对于CPU密集的计算,有些语言如C/C++编写的程序可能比用Java编写的程序效率更高一些
• 便于平台进行资源控制
– Streaming框架中通过limit等方式可以灵活地限制应用程序使用的内存等资源
cat input | mapper | sort | reducer > output
局限
• Streaming默认只能处理文本数据,如果要对二进制数据进行处理,比较好的方法是将二进
制的key和value进行base64的编码转化成文本即可
• 两次数据拷贝和解析(分割),带来一定的开销
- jobconf
mapred.job.name 作业名
mapred.job.priority 作业优先级
mapred.job.map.capacity 最多同时运行map任务数
mapred.job.reduce.capacity 最多同时运行reduce任务数
mapred.task.timeout 任务没有响应(输入输出)的最大时间
mapred.compress.map.output map的输出是否压缩
mapred.map.output.compression.codec map的输出压缩方式
mapred.output.compress reduce的输出是否压缩
mapred.output.compression.codec reduce的输出压缩方式
stream.map.output.field.separator map输出分隔符