Deep learning系列(十二)caffe结构解析
1. 引言
在ubuntu上安装完caffe后,按照官网的教程学习caffe。看得第一个例子是Lenet(LeCun et al., 1998),分别用命令行和python对其进行了训练。结合这两种训练方式及官网的教程,初步了解了caffe的结构。
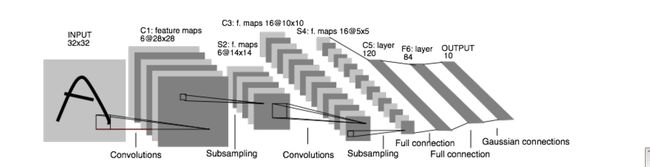
首先看命令行的训练过程,包括四步:
- 将输入(Mnist数据库)转换成caffe可以接收的格式,比如LMDB或者leveldb;
- 定义Net,主要是定义所有的Layers,也定义了与Layer相连的Blobs;
- 定义Solver,使用的优化方法是(SGD+momentum),给定了优化过程中的各种参数;
- 用caffe训练模型,这儿仅需要一条指令:caffe train –solver,具体为:./build/tools/caffe train –solver=examples/mnist/lenet_solver.prototxt;
可以看出,理解caffe的关键是中间两步,其中包括caffe重要的四个模块Net,Layers,Blobs和Solver。下面详细介绍这四个模块。
2. Nets
caffe的Net包括训练Net和测试Net,其保存在.prototxt文件中,训练Net的内容包括:
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
transform_param {
scale: 0.00392156862745
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}将net的结果用python输出:
[('data', (64, 1, 28, 28)),
('label', (64,)),
('conv1', (64, 20, 24, 24)),
('pool1', (64, 20, 12, 12)),
('conv2', (64, 50, 8, 8)),
('pool2', (64, 50, 4, 4)),
('ip1', (64, 500)),
('ip2', (64, 10)),
('loss', ())]将上面Net可视化出来,结果由下图表示:
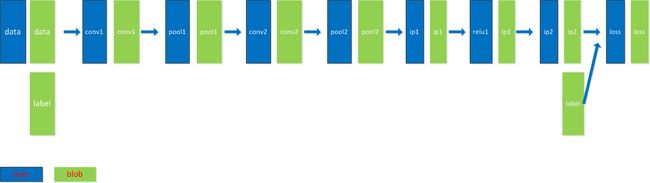
可见,Net是由layers组成的有向无环图(DAG),data(特征和梯度)以blobs的形式从net中流过。其中,在Forward阶段,特征blobs从左流向右,直到计算出损失;在Backward阶段,梯度blobs从右流向左,可以得到目标函数对每个参数的梯度值。同时,在图中和上面的.prototxt文件可以看出,data和layer的名字通常是一样的。
3. Layers
以第一个卷积层为例,了解Layers的结构:
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}可以看出,Layer包括四部分:
- 名字,这一层的名字是conv1;
- 类型,这一层的类型是Convolution;
- 连接结构,包括输入和输出的blobs,对这层来说,输入blob是data,输出blob是conv1;
- 参数,包括输出特征的数量,卷积核的大小及特征类型等。
每个Layer有三个重要的方法:
- Setup,参数初始化;
- Forward,前向传播;
- Backward,反向传播。
4. Blobs
在caffe中,有三种数据用到blob结构:
- 特征(data);
- 梯度(diff);
- 参数(parameter),包括权重项和偏置项。
blobs通常是4维的数组,用来保存和传输信息,其中data和parameter的示例如下图所示:

对于python来说,blob是用numpy的array来存储的:
print type(solver.net.blobs['data'].data)
'numpy.ndarray'> 因而,我们可以方便的用numpy的语法对这些blob数据进行操作。
5. Solver
上面几部分属于模型的建立部分,Solver是模型的优化部分,通过最小化损失函数得到优化的网络参数,Solver保存在.prototxt文件中:
# The train/test net protocol buffer definition
train_net: "/home/dumengnan/caffe-master/examples/mnist/lenet_auto_train.prototxt"
test_net: "/home/dumengnan/caffe-master/examples/mnist/lenet_auto_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "/home/dumengnan/caffe-master/examples/mnist/lenet"上面使用的优化方法是随机梯度下降(SGD)+动量(momentum)的方法,并定义了其主要参数。