用户空间具体是如何处理dpif_upcall ?(3)执行flow_miss_op->dpif_op,与内核沟通
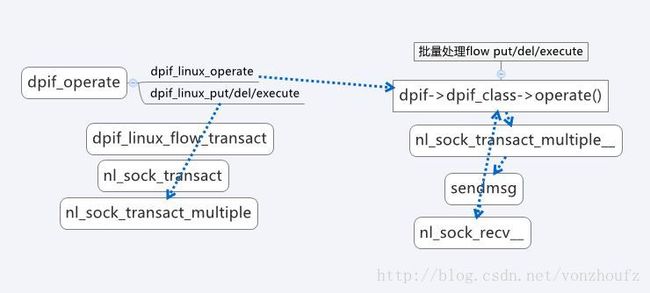
阶段三:调用datapath interface具体实现类(这里是dpif_linux_class)的operate方法进行批量处理,后面如果有剩余项的话再分别调用/put/del/execute。将对应的参数通过nla发送到内核(内核来真正的执行操作)然后接收回应来更新统计信息。流程图如下:
-------------lib/dpif.c
{
size_t i;
if (dpif->dpif_class->operate) {
dpif->dpif_class->operate(dpif, ops, n_ops);
//这里呼叫具体datapa-interface-class的operate函数;这里应该是看dpif_linux_class->dpif_linux_operate;
for (i = 0; i < n_ops; i++) {
struct dpif_op *op = ops[i];
switch (op->type) {
case DPIF_OP_FLOW_PUT:
log_flow_put_message(dpif, &op->u.flow_put, op->error);
break;
case DPIF_OP_FLOW_DEL:
log_flow_del_message(dpif, &op->u.flow_del, op->error);
break;
case DPIF_OP_EXECUTE:
log_execute_message(dpif, &op->u.execute, op->error);
break;
}
}
return;
}
//接下来完成上面operate没有处理完的flow_miss_op,思路一样;
for (i = 0; i < n_ops; i++) {
struct dpif_op *op = ops[i];
switch (op->type) {
case DPIF_OP_FLOW_PUT:
op->error = dpif_flow_put__(dpif, &op->u.flow_put);
break;
case DPIF_OP_FLOW_DEL:
op->error = dpif_flow_del__(dpif, &op->u.flow_del);
break;
case DPIF_OP_EXECUTE:
op->error = dpif_execute__(dpif, &op->u.execute);
break;
default:
NOT_REACHED();
}
}
}
这里牵扯到的数据结构有:
struct
flow_miss_op {
struct dpif_op dpif_op;
struct subfacet *subfacet; /* Subfacet */
void *garbage; /* Pointer to pass to free(), NULL if none. */
uint64_t stub[1024 / 8]; /* Temporary buffer. */
};
struct dpif_op dpif_op;
struct subfacet *subfacet; /* Subfacet */
void *garbage; /* Pointer to pass to free(), NULL if none. */
uint64_t stub[1024 / 8]; /* Temporary buffer. */
};
struct
dpif_op {
enum dpif_op_type type;
int error;
union {
struct dpif_flow_put flow_put;
struct dpif_flow_del flow_del;
struct dpif_execute execute;
} u;
};
enum dpif_op_type type;
int error;
union {
struct dpif_flow_put flow_put;
struct dpif_flow_del flow_del;
struct dpif_execute execute;
} u;
};
enum
dpif_op_type {
DPIF_OP_FLOW_PUT = 1,
DPIF_OP_FLOW_DEL,
DPIF_OP_EXECUTE,
};
DPIF_OP_FLOW_PUT = 1,
DPIF_OP_FLOW_DEL,
DPIF_OP_EXECUTE,
};
struct
dpif_execute {
const struct nlattr *key; /* Partial flow key (only for metadata). */
size_t key_len; /* Length of 'key' in bytes. */
const struct nlattr *actions; /* Actions to execute on packet. */
size_t actions_len; /* Length of 'actions' in bytes. */
const struct ofpbuf *packet; /* Packet to execute. */
};
const struct nlattr *key; /* Partial flow key (only for metadata). */
size_t key_len; /* Length of 'key' in bytes. */
const struct nlattr *actions; /* Actions to execute on packet. */
size_t actions_len; /* Length of 'actions' in bytes. */
const struct ofpbuf *packet; /* Packet to execute. */
};
struct
dpif_flow_put {
/* Input. */
enum dpif_flow_put_flags flags; /* DPIF_FP_*. */
const struct nlattr *key; /* Flow to put. */
size_t key_len; /* Length of 'key' in bytes. */
const struct nlattr *actions; /* Actions to perform on flow. */
size_t actions_len; /* Length of 'actions' in bytes. */
/* Output. */
struct dpif_flow_stats *stats; /* Optional flow statistics. */
};
/* Input. */
enum dpif_flow_put_flags flags; /* DPIF_FP_*. */
const struct nlattr *key; /* Flow to put. */
size_t key_len; /* Length of 'key' in bytes. */
const struct nlattr *actions; /* Actions to perform on flow. */
size_t actions_len; /* Length of 'actions' in bytes. */
/* Output. */
struct dpif_flow_stats *stats; /* Optional flow statistics. */
};
enum dpif_flow_put_flags {
DPIF_FP_CREATE = 1 << 0, /* Allow creating a new flow. */
DPIF_FP_MODIFY = 1 << 1, /* Allow modifying an existing flow. */
DPIF_FP_ZERO_STATS = 1 << 2 /* Zero the stats of an existing flow. */
};
DPIF_FP_CREATE = 1 << 0, /* Allow creating a new flow. */
DPIF_FP_MODIFY = 1 << 1, /* Allow modifying an existing flow. */
DPIF_FP_ZERO_STATS = 1 << 2 /* Zero the stats of an existing flow. */
};
------------lib/dpif-linux.c
static void
dpif_linux_operate(struct dpif *dpif, struct dpif_op **ops, size_t n_ops)
{
while (n_ops > 0) {
size_t chunk = MIN(n_ops, MAX_OPS);
dpif_linux_operate__(dpif, ops, chunk);
ops += chunk; //防止n_ops太大,要分批量处理(MAX_OPS=50);
n_ops -= chunk;
}
}
{
while (n_ops > 0) {
size_t chunk = MIN(n_ops, MAX_OPS);
dpif_linux_operate__(dpif, ops, chunk);
ops += chunk; //防止n_ops太大,要分批量处理(MAX_OPS=50);
n_ops -= chunk;
}
}
static void
dpif_linux_operate__(struct dpif *dpif_, struct dpif_op **ops, size_t n_ops)
{
struct dpif_linux *dpif = dpif_linux_cast(dpif_);
struct op_auxdata {
struct nl_transaction txn;
struct ofpbuf request;
uint64_t request_stub[1024 / 8]; // ??
struct ofpbuf reply;
uint64_t reply_stub[1024 / 8];
} auxes[MAX_OPS];
struct nl_transaction *txnsp[MAX_OPS];
size_t i;
assert(n_ops <= MAX_OPS);
for (i = 0; i < n_ops; i++) {
struct op_auxdata *aux = &auxes[i];
struct dpif_op *op = ops[i];
struct dpif_flow_put *put;
struct dpif_flow_del *del;
struct dpif_execute *execute;
struct dpif_linux_flow flow;
ofpbuf_use_stub(&aux->request, aux->request_stub, sizeof aux->request_stub);
aux->txn.request = &aux->request;
ofpbuf_use_stub(&aux->reply, aux->reply_stub, sizeof aux->reply_stub);
aux->txn.reply = NULL;
switch (op->type) {
case DPIF_OP_FLOW_PUT:
put = &op->u.flow_put;
dpif_linux_init_flow_put(dpif_, put, &flow);
if (put->stats) {
flow.nlmsg_flags |= NLM_F_ECHO; //
aux->txn.reply = &aux->reply;
}
dpif_linux_flow_to_ofpbuf(&flow, &aux->request);
{
struct dpif_linux *dpif = dpif_linux_cast(dpif_);
struct op_auxdata {
struct nl_transaction txn;
struct ofpbuf request;
uint64_t request_stub[1024 / 8]; // ??
struct ofpbuf reply;
uint64_t reply_stub[1024 / 8];
} auxes[MAX_OPS];
struct nl_transaction *txnsp[MAX_OPS];
size_t i;
assert(n_ops <= MAX_OPS);
for (i = 0; i < n_ops; i++) {
struct op_auxdata *aux = &auxes[i];
struct dpif_op *op = ops[i];
struct dpif_flow_put *put;
struct dpif_flow_del *del;
struct dpif_execute *execute;
struct dpif_linux_flow flow;
ofpbuf_use_stub(&aux->request, aux->request_stub, sizeof aux->request_stub);
aux->txn.request = &aux->request;
ofpbuf_use_stub(&aux->reply, aux->reply_stub, sizeof aux->reply_stub);
aux->txn.reply = NULL;
switch (op->type) {
case DPIF_OP_FLOW_PUT:
put = &op->u.flow_put;
dpif_linux_init_flow_put(dpif_, put, &flow);
if (put->stats) {
flow.nlmsg_flags |= NLM_F_ECHO; //
aux->txn.reply = &aux->reply;
}
dpif_linux_flow_to_ofpbuf(&flow, &aux->request);
//这里会把&op->u.flow_put中dpif_flow_put 里面的key和action等信息,包装成nla的形式到&aux->request中;
break;
case DPIF_OP_FLOW_DEL:
del = &op->u.flow_del;
dpif_linux_init_flow_del(dpif_, del, &flow);
if (del->stats) {
flow.nlmsg_flags |= NLM_F_ECHO;
aux->txn.reply = &aux->reply;
}
dpif_linux_flow_to_ofpbuf(&flow, &aux->request);
break;
case DPIF_OP_EXECUTE:
execute = &op->u.execute;
dpif_linux_encode_execute(dpif->dp_ifindex, execute,&aux->request);
break;
default:
NOT_REACHED();
}
}
for (i = 0; i < n_ops; i++) {
txnsp[i] = &auxes[i].txn;
}
nl_sock_transact_multiple(genl_sock, txnsp, n_ops);
for (i = 0; i < n_ops; i++) {
struct op_auxdata *aux = &auxes[i];
struct nl_transaction *txn = &auxes[i].txn;
struct dpif_op *op = ops[i];
struct dpif_flow_put *put;
struct dpif_flow_del *del;
op->error = txn->error;
switch (op->type) {
case DPIF_OP_FLOW_PUT:
put = &op->u.flow_put;
if (put->stats) {
if (!op->error) {
struct dpif_linux_flow reply;
//将来自内核的reply:nla解析到dpif_linux_flow 结构体,继而用其中的状态统计信息完善dpif_flow_put ->stats字段中;
break;
case DPIF_OP_FLOW_DEL:
del = &op->u.flow_del;
dpif_linux_init_flow_del(dpif_, del, &flow);
if (del->stats) {
flow.nlmsg_flags |= NLM_F_ECHO;
aux->txn.reply = &aux->reply;
}
dpif_linux_flow_to_ofpbuf(&flow, &aux->request);
break;
case DPIF_OP_EXECUTE:
execute = &op->u.execute;
dpif_linux_encode_execute(dpif->dp_ifindex, execute,&aux->request);
break;
default:
NOT_REACHED();
}
}
for (i = 0; i < n_ops; i++) {
txnsp[i] = &auxes[i].txn;
}
nl_sock_transact_multiple(genl_sock, txnsp, n_ops);
for (i = 0; i < n_ops; i++) {
struct op_auxdata *aux = &auxes[i];
struct nl_transaction *txn = &auxes[i].txn;
struct dpif_op *op = ops[i];
struct dpif_flow_put *put;
struct dpif_flow_del *del;
op->error = txn->error;
switch (op->type) {
case DPIF_OP_FLOW_PUT:
put = &op->u.flow_put;
if (put->stats) {
if (!op->error) {
struct dpif_linux_flow reply;
//将来自内核的reply:nla解析到dpif_linux_flow 结构体,继而用其中的状态统计信息完善dpif_flow_put ->stats字段中;
op->error =
dpif_linux_flow_from_ofpbuf(&reply,txn->reply);
if (!op->error) {
dpif_linux_flow_get_stats(&reply, put->stats);
}
}
if (op->error) {
memset(put->stats, 0, sizeof *put->stats);
}
}
break;
case DPIF_OP_FLOW_DEL:
del = &op->u.flow_del;
if (del->stats) {
if (!op->error) {
struct dpif_linux_flow reply;
op->error = dpif_linux_flow_from_ofpbuf(&reply,txn->reply);
if (!op->error) {
dpif_linux_flow_get_stats(&reply, del->stats);
}
}
if (op->error) {
memset(del->stats, 0, sizeof *del->stats);
}
}
break;
case DPIF_OP_EXECUTE: //底层执行了就行;
break;
default:
NOT_REACHED();
}
ofpbuf_uninit(&aux->request);
ofpbuf_uninit(&aux->reply);
}
}
if (!op->error) {
dpif_linux_flow_get_stats(&reply, put->stats);
}
}
if (op->error) {
memset(put->stats, 0, sizeof *put->stats);
}
}
break;
case DPIF_OP_FLOW_DEL:
del = &op->u.flow_del;
if (del->stats) {
if (!op->error) {
struct dpif_linux_flow reply;
op->error = dpif_linux_flow_from_ofpbuf(&reply,txn->reply);
if (!op->error) {
dpif_linux_flow_get_stats(&reply, del->stats);
}
}
if (op->error) {
memset(del->stats, 0, sizeof *del->stats);
}
}
break;
case DPIF_OP_EXECUTE: //底层执行了就行;
break;
default:
NOT_REACHED();
}
ofpbuf_uninit(&aux->request);
ofpbuf_uninit(&aux->reply);
}
}
/* Datapath interface for the openvswitch Linux kernel module. */
struct dpif_linux {
struct dpif dpif;
int dp_ifindex;
/* Upcall messages. */
struct dpif_channel channels[N_CHANNELS];
uint32_t ready_mask; /* 1-bit for each sock with unread messages. */
int epoll_fd; /* epoll fd that includes channel socks. */
long long int next_scale; /* Next time to scale down the sketches. */
/* Change notification. */
struct sset changed_ports; /* Ports that have changed. */
struct nln_notifier *port_notifier;
bool change_error;
/* Port number allocation. */
uint16_t alloc_port_no;
};
--------------lib/netlink-socket.h
nl_transaction 表征的是用户空间和内核空间通信的一次抽象
/* Batching transactions. */
struct nl_transaction {
/* Filled in by client. */
struct ofpbuf *request; /* Request to send. */
struct ofpbuf *reply; /* Reply (empty if reply was an error code). */
struct nl_transaction {
/* Filled in by client. */
struct ofpbuf *request; /* Request to send. */
struct ofpbuf *reply; /* Reply (empty if reply was an error code). */
//客户必须要初始化reply,NULL:如果不会在意响应;否则就该指向已分配的内存空间,至少要能容纳nlmsg header;
int error; /* Positive errno value, 0 if no error. */
};
int error; /* Positive errno value, 0 if no error. */
};
---------------lib/dpif-linux.c
struct
dpif_linux_flow {
/* Generic Netlink header. */
uint8_t cmd;
/* struct ovs_header. */
unsigned int nlmsg_flags;
int dp_ifindex;
/* Attributes.
*
* The 'stats' member points to 64-bit data that might only be aligned on
* 32-bit boundaries, so get_unaligned_u64() should be used to access its
* values.
*
* If 'actions' is nonnull then OVS_FLOW_ATTR_ACTIONS will be included in
* the Netlink version of the command, even if actions_len is zero. */
const struct nlattr *key; /* OVS_FLOW_ATTR_KEY. */
size_t key_len;
const struct nlattr *actions; /* OVS_FLOW_ATTR_ACTIONS. */
size_t actions_len;
const struct ovs_flow_stats *stats; /* OVS_FLOW_ATTR_STATS. */
const uint8_t *tcp_flags; /* OVS_FLOW_ATTR_TCP_FLAGS. */
const ovs_32aligned_u64 *used; /* OVS_FLOW_ATTR_USED. */
bool clear; /* OVS_FLOW_ATTR_CLEAR. */
};
/* Generic Netlink header. */
uint8_t cmd;
/* struct ovs_header. */
unsigned int nlmsg_flags;
int dp_ifindex;
/* Attributes.
*
* The 'stats' member points to 64-bit data that might only be aligned on
* 32-bit boundaries, so get_unaligned_u64() should be used to access its
* values.
*
* If 'actions' is nonnull then OVS_FLOW_ATTR_ACTIONS will be included in
* the Netlink version of the command, even if actions_len is zero. */
const struct nlattr *key; /* OVS_FLOW_ATTR_KEY. */
size_t key_len;
const struct nlattr *actions; /* OVS_FLOW_ATTR_ACTIONS. */
size_t actions_len;
const struct ovs_flow_stats *stats; /* OVS_FLOW_ATTR_STATS. */
const uint8_t *tcp_flags; /* OVS_FLOW_ATTR_TCP_FLAGS. */
const ovs_32aligned_u64 *used; /* OVS_FLOW_ATTR_USED. */
bool clear; /* OVS_FLOW_ATTR_CLEAR. */
};
static void dpif_linux_init_flow_put (struct dpif *dpif_, const struct dpif_flow_put *put, struct dpif_linux_flow *request)
{
static struct nlattr dummy_action;
struct dpif_linux *dpif = dpif_linux_cast(dpif_);
dpif_linux_flow_init(request);
request->cmd = (put->flags & DPIF_FP_CREATE ? OVS_FLOW_CMD_NEW : OVS_FLOW_CMD_SET);
request->dp_ifindex = dpif->dp_ifindex;
request->key = put->key;
request->key_len = put->key_len;
/* Ensure that OVS_FLOW_ATTR_ACTIONS will always be included. */
request->actions = put->actions ? put->actions : &dummy_action;
request->actions_len = put->actions_len;
if (put->flags & DPIF_FP_ZERO_STATS) {
request->clear = true;
}
request->nlmsg_flags = put->flags & DPIF_FP_MODIFY ? 0 : NLM_F_CREATE;
}
填充缓冲区ofbuf:ovsheader+nla(其中ovsheader中有dp_ifindex,nla包括key和action);
static void
dpif_linux_flow_to_ofpbuf(const struct dpif_linux_flow *flow, struct ofpbuf *buf)
{
struct ovs_header *ovs_header;
nl_msg_put_genlmsghdr(buf, 0, ovs_flow_family,NLM_F_REQUEST | flow->nlmsg_flags,
flow->cmd, OVS_FLOW_VERSION);
ovs_header = ofpbuf_put_uninit(buf, sizeof *ovs_header);
ovs_header->dp_ifindex = flow->dp_ifindex;
if (flow->key_len) {
nl_msg_put_unspec(buf, OVS_FLOW_ATTR_KEY, flow->key, flow->key_len);
}
if (flow->actions || flow->actions_len) {
nl_msg_put_unspec(buf, OVS_FLOW_ATTR_ACTIONS, flow->actions, flow->actions_len);
}
/* We never need to send these to the kernel. */
assert(!flow->stats);
assert(!flow->tcp_flags);
assert(!flow->used);
if (flow->clear) {
nl_msg_put_flag(buf, OVS_FLOW_ATTR_CLEAR);
}
}
{
struct ovs_header *ovs_header;
nl_msg_put_genlmsghdr(buf, 0, ovs_flow_family,NLM_F_REQUEST | flow->nlmsg_flags,
flow->cmd, OVS_FLOW_VERSION);
ovs_header = ofpbuf_put_uninit(buf, sizeof *ovs_header);
ovs_header->dp_ifindex = flow->dp_ifindex;
if (flow->key_len) {
nl_msg_put_unspec(buf, OVS_FLOW_ATTR_KEY, flow->key, flow->key_len);
}
if (flow->actions || flow->actions_len) {
nl_msg_put_unspec(buf, OVS_FLOW_ATTR_ACTIONS, flow->actions, flow->actions_len);
}
/* We never need to send these to the kernel. */
assert(!flow->stats);
assert(!flow->tcp_flags);
assert(!flow->used);
if (flow->clear) {
nl_msg_put_flag(buf, OVS_FLOW_ATTR_CLEAR);
}
}
---------------lib/netlink-socket.c
通过netlink socket将nl_transaction中的request发送到内核层,并且接收回应到reply中,在发送每个消息之前,该函数会根据定长每个请求中的nlmsg_len来适应ofpbuf的大小,设置nlmsg_pid,初始化nlmsg_seq。(纯粹的netlink是不可靠的传输协议),
最终这个函数执行成功返回后,**transactions里面含有来自内核的响应信息。
void
nl_sock_transact_multiple(struct nl_sock *sock,struct nl_transaction **transactions, size_t n)
{
int max_batch_count;
int error;
if (!n) {
return;
}
error = nl_sock_cow__(sock);
if (error) {
nl_sock_record_errors__(transactions, n, error);
return;
}
/* In theory, every request could have a 64 kB reply. But the default and
* maximum socket rcvbuf size with typical Dom0 memory sizes both tend to
* be a bit below 128 kB, so that would only allow a single message in a
* "batch". So we assume that replies average (at most) 4 kB, which allows
* a good deal of batching.
*
* In practice, most of the requests that we batch either have no reply at
* all or a brief reply. */
max_batch_count = MAX(sock->rcvbuf / 4096, 1);
max_batch_count = MIN(max_batch_count, max_iovs);
while (n > 0) {
size_t count, bytes;
size_t done;
/* Batch up to 'max_batch_count' transactions. But cap it at about a
* page of requests total because big skbuffs are expensive to
* allocate in the kernel. */
#if defined(PAGESIZE)
enum { MAX_BATCH_BYTES = MAX(1, PAGESIZE - 512) };
#else
enum { MAX_BATCH_BYTES = 4096 - 512 };
#endif
bytes = transactions[0]->request->size;
for (count = 1; count < n && count < max_batch_count; count++) {
if (bytes + transactions[count]->request->size > MAX_BATCH_BYTES) {
break;
}
bytes += transactions[count]->request->size;
}
error = nl_sock_transact_multiple__(sock, transactions, count, &done);
transactions += done;
n -= done;
if (error == ENOBUFS) {
VLOG_DBG_RL(&rl, "receive buffer overflow, resending request");
} else if (error) {
VLOG_ERR_RL(&rl, "transaction error (%s)", strerror(error));
nl_sock_record_errors__(transactions, n, error);
}
}
}
{
int max_batch_count;
int error;
if (!n) {
return;
}
error = nl_sock_cow__(sock);
if (error) {
nl_sock_record_errors__(transactions, n, error);
return;
}
/* In theory, every request could have a 64 kB reply. But the default and
* maximum socket rcvbuf size with typical Dom0 memory sizes both tend to
* be a bit below 128 kB, so that would only allow a single message in a
* "batch". So we assume that replies average (at most) 4 kB, which allows
* a good deal of batching.
*
* In practice, most of the requests that we batch either have no reply at
* all or a brief reply. */
max_batch_count = MAX(sock->rcvbuf / 4096, 1);
max_batch_count = MIN(max_batch_count, max_iovs);
while (n > 0) {
size_t count, bytes;
size_t done;
/* Batch up to 'max_batch_count' transactions. But cap it at about a
* page of requests total because big skbuffs are expensive to
* allocate in the kernel. */
#if defined(PAGESIZE)
enum { MAX_BATCH_BYTES = MAX(1, PAGESIZE - 512) };
#else
enum { MAX_BATCH_BYTES = 4096 - 512 };
#endif
bytes = transactions[0]->request->size;
for (count = 1; count < n && count < max_batch_count; count++) {
if (bytes + transactions[count]->request->size > MAX_BATCH_BYTES) {
break;
}
bytes += transactions[count]->request->size;
}
error = nl_sock_transact_multiple__(sock, transactions, count, &done);
transactions += done;
n -= done;
if (error == ENOBUFS) {
VLOG_DBG_RL(&rl, "receive buffer overflow, resending request");
} else if (error) {
VLOG_ERR_RL(&rl, "transaction error (%s)", strerror(error));
nl_sock_record_errors__(transactions, n, error);
}
}
}
static int
nl_sock_transact_multiple__(struct nl_sock *sock,struct nl_transaction **transactions, size_t n,size_t *done)
{
uint64_t tmp_reply_stub[1024 / 8];
struct nl_transaction tmp_txn;
struct ofpbuf tmp_reply;
uint32_t base_seq;
struct iovec iovs[MAX_IOVS];
struct msghdr msg;
int error;
int i;
base_seq = nl_sock_allocate_seq(sock, n);
*done = 0;
for (i = 0; i < n; i++) {
struct nl_transaction *txn = transactions[i];
struct nlmsghdr *nlmsg = nl_msg_nlmsghdr(txn->request);
nlmsg->nlmsg_len = txn->request->size;
nlmsg->nlmsg_seq = base_seq + i;
nlmsg->nlmsg_pid = sock->pid;
iovs[i].iov_base = txn->request->data;
iovs[i].iov_len = txn->request->size;
}
memset(&msg, 0, sizeof msg);
msg.msg_iov = iovs;
msg.msg_iovlen = n;
do {
error = sendmsg(sock->fd, &msg, 0) < 0 ? errno : 0;
} while (error == EINTR);
for (i = 0; i < n; i++) {
struct nl_transaction *txn = transactions[i];
log_nlmsg(__func__, error, txn->request->data, txn->request->size,sock->protocol);
}
if (!error) {
COVERAGE_ADD(netlink_sent, n);
}
if (error) {
return error;
}
ofpbuf_use_stub(&tmp_reply, tmp_reply_stub, sizeof tmp_reply_stub);
tmp_txn.request = NULL;
tmp_txn.reply = &tmp_reply;
tmp_txn.error = 0;
while (n > 0) {
struct nl_transaction *buf_txn, *txn;
uint32_t seq;
/* Find a transaction whose buffer we can use for receiving a reply.
* If no such transaction is left, use tmp_txn. */
buf_txn = &tmp_txn;
for (i = 0; i < n; i++) {
if (transactions[i]->reply) {
buf_txn = transactions[i];
break;
}
}
/* Receive a reply. */
error = nl_sock_recv__(sock, buf_txn->reply, false);
if (error) {
if (error == EAGAIN) {
nl_sock_record_errors__(transactions, n, 0);
*done += n;
error = 0;
}
break;
}
/* Match the reply up with a transaction. */
seq = nl_msg_nlmsghdr(buf_txn->reply)->nlmsg_seq;
if (seq < base_seq || seq >= base_seq + n) {
VLOG_DBG_RL(&rl, "ignoring unexpected seq %#"PRIx32, seq);
continue;
}
i = seq - base_seq;
txn = transactions[i];
/* Fill in the results for 'txn'. */
if (nl_msg_nlmsgerr(buf_txn->reply, &txn->error)) {
if (txn->reply) {
ofpbuf_clear(txn->reply);
}
if (txn->error) {
VLOG_DBG_RL(&rl, "received NAK error=%d (%s)", error, strerror(txn->error));
}
} else {
txn->error = 0;
if (txn->reply && txn != buf_txn) {
/* Swap buffers. */
struct ofpbuf *reply = buf_txn->reply;
buf_txn->reply = txn->reply;
txn->reply = reply;
}
}
/* Fill in the results for transactions before 'txn'. (We have to do
* this after the results for 'txn' itself because of the buffer swap
* above.) */
nl_sock_record_errors__(transactions, i, 0);
/* Advance. */
*done += i + 1;
transactions += i + 1;
n -= i + 1;
base_seq += i + 1;
}
ofpbuf_uninit(&tmp_reply);
return error;
}
{
uint64_t tmp_reply_stub[1024 / 8];
struct nl_transaction tmp_txn;
struct ofpbuf tmp_reply;
uint32_t base_seq;
struct iovec iovs[MAX_IOVS];
struct msghdr msg;
int error;
int i;
base_seq = nl_sock_allocate_seq(sock, n);
*done = 0;
for (i = 0; i < n; i++) {
struct nl_transaction *txn = transactions[i];
struct nlmsghdr *nlmsg = nl_msg_nlmsghdr(txn->request);
nlmsg->nlmsg_len = txn->request->size;
nlmsg->nlmsg_seq = base_seq + i;
nlmsg->nlmsg_pid = sock->pid;
iovs[i].iov_base = txn->request->data;
iovs[i].iov_len = txn->request->size;
}
memset(&msg, 0, sizeof msg);
msg.msg_iov = iovs;
msg.msg_iovlen = n;
do {
error = sendmsg(sock->fd, &msg, 0) < 0 ? errno : 0;
} while (error == EINTR);
for (i = 0; i < n; i++) {
struct nl_transaction *txn = transactions[i];
log_nlmsg(__func__, error, txn->request->data, txn->request->size,sock->protocol);
}
if (!error) {
COVERAGE_ADD(netlink_sent, n);
}
if (error) {
return error;
}
ofpbuf_use_stub(&tmp_reply, tmp_reply_stub, sizeof tmp_reply_stub);
tmp_txn.request = NULL;
tmp_txn.reply = &tmp_reply;
tmp_txn.error = 0;
while (n > 0) {
struct nl_transaction *buf_txn, *txn;
uint32_t seq;
/* Find a transaction whose buffer we can use for receiving a reply.
* If no such transaction is left, use tmp_txn. */
buf_txn = &tmp_txn;
for (i = 0; i < n; i++) {
if (transactions[i]->reply) {
buf_txn = transactions[i];
break;
}
}
/* Receive a reply. */
error = nl_sock_recv__(sock, buf_txn->reply, false);
if (error) {
if (error == EAGAIN) {
nl_sock_record_errors__(transactions, n, 0);
*done += n;
error = 0;
}
break;
}
/* Match the reply up with a transaction. */
seq = nl_msg_nlmsghdr(buf_txn->reply)->nlmsg_seq;
if (seq < base_seq || seq >= base_seq + n) {
VLOG_DBG_RL(&rl, "ignoring unexpected seq %#"PRIx32, seq);
continue;
}
i = seq - base_seq;
txn = transactions[i];
/* Fill in the results for 'txn'. */
if (nl_msg_nlmsgerr(buf_txn->reply, &txn->error)) {
if (txn->reply) {
ofpbuf_clear(txn->reply);
}
if (txn->error) {
VLOG_DBG_RL(&rl, "received NAK error=%d (%s)", error, strerror(txn->error));
}
} else {
txn->error = 0;
if (txn->reply && txn != buf_txn) {
/* Swap buffers. */
struct ofpbuf *reply = buf_txn->reply;
buf_txn->reply = txn->reply;
txn->reply = reply;
}
}
/* Fill in the results for transactions before 'txn'. (We have to do
* this after the results for 'txn' itself because of the buffer swap
* above.) */
nl_sock_record_errors__(transactions, i, 0);
/* Advance. */
*done += i + 1;
transactions += i + 1;
n -= i + 1;
base_seq += i + 1;
}
ofpbuf_uninit(&tmp_reply);
return error;
}
static int
nl_sock_recv__(struct nl_sock *sock, struct ofpbuf *buf, bool wait)
{
/* We can't accurately predict the size of the data to be received. The
* caller is supposed to have allocated enough space in 'buf' to handle the
* "typical" case. To handle exceptions, we make available enough space in
* 'tail' to allow Netlink messages to be up to 64 kB long (a reasonable
* figure since that's the maximum length of a Netlink attribute). */
struct nlmsghdr *nlmsghdr;
uint8_t tail[65536];
struct iovec iov[2];
struct msghdr msg;
ssize_t retval;
assert(buf->allocated >= sizeof *nlmsghdr);
ofpbuf_clear(buf);
iov[0].iov_base = buf->base;
iov[0].iov_len = buf->allocated;
iov[1].iov_base = tail;
iov[1].iov_len = sizeof tail;
memset(&msg, 0, sizeof msg);
msg.msg_iov = iov;
msg.msg_iovlen = 2;
do {
retval = recvmsg(sock->fd, &msg, wait ? 0 : MSG_DONTWAIT);
} while (retval < 0 && errno == EINTR);
if (retval < 0) {
int error = errno;
if (error == ENOBUFS) {
/* Socket receive buffer overflow dropped one or more messages that
* the kernel tried to send to us. */
COVERAGE_INC(netlink_overflow);
}
return error;
}
if (msg.msg_flags & MSG_TRUNC) {
VLOG_ERR_RL(&rl, "truncated message (longer than %zu bytes)",
sizeof tail);
return E2BIG;
}
nlmsghdr = buf->data;
if (retval < sizeof *nlmsghdr
|| nlmsghdr->nlmsg_len < sizeof *nlmsghdr
|| nlmsghdr->nlmsg_len > retval) {
VLOG_ERR_RL(&rl, "received invalid nlmsg (%zd bytes < %zu)",
retval, sizeof *nlmsghdr);
return EPROTO;
}
if (STRESS(netlink_overflow)) {
return ENOBUFS;
}
buf->size = MIN(retval, buf->allocated);
if (retval > buf->allocated) {
COVERAGE_INC(netlink_recv_jumbo);
ofpbuf_put(buf, tail, retval - buf->allocated);
}
log_nlmsg(__func__, 0, buf->data, buf->size, sock->protocol);
COVERAGE_INC(netlink_received);
return 0;
}
{
/* We can't accurately predict the size of the data to be received. The
* caller is supposed to have allocated enough space in 'buf' to handle the
* "typical" case. To handle exceptions, we make available enough space in
* 'tail' to allow Netlink messages to be up to 64 kB long (a reasonable
* figure since that's the maximum length of a Netlink attribute). */
struct nlmsghdr *nlmsghdr;
uint8_t tail[65536];
struct iovec iov[2];
struct msghdr msg;
ssize_t retval;
assert(buf->allocated >= sizeof *nlmsghdr);
ofpbuf_clear(buf);
iov[0].iov_base = buf->base;
iov[0].iov_len = buf->allocated;
iov[1].iov_base = tail;
iov[1].iov_len = sizeof tail;
memset(&msg, 0, sizeof msg);
msg.msg_iov = iov;
msg.msg_iovlen = 2;
do {
retval = recvmsg(sock->fd, &msg, wait ? 0 : MSG_DONTWAIT);
} while (retval < 0 && errno == EINTR);
if (retval < 0) {
int error = errno;
if (error == ENOBUFS) {
/* Socket receive buffer overflow dropped one or more messages that
* the kernel tried to send to us. */
COVERAGE_INC(netlink_overflow);
}
return error;
}
if (msg.msg_flags & MSG_TRUNC) {
VLOG_ERR_RL(&rl, "truncated message (longer than %zu bytes)",
sizeof tail);
return E2BIG;
}
nlmsghdr = buf->data;
if (retval < sizeof *nlmsghdr
|| nlmsghdr->nlmsg_len < sizeof *nlmsghdr
|| nlmsghdr->nlmsg_len > retval) {
VLOG_ERR_RL(&rl, "received invalid nlmsg (%zd bytes < %zu)",
retval, sizeof *nlmsghdr);
return EPROTO;
}
if (STRESS(netlink_overflow)) {
return ENOBUFS;
}
buf->size = MIN(retval, buf->allocated);
if (retval > buf->allocated) {
COVERAGE_INC(netlink_recv_jumbo);
ofpbuf_put(buf, tail, retval - buf->allocated);
}
log_nlmsg(__func__, 0, buf->data, buf->size, sock->protocol);
COVERAGE_INC(netlink_received);
return 0;
}
将缓存中的内容按照ovs_flow_policy策略解析到dpif_linux_flow 中,该结构体中有字段指向ofpbuf,所以当调用者在使用这个flow的时候,不能释放这个缓存。
static int
dpif_linux_flow_from_ofpbuf(struct dpif_linux_flow *flow, const struct ofpbuf *buf)
{
static const struct nl_policy ovs_flow_policy[] = {
[OVS_FLOW_ATTR_KEY] = { .type = NL_A_NESTED },
[OVS_FLOW_ATTR_ACTIONS] = { .type = NL_A_NESTED, .optional = true },
[OVS_FLOW_ATTR_STATS] = { NL_POLICY_FOR(struct ovs_flow_stats), .optional = true },
[OVS_FLOW_ATTR_TCP_FLAGS] = { .type = NL_A_U8, .optional = true },
[OVS_FLOW_ATTR_USED] = { .type = NL_A_U64, .optional = true },
/* The kernel never uses OVS_FLOW_ATTR_CLEAR. */
};
struct nlattr *a[ARRAY_SIZE(ovs_flow_policy)];
struct ovs_header *ovs_header;
struct nlmsghdr *nlmsg;
struct genlmsghdr *genl;
struct ofpbuf b;
dpif_linux_flow_init(flow);
ofpbuf_use_const(&b, buf->data, buf->size);
nlmsg = ofpbuf_try_pull(&b, sizeof *nlmsg);
genl = ofpbuf_try_pull(&b, sizeof *genl);
ovs_header = ofpbuf_try_pull(&b, sizeof *ovs_header);
if (!nlmsg || !genl || !ovs_header
|| nlmsg->nlmsg_type != ovs_flow_family
|| !nl_policy_parse(&b, 0, ovs_flow_policy, a,
ARRAY_SIZE(ovs_flow_policy))) {
return EINVAL;
}
flow->nlmsg_flags = nlmsg->nlmsg_flags;
flow->dp_ifindex = ovs_header->dp_ifindex;
flow->key = nl_attr_get(a[OVS_FLOW_ATTR_KEY]);
flow->key_len = nl_attr_get_size(a[OVS_FLOW_ATTR_KEY]);
if (a[OVS_FLOW_ATTR_ACTIONS]) {
flow->actions = nl_attr_get(a[OVS_FLOW_ATTR_ACTIONS]);
flow->actions_len = nl_attr_get_size(a[OVS_FLOW_ATTR_ACTIONS]);
}
if (a[OVS_FLOW_ATTR_STATS]) {
flow->stats = nl_attr_get(a[OVS_FLOW_ATTR_STATS]);
}
if (a[OVS_FLOW_ATTR_TCP_FLAGS]) {
flow->tcp_flags = nl_attr_get(a[OVS_FLOW_ATTR_TCP_FLAGS]);
}
if (a[OVS_FLOW_ATTR_USED]) {
flow->used = nl_attr_get(a[OVS_FLOW_ATTR_USED]);
}
return 0;
}
{
static const struct nl_policy ovs_flow_policy[] = {
[OVS_FLOW_ATTR_KEY] = { .type = NL_A_NESTED },
[OVS_FLOW_ATTR_ACTIONS] = { .type = NL_A_NESTED, .optional = true },
[OVS_FLOW_ATTR_STATS] = { NL_POLICY_FOR(struct ovs_flow_stats), .optional = true },
[OVS_FLOW_ATTR_TCP_FLAGS] = { .type = NL_A_U8, .optional = true },
[OVS_FLOW_ATTR_USED] = { .type = NL_A_U64, .optional = true },
/* The kernel never uses OVS_FLOW_ATTR_CLEAR. */
};
struct nlattr *a[ARRAY_SIZE(ovs_flow_policy)];
struct ovs_header *ovs_header;
struct nlmsghdr *nlmsg;
struct genlmsghdr *genl;
struct ofpbuf b;
dpif_linux_flow_init(flow);
ofpbuf_use_const(&b, buf->data, buf->size);
nlmsg = ofpbuf_try_pull(&b, sizeof *nlmsg);
genl = ofpbuf_try_pull(&b, sizeof *genl);
ovs_header = ofpbuf_try_pull(&b, sizeof *ovs_header);
if (!nlmsg || !genl || !ovs_header
|| nlmsg->nlmsg_type != ovs_flow_family
|| !nl_policy_parse(&b, 0, ovs_flow_policy, a,
ARRAY_SIZE(ovs_flow_policy))) {
return EINVAL;
}
flow->nlmsg_flags = nlmsg->nlmsg_flags;
flow->dp_ifindex = ovs_header->dp_ifindex;
flow->key = nl_attr_get(a[OVS_FLOW_ATTR_KEY]);
flow->key_len = nl_attr_get_size(a[OVS_FLOW_ATTR_KEY]);
if (a[OVS_FLOW_ATTR_ACTIONS]) {
flow->actions = nl_attr_get(a[OVS_FLOW_ATTR_ACTIONS]);
flow->actions_len = nl_attr_get_size(a[OVS_FLOW_ATTR_ACTIONS]);
}
if (a[OVS_FLOW_ATTR_STATS]) {
flow->stats = nl_attr_get(a[OVS_FLOW_ATTR_STATS]);
}
if (a[OVS_FLOW_ATTR_TCP_FLAGS]) {
flow->tcp_flags = nl_attr_get(a[OVS_FLOW_ATTR_TCP_FLAGS]);
}
if (a[OVS_FLOW_ATTR_USED]) {
flow->used = nl_attr_get(a[OVS_FLOW_ATTR_USED]);
}
return 0;
}
static int
dpif_flow_put__(struct dpif *dpif, const struct dpif_flow_put *put)
{
int error;
COVERAGE_INC(dpif_flow_put);
assert(!(put->flags & ~(DPIF_FP_CREATE | DPIF_FP_MODIFY | DPIF_FP_ZERO_STATS)));
error = dpif->dpif_class->flow_put(dpif, put);
if (error && put->stats) {
memset(put->stats, 0, sizeof *put->stats);
}
log_flow_put_message(dpif, put, error);
return error;
}
{
int error;
COVERAGE_INC(dpif_flow_put);
assert(!(put->flags & ~(DPIF_FP_CREATE | DPIF_FP_MODIFY | DPIF_FP_ZERO_STATS)));
error = dpif->dpif_class->flow_put(dpif, put);
if (error && put->stats) {
memset(put->stats, 0, sizeof *put->stats);
}
log_flow_put_message(dpif, put, error);
return error;
}
static int
dpif_linux_flow_put(struct dpif *dpif_, const struct dpif_flow_put *put)
{
struct dpif_linux_flow request, reply;
struct ofpbuf *buf;
int error;
dpif_linux_init_flow_put(dpif_, put, &request);
error = dpif_linux_flow_transact(&request, put->stats ? &reply : NULL, put->stats ? &buf : NULL);
if (!error && put->stats) {
dpif_linux_flow_get_stats(&reply, put->stats);
ofpbuf_delete(buf);
}
return error;
}
{
struct dpif_linux_flow request, reply;
struct ofpbuf *buf;
int error;
dpif_linux_init_flow_put(dpif_, put, &request);
error = dpif_linux_flow_transact(&request, put->stats ? &reply : NULL, put->stats ? &buf : NULL);
if (!error && put->stats) {
dpif_linux_flow_get_stats(&reply, put->stats);
ofpbuf_delete(buf);
}
return error;
}
/* Executes 'request' in the kernel datapath. If the command fails, returns a
* positive errno value. Otherwise, if 'reply' and 'bufp' are null, returns 0
* without doing anything else. If 'reply' and 'bufp' are nonnull, then the
* result of the command is expected to be a flow also, which is decoded and
* stored in '*reply' and '*bufp'. The caller must free '*bufp' when the reply
* is no longer needed ('reply' will contain pointers into '*bufp'). */
static int dpif_linux_flow_transact(struct dpif_linux_flow *request, struct dpif_linux_flow *reply, struct ofpbuf **bufp)
{
struct ofpbuf *request_buf;
int error;
assert((reply != NULL) == (bufp != NULL));
if (reply) {
request->nlmsg_flags |= NLM_F_ECHO;
}
request_buf = ofpbuf_new(1024);
dpif_linux_flow_to_ofpbuf(request, request_buf);
error = nl_sock_transact(genl_sock, request_buf, bufp);
ofpbuf_delete(request_buf);
if (reply) {
if (!error) {
error = dpif_linux_flow_from_ofpbuf(reply, *bufp);
}
if (error) {
dpif_linux_flow_init(reply);
ofpbuf_delete(*bufp);
*bufp = NULL;
}
}
return error;
}
* positive errno value. Otherwise, if 'reply' and 'bufp' are null, returns 0
* without doing anything else. If 'reply' and 'bufp' are nonnull, then the
* result of the command is expected to be a flow also, which is decoded and
* stored in '*reply' and '*bufp'. The caller must free '*bufp' when the reply
* is no longer needed ('reply' will contain pointers into '*bufp'). */
static int dpif_linux_flow_transact(struct dpif_linux_flow *request, struct dpif_linux_flow *reply, struct ofpbuf **bufp)
{
struct ofpbuf *request_buf;
int error;
assert((reply != NULL) == (bufp != NULL));
if (reply) {
request->nlmsg_flags |= NLM_F_ECHO;
}
request_buf = ofpbuf_new(1024);
dpif_linux_flow_to_ofpbuf(request, request_buf);
error = nl_sock_transact(genl_sock, request_buf, bufp);
ofpbuf_delete(request_buf);
if (reply) {
if (!error) {
error = dpif_linux_flow_from_ofpbuf(reply, *bufp);
}
if (error) {
dpif_linux_flow_init(reply);
ofpbuf_delete(*bufp);
*bufp = NULL;
}
}
return error;
}
static int
dpif_linux_flow_del(struct dpif *dpif_, const struct dpif_flow_del *del)
{
struct dpif_linux_flow request, reply;
struct ofpbuf *buf;
int error;
dpif_linux_init_flow_del(dpif_, del, &request);
error = dpif_linux_flow_transact(&request, del->stats ? &reply : NULL, del->stats ? &buf : NULL);
if (!error && del->stats) {
dpif_linux_flow_get_stats(&reply, del->stats);
ofpbuf_delete(buf);
}
return error;
}
{
struct dpif_linux_flow request, reply;
struct ofpbuf *buf;
int error;
dpif_linux_init_flow_del(dpif_, del, &request);
error = dpif_linux_flow_transact(&request, del->stats ? &reply : NULL, del->stats ? &buf : NULL);
if (!error && del->stats) {
dpif_linux_flow_get_stats(&reply, del->stats);
ofpbuf_delete(buf);
}
return error;
}
static int
dpif_linux_execute(struct dpif *dpif_, const struct dpif_execute *execute)
{
struct dpif_linux *dpif = dpif_linux_cast(dpif_);
return dpif_linux_execute__(dpif->dp_ifindex, execute);
}
{
struct dpif_linux *dpif = dpif_linux_cast(dpif_);
return dpif_linux_execute__(dpif->dp_ifindex, execute);
}
static int
dpif_linux_execute__(int dp_ifindex, const struct dpif_execute *execute)
{
uint64_t request_stub[1024 / 8];
struct ofpbuf request;
int error;
ofpbuf_use_stub(&request, request_stub, sizeof request_stub);
dpif_linux_encode_execute(dp_ifindex, execute, &request);
error = nl_sock_transact(genl_sock, &request, NULL);
ofpbuf_uninit(&request);
return error;
}
{
uint64_t request_stub[1024 / 8];
struct ofpbuf request;
int error;
ofpbuf_use_stub(&request, request_stub, sizeof request_stub);
dpif_linux_encode_execute(dp_ifindex, execute, &request);
error = nl_sock_transact(genl_sock, &request, NULL);
ofpbuf_uninit(&request);
return error;
}
static void
dpif_linux_encode_execute(int dp_ifindex, const struct dpif_execute *d_exec,struct ofpbuf *buf)
{
struct ovs_header *k_exec;
ofpbuf_prealloc_tailroom(buf, (64 + d_exec->packet->size + d_exec->key_len + d_exec->actions_len));
nl_msg_put_genlmsghdr(buf, 0, ovs_packet_family, NLM_F_REQUEST, OVS_PACKET_CMD_EXECUTE, OVS_PACKET_VERSION);
k_exec = ofpbuf_put_uninit(buf, sizeof *k_exec);
k_exec->dp_ifindex = dp_ifindex;
nl_msg_put_unspec(buf, OVS_PACKET_ATTR_PACKET,d_exec->packet->data, d_exec->packet->size);
nl_msg_put_unspec(buf, OVS_PACKET_ATTR_KEY, d_exec->key, d_exec->key_len);
nl_msg_put_unspec(buf, OVS_PACKET_ATTR_ACTIONS, d_exec->actions, d_exec->actions_len);
}
{
struct ovs_header *k_exec;
ofpbuf_prealloc_tailroom(buf, (64 + d_exec->packet->size + d_exec->key_len + d_exec->actions_len));
nl_msg_put_genlmsghdr(buf, 0, ovs_packet_family, NLM_F_REQUEST, OVS_PACKET_CMD_EXECUTE, OVS_PACKET_VERSION);
k_exec = ofpbuf_put_uninit(buf, sizeof *k_exec);
k_exec->dp_ifindex = dp_ifindex;
nl_msg_put_unspec(buf, OVS_PACKET_ATTR_PACKET,d_exec->packet->data, d_exec->packet->size);
nl_msg_put_unspec(buf, OVS_PACKET_ATTR_KEY, d_exec->key, d_exec->key_len);
nl_msg_put_unspec(buf, OVS_PACKET_ATTR_ACTIONS, d_exec->actions, d_exec->actions_len);
}