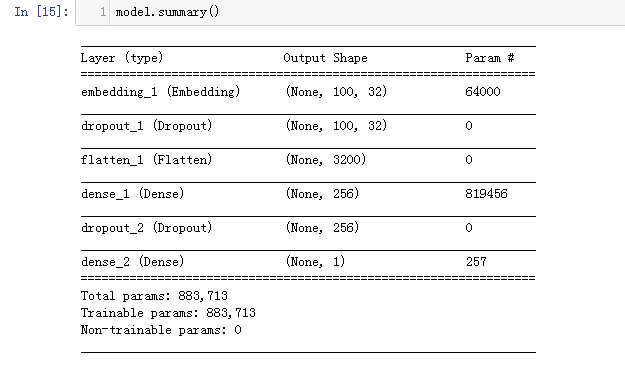
步骤5:Embedding层将“数字列表”转化为"向量列表"(加入嵌入层)
1.导入所需模块
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation,Flatten
from keras.layers.embeddings import Embedding
2.建立模型
建立一个线性堆叠模型,后续只需将各个神经网络加入模型即可
model = Sequential()
3.将嵌入层加入模型
model.add(Embedding(output_dim=32, #输出维度为32,我们希望将数字列表转化为32维的向量
input_dim=2000, #输入的维度是2000,因为之前建立的字典有2000单词
input_length=100)) #数字列表每一项有100个数字
model.add(Dropout(0.2)) #加入dropout避免过度拟合
步骤6:将向量列表送入深度学习模型进行训练
1.多层感知机
1.1 建立多层感知机模型
(1)将平坦层加入模型
model.add(Flatten())
每一项100个数字,一个数字转化为32维向量,所以转换为平坦层的神经元有3200个
(2)将隐藏层加入模型
model.add(Dense(units=256, #共256个神经元
activation='relu' )) #激活函数为relu
model.add(Dropout(0.2)) # #加入dropout避免过度拟合
(3)将输出层加入模型
model.add(Dense(units=1, #输出层只有一个神经元
activation='sigmoid' )) #定义激活函数sigmoid
(4)查看模型摘要
1.2 训练模型
(1)定义训练方法
model.compile(loss='binary_crossentropy', #损失函数
optimizer='adam', #定义优化器
metrics=['accuracy']) #定义评估方式
(2)开始训练
train_history =model.fit(x_train, y_train,batch_size=100, #每批次100项
epochs=10,verbose=2, #训练周期为10,显示训练过程
validation_split=0.2) #训练集比例为80%(20000)训练,20%验证(25000*0.2=5000)

以上执行界面可知,共执行了10个训练周期,可以发现误差越来越小,准确率越来越高。
准确率:
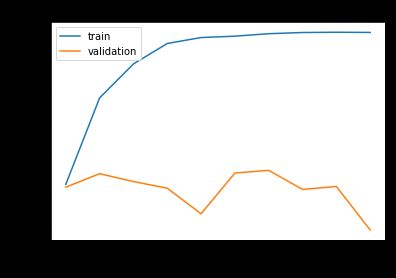
损失函数:

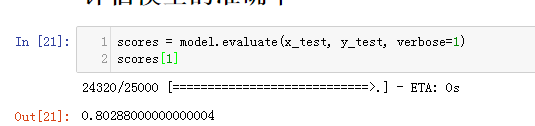
1.3 评估模型准确率
使用test测试
scores = model.evaluate(x_test, y_test, verbose=1)
scores[1]
1.4 进行预测
(1)执行预测
predict=model.predict_classes(x_test)
(2)查看预测结果
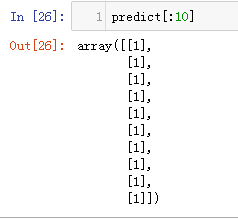
(3)使用一维数组查看预测结果
predict_classes=predict.reshape(-1)
predict_classes[:10]
结果:
1.5 查看测试集数据预测结果
(1)创建display_test_Sentiment函数
SentimentDict={1:'正面的',0:'负面的'}
def display_test_Sentiment(i):
print(test_text[i])
print('标签label:',SentimentDict[y_test[i]],
'预测结果:',SentimentDict[predict_classes[i]])
(2)显示预测结果
display_test_Sentiment(2)


1.6 使用较大字典提取更多文字
2000改为3800


2. RNN
使用simpleRNN建立16个神经元的RNN层
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import SimpleRNN
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=3800,
input_length=380))
model.add(Dropout(0.35))
model.add(SimpleRNN(units=16))
model.add(Dense(units=256,activation='relu' ))
model.add(Dropout(0.35))
model.add(Dense(units=1,activation='sigmoid' ))
model.summary()

3. LSTM
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation,Flatten
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
