TensorFlow 2.0深度学习算法实战---第8章Keras高层接口
人工智能难题不仅是计算机科学问题,更是数学、认知 科学和哲学问题。− François Chollet
Keras 是一个主要由 Python 语言开发的开源神经网络计算库,最初由 François Chollet编写,它被设计为高度模块化和易扩展的高层神经网络接口,使得用户可以不需要过多的专业知识就可以简洁、快速地完成模型的搭建与训练。Keras 库分为前端和后端,其中后端一般是调用现有的深度学习框架实现底层运算,如 Theano、CNTK、TensorFlow 等,前端接口是 Keras 抽象过的一组统一接口函数。用户通过 Keras 编写的代码可以轻松的切换不同的后端运行,灵活性较大。正是由于 Keras 的高度抽象和易用特性,截止到 2019 年,Keras 市场份额达到了 26.6%,增长 19.7%,在同类深度学习框架中仅次于 TensorFlow(数据来自 KDnuggets)。
TensorFlow 与 Keras 之间存在既竞争,又合作的交错关系,甚至连 Keras 创始人都在Google 工作。早在 2015 年 11 月,TensorFlow 就被加入 Keras 后端支持。从 2017 年开始,Keras 的大部分组件被整合到 TensorFlow 框架中。2019 年,在 TensorFlow 2 版本中,Keras被正式确定为 TensorFlow 的高层唯一接口 API,取代了 TensorFlow 1 版本中自带的tf.layers 等高层接口。也就是说,现在只能使用 Keras 的接口来完成 TensorFlow 层方式的模型搭建与训练。在 TensorFlow 中,Keras 被实现在 tf.keras子模块中。
Keras 与 tf.keras 有什么区别与联系呢?其实 Keras 可以理解为一套搭建与训练神经网络的高层 API 协议,Keras 本身已经实现了此协议,安装标准的 Keras 库就可以方便地调用TensorFlow、CNTK 等后端完成加速计算;在 TensorFlow 中,也实现了一套 Keras 协议,即 tf.keras,它与 TensorFlow 深度融合,且只能基于 TensorFlow 后端运算,并对TensorFlow 的支持更完美。对于使用 TensorFlow 的开发者来说,tf.keras 可以理解为一个普通的子模块,与其他子模块,如 tf.math,tf.data 等并没有什么差别。下文如无特别说明,Keras 均指代 tf.keras,而不是标准的 Keras 库。
8.1 常见功能模块
Keras 提供了一系列高层的神经网络相关类和函数,如经典数据集加载函数、网络层类、模型容器、损失函数类、优化器类、经典模型类等。
对于经典数据集,通过一行代码即可下载、管理、加载数据集,这些数据集包括Boston 房价预测数据集、CIFAR 图片数据集、MNIST/FashionMNIST 手写数字图片数据集、IMDB 文本数据集等。我们已经介绍过,不再敖述.
8.1.1 常见网络层类
对于常见的神经网络层,可以使用张量方式的底层接口函数来实现,这些接口函数一般在 tf.nn 模块中。更常用地,对于常见的网络层,我们一般直接使用层方式来完成模型的搭建,在 tf.keras.layers 命名空间(下文使用 layers 指代 tf.keras.layers)中提供了大量常见网络层的类,如全连接层、激活函数层、池化层、卷积层、循环神经网络层等。对于这些网络层类,只需要在创建时指定网络层的相关参数,并调用__call__方法即可完成前向计算。在调用__call__方法时,Keras 会自动调用每个层的前向传播逻辑,这些逻辑一般实现在类的call 函数中。
以 Softmax 层为例,它既可以使用 tf.nn.softmax 函数在前向传播逻辑中完成 Softmax运算,也可以通过 layers.Softmax(axis)类搭建 Softmax 网络层,其中 axis 参数指定进行softmax 运算的维度。首先导入相关的子模块,实现如下:
import tensorflow as tf
# 导入 keras 模型,不能使用 import keras,它导入的是标准的 Keras 库
from tensorflow import keras
from tensorflow.keras import layers # 导入常见网络层类
然后创建 Softmax 层,并调用__call__方法完成前向计算:
x = tf.constant([2.,1.,0.1]) # 创建输入张量
layer = layers.Softmax(axis=-1) # 创建 Softmax 层
out = layer(x) # 调用 softmax 前向计算,输出为 out
经过 Softmax 网络层后,得到概率分布 out 为:
<tf.Tensor: id=2, shape=(3,), dtype=float32, numpy=array([0.6590012,
0.242433 , 0.0985659], dtype=float32)>
当然,也可以直接通过 tf.nn.softmax()函数完成计算,代码如下:
out = tf.nn.softmax(x) # 调用 softmax 函数完成前向计算
8.1.2 网络容器
对于常见的网络,需要手动调用每一层的类实例完成前向传播运算,当网络层数变得较深时,这一部分代码显得非常臃肿。可以通过 Keras 提供的网络容器 Sequential将多个网络层封装成一个大网络模型,只需要调用网络模型的实例一次即可完成数据从第一层到最末层的顺序传播运算。
例如,2 层的全连接层加上单独的激活函数层,可以通过 Sequential 容器封装为一个网络。
# 导入 Sequential 容器
# 导入Sequential容器
from tensorflow.keras import layers,Sequential
network=Sequential([ #封装成一个网络
layers.Dense(3,activation=None),#全连接层,此处不使用激活函数
layers.ReLU(),#激活函数层
layers.Dense(2,activation=None),#全连接层,此处不使用激活函数
layers.ReLU() #激活函数层
])
x=tf.random.normal([4,3])
out=network(x)# 输入从第一层开始,逐层传播至输出层,并返回输出层的输出
print(out)
Sequential 容器也可以通过 add()方法继续追加新的网络层,实现动态创建网络的功能:
layers_num = 2 # 堆叠 2 次
network = Sequential([]) # 先创建空的网络容器
for _ in range(layers_num):
network.add(layers.Dense(3)) # 添加全连接层
network.add(layers.ReLU())# 添加激活函数层
network.build(input_shape=(4, 4)) # 创建网络参数
network.summary()
上述代码通过指定任意的 layers_num 参数即可创建对应层数的网络结构,在完成网络创建时,网络层类并没有创建内部权值张量等成员变量,此时通过调用类的 build 方法并指定输入大小,即可自动创建所有层的内部张量。通过 summary()函数可以方便打印出网络结构和参数量,打印结果如下:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) multiple 15
_________________________________________________________________
re_lu_2 (ReLU) multiple 0
_________________________________________________________________
dense_3 (Dense) multiple 12
_________________________________________________________________
re_lu_3 (ReLU) multiple 0
=================================================================
Total params: 27
Trainable params: 27
Non-trainable params: 0
_________________________________________________________________
可以看到 Layer 列为每层的名字,这个名字由 TensorFlow 内部维护,与 Python 的对象名并不一样。Param#列为层的参数个数,Total params 项统计出了总的参数量,Trainable params为总的待优化参数量,Non-trainable params为总的不需要优化的参数量。读者可以简单验证一下参数量的计算结果。
当我们通过 Sequential 容量封装多个网络层时,每层的参数列表将会自动并入Sequential 容器的参数列表中,不需要人为合并网络参数列表,这也是 Sequential 容器的便捷之处。Sequential 对象的 trainable_variables 和 variables 包含了所有层的待优化张量列表和全部张量列表,例如:
# 打印网络的待优化参数名与 shape
for p in network.trainable_variables:
print(p.name, p.shape) # 参数名和形状
dense_2/kernel:0 (4, 3)
dense_2/bias:0 (3,)
dense_3/kernel:0 (3, 3)
dense_3/bias:0 (3,)
Sequential 容器是最常用的类之一,对于快速搭建多层神经网络非常有用,应尽量多使用来简化网络模型的实现。
8.2 模型装配、训练与测试
在训练网络时,一般的流程是通过前向计算获得网络的输出值,再通过损失函数计算网络误差,然后通过自动求导工具计算梯度并更新,同时间隔性地测试网络的性能。对于这种常用的训练逻辑,可以直接通过 Keras 提供的模型装配与训练等高层接口实现,简洁清晰。
8.2.1 模型装配
在 Keras 中,有 2 个比较特殊的类:keras.Model 和 keras.layers.Layer 类。其中 Layer类是网络层的母类,定义了网络层的一些常见功能,如添加权值、管理权值列表等。
Model 类是网络的母类,除了具有 Layer 类的功能,还添加了保存模型、加载模型、训练与测试模型等便捷功能。Sequential 也是 Model 的子类,因此具有 Model 类的所有功能。
接下来介绍 Model 及其子类的模型装配与训练功能。我们以 Sequential 容器封装的网络为例,首先创建 5 层的全连接网络,用于 MNIST 手写数字图片识别,代码如下:
# 创建 5 层的全连接网络
network = Sequential([layers.Flatten(input_shape=(28,28)),
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
#network.build(input_shape=(4,28,28))
print(network.summary())
创建网络后,正常的流程是循环迭代数据集多个 Epoch,每次按批产生训练数据、前向计算,然后通过损失函数计算误差值,并反向传播自动计算梯度、更新网络参数。这一部分逻辑由于非常通用,在 Keras 中提供了 compile()和 fit()函数方便实现上述逻辑。首先通过compile 函数指定网络使用的优化器对象、损失函数类型,评价指标等设定,这一步称为装配。例如:
#导入优化器,损失函数模块
from tensorflow.keras import optimizers,losses
#模型装配
# 采用Adam优化器,学习率为0.01;采用交叉熵损失函数,包含softmax
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'] #设置测量指标为准确率
)
在 compile()函数中指定的优化器、损失函数等参数也是我们自行训练时需要设置的参数,并没有什么特别之处,只不过 Keras 将这部分常用逻辑内部实现了,提高开发效率。
8.2.2 模型训练
模型装配完成后,即可通过 fit()函数送入待训练的数据集和验证用的数据集,这一步称为模型训练。例如:
def preprocess(x, y):
# [b, 28, 28], [b]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
from tensorflow.keras import datasets
(x, y), (x_test, y_test) = datasets.mnist.load_data() #(6000,28,28) (1000,28,28)
#batchsz = 512
train_db = tf.data.Dataset.from_tensor_slices((x, y))
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.shuffle(1000).map(preprocess).batch(512)
# 指定训练集为 train_db,验证集为 val_db,训练 5 个 epochs,每 2 个 epoch 验证一次
# 返回训练轨迹信息保存在 history 对象中
history = network.fit(train_db, epochs=5, validation_data=val_db,
validation_freq=2)
其中 train_db 为 tf.data.Dataset 对象,也可以传入 Numpy Array 类型的数据;epochs 参数指定训练迭代的 Epoch 数量;validation_data 参数指定用于验证(测试)的数据集和验证的频率validation_freq。
运行上述代码即可实现网络的训练与验证的功能,fit 函数会返回训练过程的数据记录history,其中 history.history 为字典对象,包含了训练过程中的 loss、测量指标等记录项,我们可以直接查看这些训练数据,例如:
history.history # 打印训练记录
# 历史训练准确率
{'accuracy': [0.00011666667, 0.0, 0.0, 0.010666667, 0.02495],
'loss': [2465719710540.5845, # 历史训练误差
78167808898516.03,
404488834518159.6,
1049151145155144.4,
1969370184858451.0],
'val_accuracy': [0.0, 0.0], # 历史验证准确率
# 历史验证误差
'val_loss': [197178788071657.3, 1506234836955706.2]}
fit()函数的运行代表了网络的训练过程,因此会消耗相当的训练时间,并在训练结束后才返回,训练中产生的历史数据可以通过返回值对象取得。可以看到通过 compile&fit 方式实现的代码非常简洁和高效,大大缩减了开发时间。但是因为接口非常高层,灵活性也降低了,是否使用需要用户自行判断。
8.2.3 模型测试
Model 基类除了可以便捷地完成网络的装配与训练、验证,还可以非常方便的预测和测试。关于验证和测试的区别,我们会在过拟合一章详细阐述,此处可以将验证和测试理解为模型评估的一种方式。
通过 Model.predict(x)方法即可完成模型的预测,例如:
# 加载一个 batch 的测试数据
x,y = next(iter(test_db))
print('predict x:', x.shape) # 打印当前 batch 的形状
out = network.predict(x) # 模型预测,预测结果保存在 out 中
print(out)
其中 out 即为网络的输出。通过上述代码即可使用训练好的模型去预测新样本的标签信息。
如果只是简单的测试模型的性能,可以通过 Model.evaluate(db)循环测试完 db 数据集上所有样本,并打印出性能指标,第一个指标代表loss,第二个指标代表accuracy。例如:
network.evaluate(test_db) # 模型测试,测试在 db_test 上的性能表现
[0.12344565894454718, 0.9658]
8.3 模型保存与加载
模型训练完成后,需要将模型保存到文件系统上,从而方便后续的模型测试与部署工作。实际上,在训练时间隔性地保存模型状态也是非常好的习惯,这一点对于训练大规模的网络尤其重要。一般大规模的网络需要训练数天乃至数周的时长,一旦训练过程被中断或者发生宕机等意外,之前训练的进度将全部丢失。如果能够间断地保存模型状态到文件系统,即使发生宕机等意外,也可以从最近一次的网络状态文件中恢复,从而避免浪费大量的训练时间和计算资源。因此模型的保存与加载非常重要。
在 Keras 中,有三种常用的模型保存与加载方法。
8.3.1 张量方式
网络的状态主要体现在网络的结构以及网络层内部张量数据上,因此在拥有网络结构源文件的条件下,直接保存网络张量参数到文件系统上是最轻量级的一种方式。我们以MNIST 手写数字图片识别模型为例,通过调用 Model.save_weights(path)方法即可将当前的网络参数保存到 path 文件上,代码如下:
bakup_network = network
# 保存模型参数到文件上
network.save_weights('weights.ckpt')
上述代码将 network 模型保存到 weights.ckpt 文件上。在需要的时候,先创建好网络对象,然后调用网络对象的 load_weights(path)方法即可将指定的模型文件中保存的张量数值写入到当前网络参数中去,例如:
# 保存模型参数到文件上
network.save_weights('weights.ckpt')
print('saved weights.')
del network # 删除网络对象
# 重新创建相同的网络结构
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
# 从参数文件中读取数据并写入当前网络
network.load_weights('weights.ckpt')
print('loaded weights!')
这种保存与加载网络的方式最为轻量级,文件中保存的仅仅是张量参数的数值,并没有其它额外的结构参数。但是它需要使用相同的网络结构才能够正确恢复网络状态,因此一般在拥有网络源文件的情况下使用。
8.3.2 网络方式
我们来介绍一种不需要网络源文件,仅仅需要模型参数文件即可恢复出网络模型的方法。通过 Model.save(path)函数可以将模型的结构以及模型的参数保存到 path 文件上,在不需要网络源文件的条件下,通过 keras.models.load_model(path)即可恢复网络结构和网络参数。
首先将 MNIST 手写数字图片识别模型保存到文件上,并且删除网络对象:
# 保存模型结构与模型参数到文件
network.save('model.h5')
print('saved total model.')
del network # 删除网络对象
此时通过 model.h5 文件即可恢复出网络的结构和状态,不需要提前创建网络对象,代码如下:
# 从文件恢复网络结构与网络参数
network = keras.models.load_model('model.h5')
可以看到,model.h5 文件除了保存了模型参数外,还应保存了网络结构信息,不需要提前创建模型即可直接从文件中恢复出网络 network 对象。
8.3.3 SavedModel 方式
TensorFlow 之所以能够被业界青睐,除了优秀的神经网络层 API 支持之外,还得益于它强大的生态系统,包括移动端和网页端等的支持。当需要将模型部署到其他平台时,采用 TensorFlow 提出的 SavedModel 方式更具有平台无关性。
通过 tf.saved_model.save (network, path)即可将模型以 SavedModel 方式保存到 path 目录中,代码如下:
# 保存模型结构与模型参数到文件
tf.saved_model.save(network, 'model-savedmodel')
print('saving savedmodel.')
del network # 删除网络对象
此时在文件系统 model-savedmodel 目录上出现了如下网络文件,如图 8.1 所示:
用户无需关心文件的保存格式,只需要通过 tf.saved_model.load 函数即可恢复出模型对象,我们在恢复出模型实例后,完成测试准确率的计算,实现如下:
print('load savedmodel from file.')
# 从文件恢复网络结构与网络参数
network = tf.saved_model.load('model-savedmodel')
# 准确率计量器
acc_meter = tf.metrics.CategoricalAccuracy()
for x,y in test_db: # 遍历测试集
pred = network(x) # 前向计算
acc_meter.update_state(y_true=y, y_pred=pred) # 更新准确率统计
# 打印准确率
print("Test Accuracy:%f" % acc_meter.result())
8.4.1 自定义网络层
对于自定义的网络层,至少需要实现初始化__init__方法和前向传播逻辑 call 方法。我们以某个具体的自定义网络层为例,假设需要一个没有偏置向量的全连接层,即 bias 为0,同时固定激活函数为 ReLU 函数。尽管这可以通过标准的 Dense 层创建,但我们还是通过实现这个“特别的”网络层类来阐述如何实现自定义网络层。
首先创建类,并继承自 Layer 基类。创建初始化方法,并调用母类的初始化函数,由于是全连接层,因此需要设置两个参数:输入特征的长度 inp_dim 和输出特征的长度outp_dim,并通过 self.add_variable(name, shape)创建 shape 大小,名字为 name 的张量,并设置为需要优化。代码如下:
class MyDense(layers.Layer):
# 自定义网络层
def __init__(self,inp_dim,outp_dim):
super(MyDense,self).__init__()
#创建权值张量并添加到类管理列表中,设置为需要优化
self.add_variable('w',[inp_dim,outp_dim],trainable=True)
需要注意的是,self.add_variable 会返回张量的 Python 引用,而变量名 name 由TensorFlow 内部维护,使用的比较少。我们实例化 MyDense 类,并查看其参数列表,例如:
net = MyDense(4,3) # 创建输入为 4,输出为 3 节点的自定义层
net.variables,net.trainable_variables # 查看自定义层的参数列表
# 类的全部参数列表
[<tf.Variable 'w:0' shape=(4, 3) dtype=float32, numpy=
array([[ 0.6118245 , -0.61598533, -0.35566133],
[ 0.2789786 , -0.03844213, -0.11899394],
[-0.01769835, 0.28213632, -0.922646 ],
[ 0.18603265, 0.65625775, 0.2696042 ]], dtype=float32)>]
# 类的待优化参数列表
[<tf.Variable 'w:0' shape=(4, 3) dtype=float32, numpy=
array([[ 0.6118245 , -0.61598533, -0.35566133],
[ 0.2789786 , -0.03844213, -0.11899394],
[-0.01769835, 0.28213632, -0.922646 ],
[ 0.18603265, 0.65625775, 0.2696042 ]], dtype=float32)>]…
可以看到张量被自动纳入类的参数列表。
通过修改为self.kernel = self.add_variable('w', [inp_dim, outp_dim], trainable=False),我们可以设置张量不需要被优化,此时再来观测张量的管理状态:
class MyDense(layers.Layer):
# 自定义网络层
def __init__(self, inp_dim, outp_dim):
super(MyDense, self).__init__()
# 创建权值张量并添加到类管理列表中,设置为需要优化
self.kernel = self.add_variable('w', [inp_dim, outp_dim],trainable=False)
# 创建输入为 4,输出为 3 节点的自定义层
net = MyDense(4,3)
# 查看自定义层的参数列表
net.variables,net.trainable_variables
# 类的全部参数列表
[<tf.Variable 'Variable:0' shape=(4, 3) dtype=float32, numpy=
array([[ 0.02653543, -0.91281503, 1.0557984 ],
[-0.6090471 , -0.09816596, 2.015274 ],
[ 0.06185807, 0.3806991 , 1.3561277 ],
[-0.04293933, -0.27208307, -1.1275163 ]], dtype=float32)>]
# 类的待优化参数列表
[]
可以看到,此时张量并不会被 trainable_variables 管理。此外,类初始化中创建为 tf.Variable类型的类成员变量也会自动纳入张量管理中,例如:
# 通过 tf.Variable 创建的类成员也会自动加入类参数列表
self.kernel = tf.Variable(tf.random.normal([inp_dim, outp_dim]),trainable=False)
打印出管理的张量列表如下:
class MyDense(layers.Layer):
# 自定义网络层
def __init__(self, inp_dim, outp_dim):
super(MyDense, self).__init__()
# 创建权值张量并添加到类管理列表中,设置为需要优化
self.kernel = tf.Variable('w', [inp_dim, outp_dim],trainable=False)
# 创建输入为 4,输出为 3 节点的自定义层
net = MyDense(4,3)
# 查看自定义层的参数列表
net.variables,net.trainable_variables
# 类的全部参数列表
[<tf.Variable 'Variable:0' shape=(4, 3) dtype=float32, numpy=
array([[ 0.02653543, -0.91281503, 1.0557984 ],
[-0.6090471 , -0.09816596, 2.015274 ],
[ 0.06185807, 0.3806991 , 1.3561277 ],
[-0.04293933, -0.27208307, -1.1275163 ]], dtype=float32)>]
# 类的待优化参数列表
[]
完成自定义类的初始化工作后,我们来设计自定义类的前向运算逻辑,对于这个例子,只需要完成 = @矩阵运算,并通过固定的 ReLU 激活函数即可,代码如下:
class MyDense(layers.Layer):
# 自定义网络层
def __init__(self, inp_dim, outp_dim):
super(MyDense, self).__init__()
# 创建权值张量并添加到类管理列表中,设置为需要优化
self.kernel = self.add_weight('w', [inp_dim, outp_dim], trainable=True)
def call(self, inputs, training=None):
# 实现自定义类的前向计算逻辑
# X@W
out = inputs @ self.kernel
# 执行激活函数运算
out = tf.nn.relu(out)
return out
如上所示,自定义类的前向运算逻辑实现在 call(inputs, training=None)函数中,其中 inputs代表输入,由用户在调用时传入;training 参数用于指定模型的状态:training 为 True 时执行训练模式,training 为 False 时执行测试模式,默认参数为 None,即测试模式。由于全连接层的训练模式和测试模式逻辑一致,此处不需要额外处理。对于部分测试模式和训练模式不一致的网络层,需要根据 training 参数来设计需要执行的逻辑。
8.4.2 自定义网络
在完成了自定义的全连接层类实现之后,我们基于上述的“无偏置的全连接层”来实现 MNIST 手写数字图片模型的创建。
自定义网络类可以和其他标准类一样,通过 Sequential 容器方便地封装成一个网络模型:
from tensorflow.keras import Sequential
network=Sequential([
MyDense(784,256),#使用自定义的层
MyDense(256,128),
MyDense(128,64),
MyDense(64,32),
MyDense(32,10)
])
network.build(input_shape=(None,28*28))
print(network.summary())
可以看到,通过堆叠我们的自定义网络层类,一样可以实现 5 层的全连接层网络,每层全连接层无偏置张量,同时激活函数固定地使用 ReLU 函数。
Sequential 容器适合于数据按序从第一层传播到第二层,再从第二层传播到第三层,以此规律传播的网络模型。对于复杂的网络结构,例如第三层的输入不仅是第二层的输出,还有第一层的输出,此时使用自定义网络更加灵活。下面我们来创建自定义网络类,首先创建类,并继承自 Model 基类,分别创建对应的网络层对象,代码如下:
class MyModel(keras.Model):
# 自定义网络类,继承自Model基类
def __init__(self):
super(MyModel,self).__init__()
#完成网络内需要的网络层的创建工作
self.fc1=MyDense(28*28,256)
self.fc2=MyDense(256,128)
self.fc3=MyDense(128,64)
self.fc4=MyDense(64,32)
self.fc5=MyDense(32,10)
然后实现自定义网络的前向运算逻辑,代码如下:
def call(self,inputs,training=None):
x=self.fc1(inputs)
x=self.fc2(x)
x=self.fc3(x)
x=self.fc4(x)
x=self.fc5(x)
return x
这个例子可以直接使用第一种方式,即 Sequential 容器包裹实现。但自定义网络的前向计算逻辑可以自由定义,更为通用,我们会在卷积神经网络一章看到自定义网络的优越性。
基于以上内容,我们来总结下代码:
from tensorflow.keras import datasets,Sequential,optimizers,losses
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
def preprocess(x,y):
x=tf.cast(x,dtype=tf.float32)/255.
y=tf.cast(y,tf.int32)
y=tf.one_hot(y,depth=10)
return x,y
def load_dataset():
(x,y),(x_test,y_test)=datasets.mnist.load_data()
batchsz=512
train_db=tf.data.Dataset.from_tensor_slices((x,y))
train_db=train_db.shuffle(1000).map(preprocess).batch(batchsz)
test_db=tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db=test_db.shuffle(1000).map(preprocess).batch(batchsz)
return train_db,test_db
def build_network():
# 创建5层的全连接网络
network=Sequential([
layers.Flatten(input_shape=(28,28)),
layers.Dense(256,activation='relu'),
layers.Dense(128,activation='relu'),
layers.Dense(64,activation='relu'),
layers.Dense(32,activation='relu'),
layers.Dense(10)
])
network.summary()
"""
模型装配:
采用Adam优化器,学习率为0.01;
采用交叉熵损失函数,包含softmax
from_logits=False:output经过softmax输出的概率值
from_logits=True:output经过网络直接输出的logits张量
"""
network.compile(optimizer=optimizers.Adam(learning_rate=0.01),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'] #设置测量指标为准确率
)
return network
def train(network,train_db,test_db,epochs=5):
history=network.fit(train_db,epochs=epochs,validation_data=test_db,
validation_freq=2)
#print(history.history)
return network,history
def test_one_data(network,test_db):
x,y=next(iter(test_db))
print('predict x:',x.shape)
out=network.predict(x)
print(out)
def test_model(network,test_db):
network.evaluate(test_db)
def picture(epochs,history):
x = range(epochs)
plt.figure(figsize=(10, 6))
plt.subplots_adjust(wspace=0.5)
plt.subplot(1, 2, 1)
# 绘制MES曲线
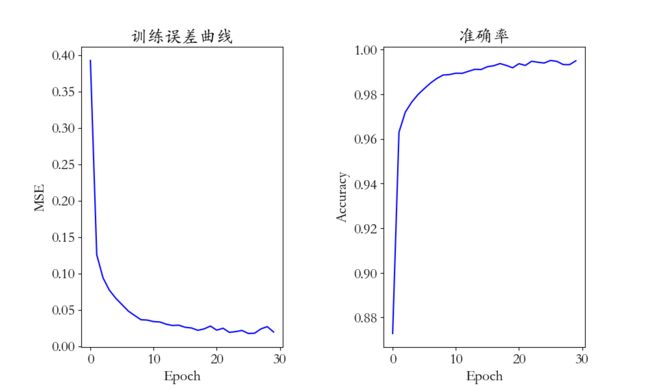
plt.title('训练误差曲线')
plt.plot(x, history.history['loss'], color='blue')
plt.xlabel('Epoch')
plt.ylabel('MSE')
plt.show()
# 绘制Accuracy曲线
plt.subplot(1, 2, 2)
plt.title('准确率')
plt.plot(x, history.history['accuracy'], color='blue')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
plt.savefig('model_energy.svg')
plt.close()
def main():
epochs=30
train_db,test_db=load_dataset()
network=build_network()
network,history=train(network,train_db,test_db,epochs)
test_one_data(network,test_db)
test_model(network,test_db)
picture(epochs,history)
if __name__=="__main__":
main()
看一下loss和Accuracy.
8.5 模型乐园
对于常用的网络模型,如 ResNet、VGG 等,不需要手动创建网络,可以直接从keras.applications子模块中通过一行代码即可创建并使用这些经典模型,同时还可以通过设置 weights 参数加载预训练的网络参数,非常方便。
8.5.1 加载模型
以 ResNet50 网络模型为例,一般将 ResNet50 去除最后一层后的网络作为新任务的特征提取子网络,即利用在 ImageNet 数据集上预训练好的网络参数初始化,并根据自定义任务的类别追加一个对应数据类别数的全连接分类层或子网络,从而可以在预训练网络的基础上快速、高效地学习新任务。
首先利用 Keras 模型乐园加载 ImageNet 预训练好的 ResNet50 网络,代码如下:
# 加载ImageNet预训练网络模型,并却掉最后一层
resnet=keras.applications.ResNet50(weights='imagenet',include_top=False)
resnet.summary()
# 测试网络的输出
x=tf.random.normal([4,224,224,3])
out=resnet(x) #获得子网络的输出
out.shape
TensorShape([4, 7, 7, 2048])
上述代码自动从服务器下载模型结构和在 ImageNet 数据集上预训练好的网络参数。通过设置 include_top 参数为 False,可以选择去掉 ResNet50 最后一层,此时网络的输出特征图大小为[, 7,7,2048]。对于某个具体的任务,需要设置自定义的输出节点数,以 100 类的分类任务为例,我们在 ResNet50 基础上重新构建新网络。新建一个池化层(这里的池化层暂时可以理解为高、宽维度下采样的功能),将特征从[, 7,7,2048]降维到[, 2048]。代码如下:
from tensorflow.keras import layers
# 新建池化层
global_average_layer=layers.GlobalAveragePooling2D()
# 利用上一层的输出作为本层的额输入,测试其输出
x=tf.random.normal([4,7,7,2048])
# 池化层降维,形状由[4,7,7,2048]变为[4,1,1,2048],删减维度后变为[4,2048]
out=global_average_layer(x)
out.shape
TensorShape([4, 2048])
最后新建一个全连接层,并设置输出节点数为 100,代码如下:
#新建全连接层
fc=layers.Dense(100)
# 利用上一层的输出[4,2048]作为本层的输入,测试其输出
x=tf.random.normal([4,2048])
out=fc(x) #输出层的输出为样本属于100分类的概率分布
out.shape
TensorShape([4, 100])
在创建预训练的 ResNet50 特征子网络、新建的池化层和全连接层后,我们重新利用Sequential 容器封装成一个新的网络:
# 重新包裹成我们的网络模型
from tensorflow.keras import Sequential
mynet=Sequential([resnet,global_average_layer,fc])
mynet.summary()
可以看到新的网络模型的结构信息为:
Layer (type) Output Shape Param #
=================================================================
resnet50 (Model) (None, None, None, 2048) 23587712
_________________________________________________________________
global_average_pooling2d (Gl (None, 2048) 0
_________________________________________________________________
dense_4 (Dense) (None, 100) 204900
=================================================================
Total params: 23,792,612
Trainable params: 23,739,492
Non-trainable params: 53,120
通过设置 resnet.trainable = False 可以选择冻结 ResNet 部分的网络参数,只训练新建的网络层,从而快速、高效完成网络模型的训练。当然也可以在自定义任务上更新网络的全部参数。
8.6 测量工具
在网络的训练过程中,经常需要统计准确率、召回率等测量指标,除了可以通过手动计算的方式获取这些统计数据外,Keras 提供了一些常用的测量工具,位于 keras.metrics 模块中,专门用于统计训练过程中常用的指标数据。
Keras 的测量工具的使用方法一般有 4 个主要步骤:新建测量器,写入数据,读取统计数据和清零测量器。
8.6.1 新建测量器
在 keras.metrics 模块中,提供了较多的常用测量器类,如统计平均值的 Mean 类,统计准确率的 Accuracy 类,统计余弦相似度的 CosineSimilarity 类等。下面我们以统计误差值为例。在前向运算时,我们会得到每一个 Batch 的平均误差,但是我们希望统计每个Step 的平均误差,因此选择使用 Mean 测量器。新建一个平均测量器,代码如下:
# 新建平均测量器,适合 Loss 数据
loss_meter = metrics.Mean()
8.6.2 写入数据
通过测量器的 update_state 函数可以写入新的数据,测量器会根据自身逻辑记录并处理采样数据。例如,在每个 Step 结束时采集一次 loss 值,代码如下:
# 记录采样的数据,通过 float()函数将张量转换为普通数值
loss_meter.update_state(float(loss))
上述采样代码放置在每个 Batch 运算结束后,测量器会自动根据采样的数据来统计平均值。
8.6.3 读取统计信息
在采样多次数据后,可以选择在需要的地方调用测量器的 result()函数,来获取统计值。例如,间隔性统计 loss 均值,代码如下:
# 打印统计期间的平均 loss
print(step, 'loss:', loss_meter.result())
8.6.4 清除状态
由于测量器会统计所有历史记录的数据,因此在启动新一轮统计时,有必要清除历史状态。通过 reset_states()即可实现清除状态功能。例如,在每次读取完平均误差后,清零统计信息,以便下一轮统计的开始,代码如下:
if step % 100 == 0:
# 打印统计的平均 loss
print(step, 'loss:', loss_meter.result())
loss_meter.reset_states() # 打印完后,清零测量器
8.6.5 准确率统计实战
按照测量工具的使用方法,我们利用准确率测量器 Accuracy 类来统计训练过程中的准确率。首先新建准确率测量器,代码如下:
acc_meter = metrics.Accuracy() # 创建准确率测量器
在每次前向计算完成后,记录训练准确率数据。需要注意的是,Accuracy 类的 update_state函数的参数为预测值和真实值,而不是当前 Batch 的准确率。我们将当前 Batch 样本的标签和预测结果写入测量器,代码如下:
network = Sequential([
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
x=tf.random.normal([4,784])
y=[6,6,8,2]
acc_meter=metrics.Accuracy()#创建准确率测量器
#[b,784]=>[b,10],网路输出值
out=network(x)
# [b,10]=>[b],经过argmax 后计算预测值
pred=tf.argmax(out,axis=1)
pred=tf.cast(pred,dtype=tf.int32)
# 根据预测值与真实值写入测量器
acc_meter.update_state(y,pred)
在统计完测试集所有 Batch 的预测值后,打印统计的平均准确率,并清零测量器,代码如下:
# 读取统计结果
print(step, 'Evaluate Acc:', acc_meter.result().numpy())
acc_meter.reset_states() # 清零测量器
8.7 可视化
在网络训练的过程中,通过 Web 端远程监控网络的训练进度,可视化网络的训练结果,对于提高开发效率和实现远程监控是非常重要的。TensorFlow 提供了一个专门的可视化工具,叫做 TensorBoard,它通过 TensorFlow 将监控数据写入到文件系统,并利用 Web后端监控对应的文件目录,从而可以允许用户从远程查看网络的监控数据。
TensorBoard 的使用需要模型代码和浏览器相互配合。在使用 TensorBoard 之前,需要安装 TensorBoard 库,安装命令如下:
# 安装 TensorBoard
pip install tensorboard
接下来我们分模型端和浏览器端介绍如何使用 TensorBoard 工具监控网络训练进度。
8.7.1 模型端
在模型端,需要创建写入监控数据的 Summary 类,并在需要的时候写入监控数据。首先通过 tf.summary.create_file_writer创建监控对象类实例,并指定监控数据的写入目录,代码如下:
# 创建监控类,监控数据将写入 log_dir 目录
summary_writer = tf.summary.create_file_writer(log_dir)
我们以监控误差数据和可视化图片数据为例,介绍如何写入监控数据。在前向计算完成后,对于误差这种标量数据,我们通过 tf.summary.scalar 函数记录监控数据,并指定时间戳 step 参数。这里的 step 参数类似于每个数据对应的时间刻度信息,也可以理解为数据曲线的坐标,因此不宜重复。每类数据通过字符串名字来区分,同类的数据需要写入相同名字的数据库中。例如:
with summary_writer.as_default(): # 写入环境
# 当前时间戳 step 上的数据为 loss,写入到名为 train-loss 数据库中
tf.summary.scalar('train-loss', float(loss), step=step)
TensorBoard 通过字符串 ID 来区分不同类别的监控数据,因此对于误差数据,我们将它命名为”train-loss”,其它类别的数据不可写入,防止造成数据污染。
对于图片类型的数据,可以通过 tf.summary.image 函数写入监控图片数据。例如,在训练时,可以通过 tf.summary.image 函数可视化样本图片。由于 TensorFlow 中的张量一般包含了多个样本,因此 tf.summary.image函数接受多个图片的张量数据,并通过设置max_outputs 参数来选择最多显示的图片数量,代码如下:
with summary_writer.as_default():
# 写入环境
#写入测试准确率
tf.summary.scalar('testacc',float(total_correct/total),step=step=)
# 可视化测试用的图片,设置最多可视化9张图片
tf.summary.image('val-onebyone-images:',val_images,max_outputs=9,step=step=)
运行模型程序,相应的数据将实时写入到指定文件目录中。
8.7.2 浏览器端
在运行程序时,监控数据被写入到指定文件目录中。如果要实时远程查看、可视化这些数据,还需要借助于浏览器和 Web 后端。首先是打开 Web 后端,通过在 cmd 终端运行tensorboard --logdir path指定 Web 后端监控的文件目录 path,即可打开 Web 后端监控进程,如图 8.2 所示:
此时打开浏览器,并输入网址 http://localhost:6006 (也可以通过 IP 地址远程访问,具体端口号可能会变动,可查看命令提示) 即可监控网络训练进度。TensorBoard 可以同时显示多条监控记录,在监控页面的左侧可以选择监控记录,如图 8.3 所示:
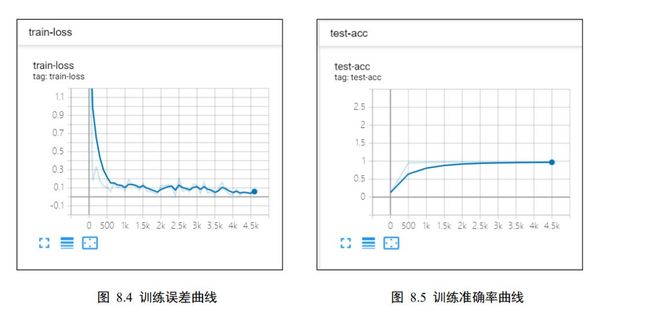
在监控页面的上端可以选择不同类型数据的监控页面,比如标量监控页面SCALARS、图片可视化页面 IMAGES 等。对于这个例子,我们需要监控的训练误差和测试准确率为标量类型数据,它的曲线在 SCALARS 页面可以查看,如图 8.4、图 8.5 所示。
在 IMAGES 页面,可以查看每个 Step 的图片可视化效果,如图 8.6 所示。

除了监控标量数据和图片数据外,TensorBoard 还支持通过 tf.summary.histogram 查看张量数据的直方图分布,以及通过 tf.summary.text打印文本信息等功能。例如:
with summary_writer.as_default():
# 当前时间戳 step 上的数据为 loss,写入到 ID 位 train-loss 对象中
tf.summary.scalar('train-loss', float(loss), step=step)
# 可视化真实标签的直方图分布
tf.summary.histogram('y-hist',y, step=step)
# 查看文本信息
tf.summary.text('loss-text',str(float(loss)))
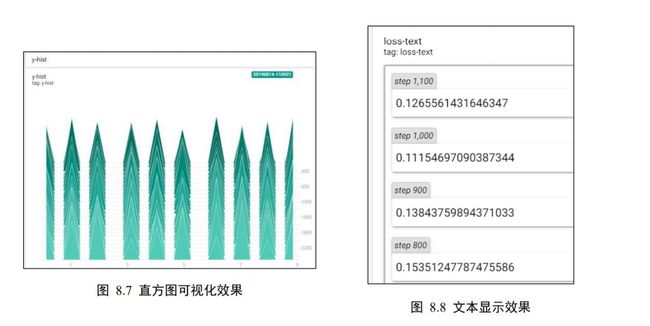
在 HISTOGRAMS 页面即可查看张量的直方图,如图 8.7 所示,在 TEXT 页面可以查看文本信息,如图 8.8 所示。
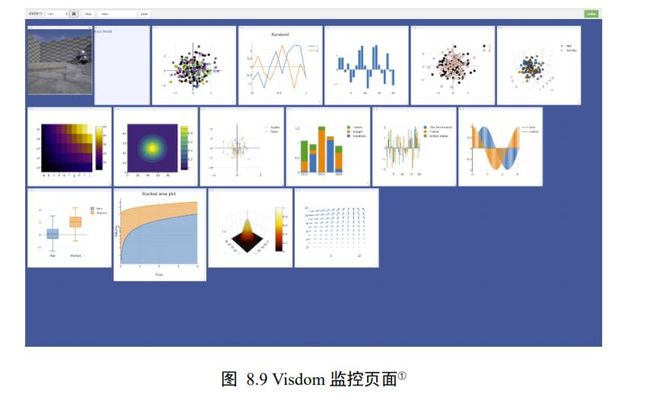
实际上,除了 TensorBoard 工具可以无缝监控 TensorFlow 的模型数据外,Facebook 开发的 Visdom 工具同样可以方便可视化数据,并且支持的可视化方式丰富,实时性高,使用起来较为方便。图 8.9 展示了 Visdom 数据的可视化方式。Visdom 可以直接接受PyTorch 的张量类型的数据,但不能直接接受 TensorFlow 的张量类型数据,需要转换为Numpy 数组。对于追求丰富可视化手段和实时性监控的读者,Visdom 可能是更好的选择。
参考文章
1.https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book/tree/master/ch08