Tensorflow 2.0卷积神经网络cifar-10数据集图像分类
Tensorflow 2.0卷积神经网络cifar-10数据集图像分类
- 1、cifar 10 数据集简介
- 2、数据导入
- 3、CNN模型搭建
- 4、模型编译训练
- 5、模型评估及预测
- 6、拓展学习之独立热编码实现
1、cifar 10 数据集简介
cifar 10相比于MNIST数据集而言更为复杂,其拥有10个种类**(猫、飞机、汽车、鸟、鹿、狗、青蛙、马、船、卡车)**,这十大类共同组成了50000的训练集,10000的测试集,每一张图片都是32*32的3通道图片(彩色图片),在神经网络中,通常表示成如下形式:
[b , w, h, c] = [b, 32 ,32, 3]
下面给出一些cifar 10 中的部分图片。我们可以看出,32*32尺寸的彩色图片是不够清晰的,所以相比于MNIST数据集,cifar 10 数据集更为复杂,但利用卷积神经网络进行计算的话,准确率大概是全连接层的两倍,这就是为什么卷积神经网络比全连接网络更受欢迎的原因。


2、数据导入
方法一:使用如下代码就可以直接导入
import tensorflow as tf
(x, y), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib notebook
# plt.imshow(x[1]) #显示第一张图片
x = x/255 #归一化
x_test = x_test/255
方法二:从官网下载
手动下载cifar10数据集集成到tensorflow.keras下载地址为点击下载,将下载的压缩文件夹放入C:\Users\用户名.keras\datasets(请勿解压),但tensorflow.keras识别的文件名,不是下载的文件名,所以需要修改文件名:cifar-10-python.tar.gz 更改为 cifar-10-batches-py.tar.gz
3、CNN模型搭建
常规的卷积层+池化层
"""模型搭建"""
model = tf.keras.Sequential([
tf.keras.Input(shape=(32,32,3)),
tf.keras.layers.Conv2D(filters=32 ,kernel_size=3 , padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2),strides=(2,2)),
tf.keras.layers.Conv2D(filters=64 ,kernel_size=3 , padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2),strides=(2,2)),
tf.keras.layers.Conv2D(filters=32 ,kernel_size=3 , padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2),strides=(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()

4、模型编译训练
"""模型编译"""
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001),
loss = tf.keras.losses.sparse_categorical_crossentropy,
metrics = ['acc']
)
"""模型训练"""
batches = 50
batch_size = 20000
data = []
for i in range(batches):
index=np.random.choice(x.shape[0],batch_size,replace=False)
x_batch = x[index]
y_batch = y[index]
history = model.fit(x_batch,y_batch, batch_size=1000, validation_split=0.2)# 训练
hist = pd.DataFrame(history.history)
data.append(hist)
df = pd.concat(data).reset_index(drop=True) # 竖着合并

画图
def plot_history(hist):
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.xlabel('Epoch')
plt.plot(hist['loss'],
label='loss')
plt.plot( hist['val_loss'],
label='val_loss')
plt.legend()
plt.subplot(1,2,2)
plt.xlabel('Epoch')
plt.plot( hist['acc'],
label = 'acc',color = 'red')
plt.plot( hist['val_acc'],
label = 'val_acc')
plt.legend()
plot_history(df)

5、模型评估及预测
"""模型评估"""
model.evaluate(x_test, y_test, verbose=2)
"""模型预测"""
prediction = model.predict(x_test)
class_names = ['飞机','汽车','鸟','猫','鹿','狗','青蛙','马','船','卡车']
for i in range(25):
pre = class_names[np.argmax(prediction[i])]
tar = class_names[y_test[i][0]]
print("预测:%s 实际:%s" % (pre, tar))

可视化显示
plt.rcParams['font.sans-serif']=['Arial Unicode MS'] #显示中文字体,这段代码我可是找了好长时间
plt.rcParams['axes.unicode_minus']=False
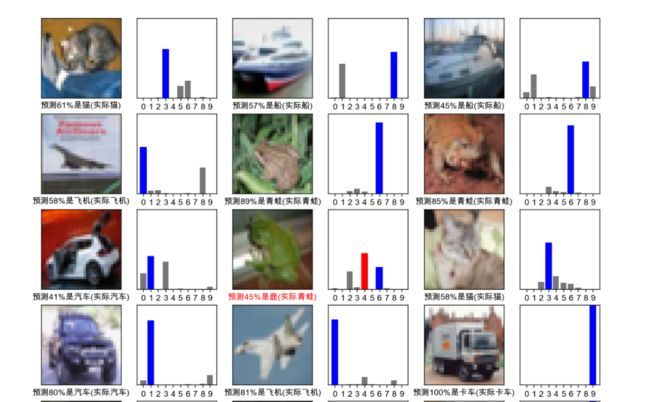
def plot_image(i, predictions_array, true_labels, images):
predictions_array, true_label, img = predictions_array[i], true_labels[i], images[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示照片,以cm 为单位。
plt.imshow(images[i], cmap=plt.cm.binary)
# 预测的图片是否正确,黑色底表示预测正确,红色底表示预测失败
predicted_label = np.argmax(prediction[i])
true_label = y_test[i][0]
if predicted_label == true_label:
color = 'black'
else:
color = 'red'
# plt.xlabel("{} ({})".format(class_names[predicted_label],
# class_names[true_label]),
# color=color)
plt.xlabel("预测{:2.0f}%是{}(实际{})".format(100*np.max(predictions_array),
class_names[predicted_label],
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i][0]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, prediction, y_test, x_test)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, prediction, y_test)
6、拓展学习之独立热编码实现
"""one_hot独立热编码"""
y_onehot = tf.keras.utils.to_categorical(y)
y_test_onehot = tf.keras.utils.to_categorical(y_test)
"""模型编译"""
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001),
loss = tf.keras.losses.categorical_crossentropy,
metrics = ['acc']
)
"""模型训练"""
batches = 20
batch_size = 10000
data = []
for i in range(batches):
index=np.random.choice(x.shape[0],batch_size,replace=False)
x_batch = x[index]
y_batch = y_onehot[index]
history = model.fit(x_batch,y_batch, validation_split=0.2)# 训练
hist = pd.DataFrame(history.history)
data.append(hist)
独立热编码实现和单个数字实现准确率并没有很大的区别,只是损失函数变为tf.keras.losses.categorical_crossentropy

参考文献:https://blog.csdn.net/LQ_qing/article/details/99859735