使用selenium+BeautifulSoup4爬取拉勾网信息
使用selenium爬取拉勾网信息
拉钩网的反爬技术做的很好,我尝试了网上的各种解决方案,都不怎么管用,如果直接使用scrapy框架爬取url信息的话,就会因为访问过于频繁而被限制,跳出以下页面:
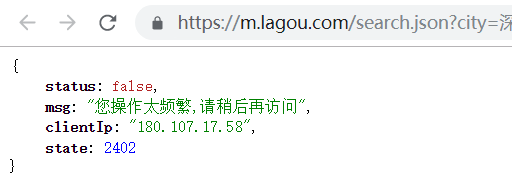
没办法了,只好祭出终极武器,使用selenium完全模仿浏览器的行为。
tips:这里是要先按照chromedriver的,使用bing搜索,可以立马搜索到结果,下载chromedriver.exe(下载时注意与浏览器对应的版本!!!),然后放在python执行文件夹下就行了,获取放在其他什么地方,但是要配置环境变量。
话不多说,先上代码:
import time
from pymongo import MongoClient
from selenium import webdriver # 导入Selenium的webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 导入Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
class lagouSpider(object):
def __init__(self):
self.start_url = 'https://www.lagou.com/'
self.keyword = 'python'
self.driver = webdriver.Chrome() # 指定使用的浏览器,初始化webdriver
self.wait = WebDriverWait(self.driver, 10)
self.mongo_url = 'mongodb://localhost:27017'
self.mongo_db = 'webpack'
self.count = 0
# self.collection = 'shenzheng'
self.collection = 'shanghai'
def run(self):
self.client = MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
self.search()
self.send_requests()
print(self.count)
self.client.close()
def search(self):
self.driver.get(self.start_url) # 请求网页地址
self.driver.find_element_by_id('cboxClose').click() # 一开始会有个弹出框,点击关掉它
# 输入关键字查询
time.sleep(1)
elem = self.driver.find_element(By.XPATH, './/input[@placeholder="搜索职位、公司或地点"]')
elem.send_keys(self.keyword)
elem.send_keys(Keys.RETURN)
# 点击城市,深圳
self.switch()
#self.click_action('//div[@id="filterCollapse"]/div[1]/div[2]/li/div[2]/div/a[3]')
# 点击城市,上海
self.click_action('//div[@id="filterCollapse"]/div[1]/div[2]/li/div[2]/div/a[2]')
# 点击,工作经验:三年以下
self.switch()
self.click_action('.//div[@id="filterCollapse"]/li[1]/a[3]')
def send_requests(self):
while True:
self.wait.until(EC.presence_of_element_located((By.XPATH, './/ul[@class="item_con_list"]')))
page = self.driver.page_source
self.parse_content(page)
# next_btn = self.wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="pager_container"]/span[last()]')))
next_btn = self.driver.find_element(By.XPATH, '//div[@class="pager_container"]/span[last()]')
# 判断是否是最后一页,如果是,退出while循环
if 'pager_next pager_next_disabled' in next_btn.get_attribute('class'):
break
else:
next_btn.click()
time.sleep(1)
def parse_content(self, page): # 显示等待
soup = BeautifulSoup(page, 'lxml')
# print(soup.title)
all_jobs = soup.find_all('li', attrs={'data-index': True})
# print(type(all_jobs))
for i, child in enumerate(all_jobs):
# print(i, child.attrs)
item = {}
item['company'] = child['data-company']
item['salary'] = child['data-salary']
item['job'] = child['data-positionname']
item['company_detail'] = child.find('div', attrs={'class': "industry"}).string.strip()
item['desc'] = child.find('div', attrs={'class': 'li_b_r'}).string
print(item)
table = self.db[self.collection]
self.count += 1
table.insert_one(item)
def switch(self):
# 切换到新的页面时,获取最新的driver
time.sleep(2)
self.driver.switch_to.window(self.driver.window_handles[-1])
def click_action(self, xpath):
# 点击页面某个按键操作
elem = self.driver.find_element(By.XPATH, xpath)
elem.click()
if __name__ == "__main__":
lagou = lagouSpider()
lagou.run()
步骤分析
我们一步一步来分析,打开拉钩网的首页,我们看到的是:
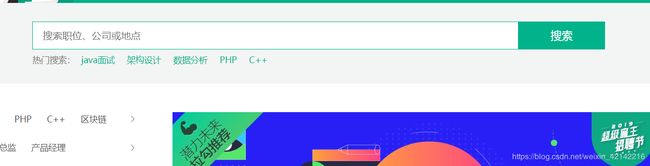
这就需要我们在搜索框输入关键字,试着输入:python
# 输入关键字查询
time.sleep(1)
elem = self.driver.find_element(By.XPATH, './/input[@placeholder="搜索职位、公司或地点"]') # 找到搜索框
elem.send_keys(self.keyword) # 输入关键字
elem.send_keys(Keys.RETURN) # 回车
注意:这里睡一秒的原因是留给浏览器时间,加载出搜索框
然后我们就会到这个页面
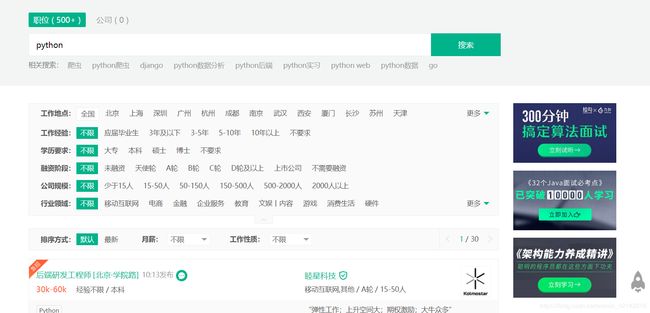
我们使用xpath浏览器插件,获取 [上海]城市标签的地址,用浏览器点击
# 点击城市,深圳
self.switch()
#self.click_action('//div[@id="filterCollapse"]/div[1]/div[2]/li/div[2]/div/a[3]')
# 点击城市,上海
self.click_action('//div[@id="filterCollapse"]/div[1]/div[2]/li/div[2]/div/a[2]')
注:这里的switch是为了获取到最新的driver,因为页面已经发生了改变,我们要获取到最新的界面才能操作上面的元素。
然后我们就进入到了上海的页面
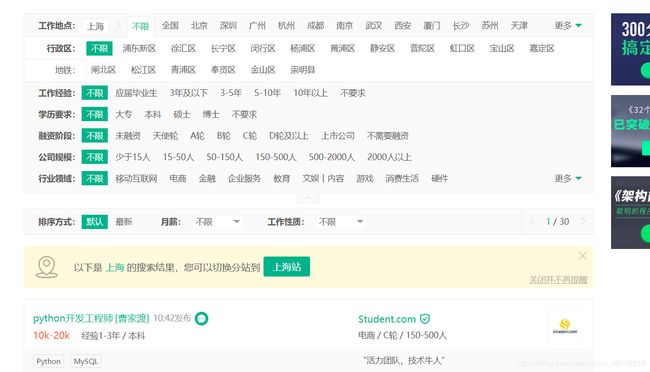
我们要提取的信息是,职位,公司,工资和公司描述,
def parse_content(self, page): # 显示等待
soup = BeautifulSoup(page, 'lxml')
# print(soup.title)
# 找到这一页的岗位的列表
all_jobs = soup.find_all('li', attrs={'data-index': True})
# print(type(all_jobs))
# 遍历每一个岗位信息
for i, child in enumerate(all_jobs):
# print(i, child.attrs)
item = {}
item['company'] = child['data-company']
item['salary'] = child['data-salary']
item['job'] = child['data-positionname']
item['company_detail'] = child.find('div', attrs={'class': "industry"}).string.strip()
item['desc'] = child.find('div', attrs={'class': 'li_b_r'}).string
print(item)
# 存入MongoDB
table = self.db[self.collection]
self.count += 1
table.insert_one(item)
关于BeautifulSoup和MongoDB的使用这里不再赘述,这里的保存还是建议大家使用菲关系数据库MongoDB,简单易操作
但是仅仅提取这一页是不够的,我们需要循环的点击,下一页,在每一页上提取这些数据。
def send_requests(self):
while True:
self.wait.until(EC.presence_of_element_located((By.XPATH, './/ul[@class="item_con_list"]')))
page = self.driver.page_source
self.parse_content(page)
# next_btn = self.wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="pager_container"]/span[last()]')))
next_btn = self.driver.find_element(By.XPATH, '//div[@class="pager_container"]/span[last()]') # 找到下一页的按钮
# 判断是否是最后一页,如果是,退出while循环
if 'pager_next pager_next_disabled' in next_btn.get_attribute('class'):
break
else:
next_btn.click() # 点击下一页
time.sleep(1)
至此,我们就经历了整个爬取的过程,使用面向对象的思想写完run方法就是这样:
def run(self):
self.client = MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
self.search()
self.send_requests()
print(self.count)
self.client.close()
保存的数据如下:
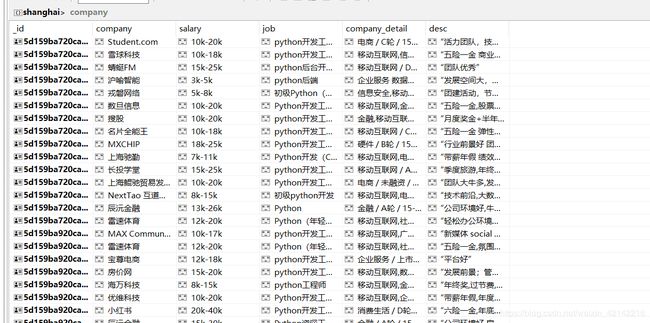
但是,这里还是有些缺陷的,首先拉钩提供的数据只有30页,其次,当我们爬取到第29页的时候会跳转到登录页面,验证身份。我们可以通过在最开始模拟登录来解决这个问题,亦或是尝试爬取其他网站的招聘信息来弥补数据量的不足。
大家可以自己动手实践一下哈,对于掌握selenium和beatufulSoup很有帮助
本章内容就到这里,再下一章节中,我们将使用pandas对爬取到的数据进行分析,敬请期待。