python3.0实现网站数据、图片的爬取
实验背景
网络信息技术持续不断快速的发展,越来越多人开始关注Python对网络爬虫系统的设计。然而,各种网址信息数据提取是一项复杂的工作,通过使用网络爬虫技术,能够在短时间内提取到各种有价值的信息数据,学习Python语言,基于Python对网络爬虫系统和数据库系统的设计与实现,并对数据进行处理。
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。其实,说白了就是爬虫可以模拟浏览器的行为做你想做的事,订制化自己搜索和下载的内容,并实现自动化的操作。比如浏览器可以下载小说,但是有时候并不能批量下载,那么爬虫的功能就有用武之地了。
实验概述
首先,确定要爬取的网站为https://www.huxiu.com,然后连接到目标数据库114.115.168.196,插入输入,进行遍历测试,测试成功后进行网页的爬取,将爬取的内容存入数据库中,并且最终实现爬取的数据已web形式展现出来。
实验目标
实现在网络中爬取需要的网络数据,并且导入到数据库中,再进一步的分析处理。
具体要求:
- 了解网页的设计结构,能够看懂网页制作模块的相关代码。
- 掌握基本的python语言,能够在网络中爬取自己需要的数据
- 安装mysql数据库,并且链接数据库、数据插入、遍历测试等操作
- 网页爬取数据存入数据库,用python语言对数据进行插入,查询,修改,删除等操作
系统框架

实施流程
- 购买阿里云数据库并进行相关测试

- 链接目标数据库,数据插入,遍历测试

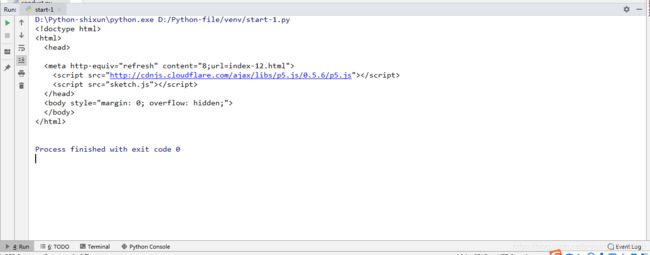
- 网页数据爬取测试
- 数据库数据显示

数据库连接code
数据库连接,数据插入,遍历测试:
Code :
import pymysql #如果没有模块 执行 pip install pymysql
conn = pymysql.connect(host='114.115.168.196', user = "User2", passwd="Usering-2", db="test", port=3306, charset="utf8")
if conn:
print("ok")
else:print("not connected") #连接数据库并判断是否连接成功
cur = conn.cursor() # 使用 cursor() 方法创建一个游标对象 cursor
#sql语句
sql = "insert into logo (Name, time) value(%s, %s)"
#数据
person = [['小5军', '19930630'], ['小5明', '19930403']]
for i in range(len(person)):
param = tuple(person[i]) #将列表转换为元组
print(param ,end=" ") #插入数据库的数据
#执行sql语句
count = cur.execute(sql, param)
#判断是否成功
if count > 0:
print("添加数据成功!\n")
#提交事务
conn.commit()
#查询数据
cur.execute("select * from logo where time>= 100")
#获取数据
users = cur.fetchall() #fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
#fetchall(): 接收全部的返回结果行.
#rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数
for i in range(len(users)):
print(users[i])
#关闭资源连接
cur.close()
conn.close()
print("数据库断开连接!")
 网页数据爬取、存入code
网页数据爬取、存入code
网页爬取测试:
Code:
from urllib import request
import chardet
response = request.urlopen("http://www.bananaviolet.club/")
html = response.read()
charset = chardet.detect(html) # {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
网页爬取存入数据库,并且显示:
Code:
class MySQLCommand(object):
# 类的初始化
def __init__(self): #将网页数据爬取保存到数据库
self.host = '114.115.168.196'
self.port = 3306 # 端口号
self.user = 'User2' # 用户名
self.password = "Usering-2" # 密码
self.db = "admin" # 库
self.table = "table1" # 表
# 链接数据库
def connectMysql(self):
try:
self.conn = pymysql.connect(host=self.host, port=self.port, user=self.user,
passwd=self.password, db=self.db, charset='utf8')
self.cursor = self.conn.cursor()
except:
print('connect mysql error.')
# 插入数据,插入之前先查询是否存在,如果存在就不再插入
def insertData(self, my_dict):
table = "table1" # 要操作的表格
# 注意,这里查询的sql语句url=' %s '中%s的前后要有空格
sqlExit = "SELECT url FROM table1 WHERE url = ' %s '" % (my_dict['url'])
res = self.cursor.execute(sqlExit)
if res: # res为查询到的数据条数如果大于0就代表数据已经存在
print("数据已存在", res)
return 0
# 数据不存在才执行下面的插入操作
try:
cols = ', '.join(my_dict.keys())#用,分割
values = '"," '.join(my_dict.values())
sql = "INSERT INTO table1 (%s) VALUES (%s)" % (cols, '"' + values + '"')
try:
result = self.cursor.execute(sql)
insert_id = self.conn.insert_id() # 插入成功后返回的id
self.conn.commit()
# 判断是否执行成功
if result:
print("插入成功", insert_id)
return insert_id + 1
except pymysql.Error as e:
# 发生错误时回滚
self.conn.rollback()
# 主键唯一,无法插入
if "key 'PRIMARY'" in e.args[1]:
print("数据已存在,未插入数据")
else:
print("插入数据失败,原因 %d: %s" % (e.args[0], e.args[1]))
except pymysql.Error as e:
print("数据库错误,原因%d: %s" % (e.args[0], e.args[1]))
# 查询最后一条数据的id值
def getLastId(self):
sql = "SELECT max(id) FROM " + self.table
try:
self.cursor.execute(sql)
row = self.cursor.fetchone() # 获取查询到的第一条数据
if row[0]:
return row[0] # 返回最后一条数据的id
else:
return 0 # 如果表格为空就返回0
except:
print(sql + ' execute failed.')
def closeMysql(self):
self.cursor.close()
self.conn.close()
# 创建数据库操作类的实例
from bs4 import BeautifulSoup
from urllib import request
import chardet
import pymysql
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"]))
#设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
# 连接数据库
mysqlCommand = MySQLCommand()
mysqlCommand.connectMysql()
#这里每次查询数据库中最后一条数据新加的数据每成功插入一条id+1
dataCount = int(mysqlCommand.getLastId()) + 1
for news in allList: # 遍历列表,获取有效信息
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try: # 如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href = ''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl = ""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = ""
#把爬取到的每条数据组合成一个字典用于数据库数据的插入
news_dict = {
"id": str(dataCount),
"title": title,
"url": href,
"img_path": imgUrl
}
try:
# 插入数据,如果已经存在就不在重复插入
res = mysqlCommand.insertData(news_dict)
if res:
dataCount=res
except Exception as e:
print("插入数据失败", str(e))#输出插入失败的报错语句
mysqlCommand.closeMysql() # 最后一定要要把数据关闭
dataCount=0
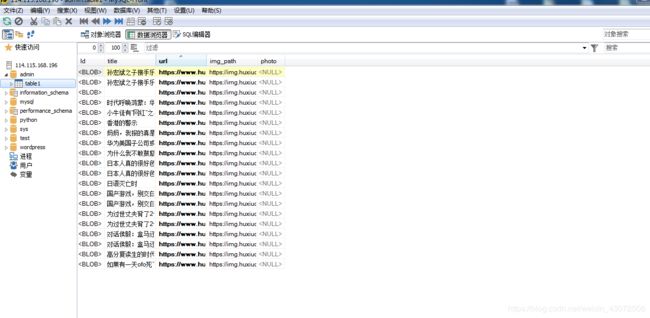
将数据库爬取数据显示
web:
Code:
<?php
// 创建连接
if($con = mysqli_connect("114.115.168.196","User2","Usering-2", "admin")){
echo 'connected';
}else{
echo 'fail';
}
// 检测连接
$sql = 'select * from table1';
$query =mysqli_query($con,$sql);
while ($first=mysqli_fetch_assoc($query)) {
$list[] =$first;
# print_r($list);
# code...
}
foreach($list as $key=>$row){
echo "
";
echo "";
echo " 编号:
{$row['id']} ";
echo "文章标题:
{$row['title']} ";
echo "文章地址:
{$row['url']} ";
echo "图片链接:
{$row['img_path']} ";
echo "图片:
{$row['photo']} ";
echo "删除 修改 ";
echo "";
echo "
";
}
?>
实验总结
爬取了网站https://www.huxiu.com的数据,连接了目标数据库,并将数据插入到了数据库中进行遍历测试,应用了函数、模块等Python相关的语句,同时实现了SQL语句实现了该功能,将爬取的网站数据存储到数据库中,并将其显示于web。
附录
.主要程序
Code :
import pymysql #如果没有模块 执行 pip install pymysql
conn = pymysql.connect(host='114.115.168.196', user = "User2", passwd="Usering-2", db="test", port=3306, charset="utf8")
if conn:
print("ok")
else:print("not connected") #连接数据库并判断是否连接成功
cur = conn.cursor() # 使用 cursor() 方法创建一个游标对象 cursor
#sql语句
sql = "insert into logo (Name, time) value(%s, %s)"
#数据
person = [['小5军', '19930630'], ['小5明', '19930403']]
for i in range(len(person)):
param = tuple(person[i]) #将列表转换为元组
print(param ,end=" ") #插入数据库的数据
#执行sql语句
count = cur.execute(sql, param)
#判断是否成功
if count > 0:
print("添加数据成功!\n")
#提交事务
conn.commit()
#查询数据
cur.execute("select * from logo where time>= 100")
#获取数据
users = cur.fetchall() #fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
#fetchall(): 接收全部的返回结果行.
#rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数
for i in range(len(users)):
print(users[i])
#关闭资源连接
cur.close()
conn.close()
print("数据库断开连接!")
Code:
from urllib import request
import chardet
response = request.urlopen("http://www.bananaviolet.club/")
html = response.read()
charset = chardet.detect(html) # {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
Code:
class MySQLCommand(object):
# 类的初始化
def __init__(self): #将网页数据爬取保存到数据库
self.host = '114.115.168.196'
self.port = 3306 # 端口号
self.user = 'User2' # 用户名
self.password = "Usering-2" # 密码
self.db = "admin" # 库
self.table = "table1" # 表
# 链接数据库
def connectMysql(self):
try:
self.conn = pymysql.connect(host=self.host, port=self.port, user=self.user,
passwd=self.password, db=self.db, charset='utf8')
self.cursor = self.conn.cursor()
except:
print('connect mysql error.')
# 插入数据,插入之前先查询是否存在,如果存在就不再插入
def insertData(self, my_dict):
table = "table1" # 要操作的表格
# 注意,这里查询的sql语句url=' %s '中%s的前后要有空格
sqlExit = "SELECT url FROM table1 WHERE url = ' %s '" % (my_dict['url'])
res = self.cursor.execute(sqlExit)
if res: # res为查询到的数据条数如果大于0就代表数据已经存在
print("数据已存在", res)
return 0
# 数据不存在才执行下面的插入操作
try:
cols = ', '.join(my_dict.keys())#用,分割
values = '"," '.join(my_dict.values())
sql = "INSERT INTO table1 (%s) VALUES (%s)" % (cols, '"' + values + '"')
try:
result = self.cursor.execute(sql)
insert_id = self.conn.insert_id() # 插入成功后返回的id
self.conn.commit()
# 判断是否执行成功
if result:
print("插入成功", insert_id)
return insert_id + 1
except pymysql.Error as e:
# 发生错误时回滚
self.conn.rollback()
# 主键唯一,无法插入
if "key 'PRIMARY'" in e.args[1]:
print("数据已存在,未插入数据")
else:
print("插入数据失败,原因 %d: %s" % (e.args[0], e.args[1]))
except pymysql.Error as e:
print("数据库错误,原因%d: %s" % (e.args[0], e.args[1]))
# 查询最后一条数据的id值
def getLastId(self):
sql = "SELECT max(id) FROM " + self.table
try:
self.cursor.execute(sql)
row = self.cursor.fetchone() # 获取查询到的第一条数据
if row[0]:
return row[0] # 返回最后一条数据的id
else:
return 0 # 如果表格为空就返回0
except:
print(sql + ' execute failed.')
def closeMysql(self):
self.cursor.close()
self.conn.close()
# 创建数据库操作类的实例
from bs4 import BeautifulSoup
from urllib import request
import chardet
import pymysql
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"]))
# 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
# 连接数据库
mysqlCommand = MySQLCommand()
mysqlCommand.connectMysql()
#这里每次查询数据库中最后一条数据新加的数据每成功插入一条id+1
dataCount = int(mysqlCommand.getLastId()) + 1
for news in allList: # 遍历列表,获取有效信息
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try: # 如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href = ''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl = ""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = ""
#把爬取到的每条数据组合成一个字典用于数据库数据的插入
news_dict = {
"id": str(dataCount),
"title": title,
"url": href,
"img_path": imgUrl
}
try:
# 插入数据,如果已经存在就不在重复插入
res = mysqlCommand.insertData(news_dict)
if res:
dataCount=res
except Exception as e:
print("插入数据失败", str(e))#输出插入失败的报错语句
mysqlCommand.closeMysql() # 最后一定要要把数据关闭
dataCount=0
web:
Code:
<?php
// 创建连接
if($con = mysqli_connect("114.115.168.196","User2","Usering-2", "admin")){
echo 'connected';
}else{
echo 'fail';
}
// 检测连接
$sql = 'select * from table1';
$query =mysqli_query($con,$sql);
while ($first=mysqli_fetch_assoc($query)) {
$list[] =$first;
# print_r($list);
# code...
}
foreach($list as $key=>$row){
echo "
";
echo "";
echo " 编号:
{$row['id']} ";
echo "文章标题:
{$row['title']} ";
echo "文章地址:
{$row['url']} ";
echo "图片链接:
{$row['img_path']} ";
echo "图片:
{$row['photo']} ";
echo "删除 修改 ";
echo "";
echo "
";
}
?>
你可能感兴趣的:(笔记,mysql,vim,python,html)