Java之JVM初探:类加载机制、Natic、PC寄存器、方法区、栈、堆、OOM、GC垃圾回收机制、GC常用算法、强引用、软引用、弱引用、虚引用
文章目录
- JVM 初探
- 一、类加载器
- 1、JVM类加载机制3种
- 全盘负责
- 双亲委派(重点 面试高频)
- 缓存机制
- 二、沙箱安全机制(了解)
- 三、Native、PC寄存器、方法区
- 1、Native(重点)
- 2、PC寄存器(线程私有)
- 3、方法区(属于元空间)
- 四、栈(线程私有)
- 五、三种JVM
- 六、堆
- 1、解决OOM的方式
- 2、通过修改堆内存,查看GC运作
- 七、GC
- 1、GC垃圾回收机制
- 2、GC常用算法
- 引用计数算法
- 复制算法(适合新生代)
- 标记清除算法(适合老年代)
- 标记整理算法(适合老年代)
- 分代算法
- 总结
- 八、引用
- 1、强引用
- 2、软引用
- 3、弱引用
- 4、虚引用
JVM 初探
基于JDK1.8
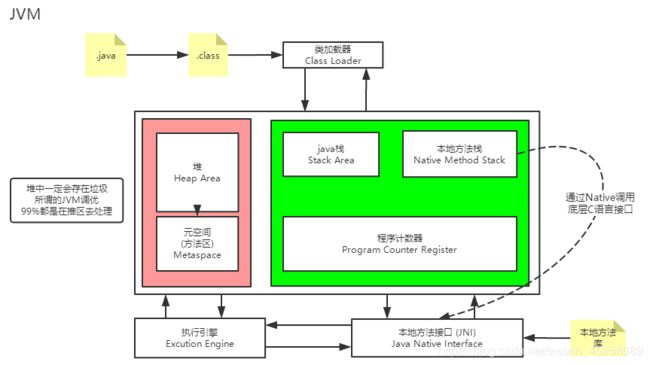
一、类加载器

三大类加载器:
引导类加载器(Java核心rt.jar包)、扩展类加载器、系统类加载器
1、JVM类加载机制3种
全盘负责
所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
双亲委派(重点 面试高频)
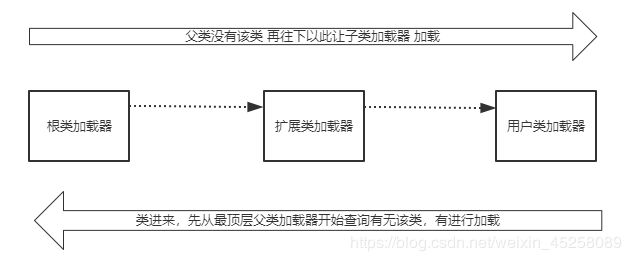
双亲委派机制,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己才想办法去完成。
优点:
保证安全。(如果用户自己写了一个String类,那么就不会被得到执行加载。)
缓存机制
缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为很么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
二、沙箱安全机制(了解)
沙箱安全机制
三、Native、PC寄存器、方法区
1、Native(重点)
Native是java中的关键字,说明了java的作用范围达不到了,会去调用本地方法接口,也就是C++语言的方法。
在内存开辟了一个标记区域,也就是本地方法栈,去登记native方法,在最终执行的时候去加载本地方法库中的方法,通过JNI。
【作用】
- 扩展Java的使用,迎合不同的编程语言为Java所用。
2、PC寄存器(线程私有)
程序计数器(Program Counter Register)
程序计数器是一个记录着当前线程所执行的字节码的行号指示器。
JAVA代码编译后的字节码在未经过JIT(实时编译器)编译前,其执行方式是通过“字节码解释器”进行解释执行。简单的工作原理为解释器读取装载入内存的字节码,按照顺序读取字节码指令。读取一个指令后,将该指令“翻译”成固定的操作,并根据这些操作进行分支、循环、跳转等流程。
从上面的描述中,可能会产生程序计数器是否是多余的疑问。因为沿着指令的顺序执行下去,即使是分支跳转这样的流程,跳转到指定的指令处按顺序继续执行是完全能够保证程序的执行顺序的。假设程序永远只有一个线程,这个疑问没有任何问题,也就是说并不需要程序计数器。但实际上程序是通过多个线程协同合作执行的。
首先我们要搞清楚JVM的多线程实现方式。JVM的多线程是通过CPU时间片轮转(即线程轮流切换并分配处理器执行时间)算法来实现的。也就是说,某个线程在执行过程中可能会因为时间片耗尽而被挂起,而另一个线程获取到时间片开始执行。当被挂起的线程重新获取到时间片的时候,它要想从被挂起的地方继续执行,就必须知道它上次执行到哪个位置,在JVM中,通过程序计数器来记录某个线程的字节码执行位置。因此,程序计数器是具备线程隔离的特性,也就是说,每个线程工作时都有属于自己的独立计数器。
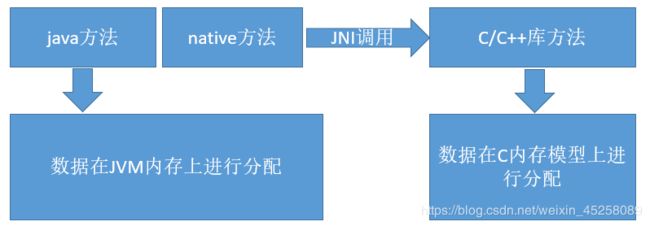
特点
-
线程隔离性,每个线程工作时都有属于自己的独立计数器。
-
执行java方法时,程序计数器是有值的,且记录的是正在执行的字节码指令的地址(参考上一小节的描述)。
-
执行native本地方法时,程序计数器的值为空(Undefined)。因为native方法是java通过JNI直接调用本地C/C++库,可以近似的认为native方法相当于C/C++暴露给java的一个接口,java通过调用这个接口从而调用到C/C++方法。由于该方法是通过C/C++而不是java进行实现。那么自然无法产生相应的字节码,并且C/C++执行时的内存分配是由自己语言决定的,而不是由JVM决定的。
-
程序计数器占用内存很小,在进行JVM内存计算时,可以忽略不计。
-
程序计数器,是唯一一个在java虚拟机规范中没有规定任何
OutOfMemoryError的区域。
3、方法区(属于元空间)

方法区与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
静态变量static、常量final、类信息Class(构造方法、接口定义)、运行时的常量池存放在方法区中,但是实例存在堆内存中与方法区无关
创建对象的内存分析
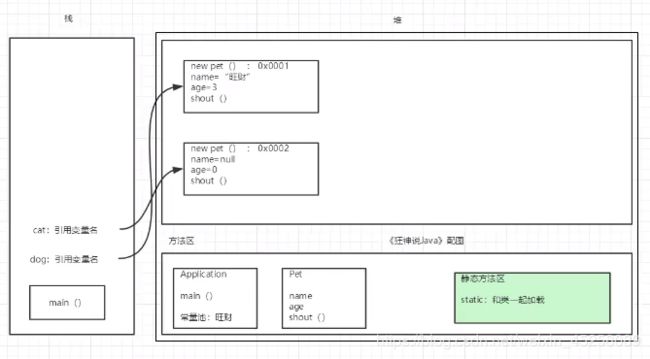
常量池
类型的常量池(该部分是独有的,然后运行时,把该部分加载进运行时常量池,当调用时则从符号引用解析为直接引用,但是有些确定的方法会直接转换,比如静态方法,比如构造方法)
存放该类型所用到的常量的有序集合,包括直接常量(如字符串、整数、浮点数的常量)和对其他类型、字段、方法的符号引用。常量池中每一个保存的常量都有一个索引,就像数组中的字段一样。因为常量池中保存中所有类型使用到的类型、字段、方法的符号引用,所以它也是动态连接(栈中对应的方法指向这个引用)的主要对象(在动态链接中起到核心作用)。
四、栈(线程私有)
栈:先进后出 FILO
队列:先进先出 FIFO
对于栈来说,不存在垃圾回收问题,因为根本不产生垃圾。
栈内存满了,会抛出错误StackOverflowError
理解:栈、堆、方法区之间的关系
五、三种JVM
- SUN公司:
HotSpot - BEA:
JRockit - IBM:
J9 VM
我们学的是:HotSpot
六、堆
一个JVM只有一个堆,堆内存大小是可以调节的。

堆分为:新生代、老年代、元空间(方法区,常量池等)
注意的是元空间不占用堆内存,它是另外开辟的一个内存空间。
1、解决OOM的方式
-
运行代码出现OOM,说明堆内存满了,可以扩大堆内存的大小,看看是否还会出现OOM。(如果还出现OOM问题,就说明代码有问题)
-Xms1024m -Xmx1024m -XX:+PrintGCDetails 输入该指令可以扩大堆内存,并且可以打印出堆内存GC回收信息。


-
分析内存,使用专业工具jProfiler,获取内存快照。
(首先在idea软件中安装jprofiler插件,然后再安装jprofiler客户端)
一样的在VM options中输入:
-Xms1m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError 设置堆内存初始化大小1m,总内存为8m,并将OutOfMemoryError的信息进行快照
2、通过修改堆内存,查看GC运作
public class T {
public static void main(String[] args) {
// -Xms8m -Xmx8m -XX:+PrintGCDetails 设置了该参数
int[] num = new int[10_0000_0000];
/* System.out.println(Runtime.getRuntime().maxMemory()); // 打印最大堆内存
System.out.println(Runtime.getRuntime().totalMemory()); // 打印使用的堆内存*/
}
}
输出:
[GC (Allocation Failure) [PSYoungGen: 1536K->488K(2048K)] 1536K->664K(7680K), 0.0013262 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 553K->504K(2048K)] 729K->680K(7680K), 0.0017128 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 504K->488K(2048K)] 680K->696K(7680K), 0.0005671 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 488K->0K(2048K)] [ParOldGen: 208K->615K(5632K)] 696K->615K(7680K), [Metaspace: 3128K->3128K(1056768K)], 0.0077844 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [PSYoungGen: 0K->0K(2048K)] 615K->615K(7680K), 0.0003576 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 0K->0K(2048K)] [ParOldGen: 615K->597K(5632K)] 615K->597K(7680K), [Metaspace: 3128K->3128K(1056768K)], 0.0065888 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 2048K, used 146K [0x00000000ffd80000, 0x0000000100000000, 0x0000000100000000)
eden space 1536K, 9% used [0x00000000ffd80000,0x00000000ffda4958,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 5632K, used 597K [0x00000000ff800000, 0x00000000ffd80000, 0x00000000ffd80000)
object space 5632K, 10% used [0x00000000ff800000,0x00000000ff895520,0x00000000ffd80000)
Metaspace used 3215K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 347K, capacity 388K, committed 512K, reserved 1048576K
// 最后报错:
// Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
// at T.main(T.java:11)
七、GC
1、GC垃圾回收机制
GC (Garbage Collection)垃圾回收机制。99%都是处理堆中的垃圾,因为堆是线程共享的,是产生垃圾的场所。
堆分为
-
新生代
- Eden伊甸园区
- From幸存区
- To幸存区
-
老年代
-
元空间
这里需要注意的是,From和To新生区的内存会不定时的互换,名字也会互换。交替性的过程。
GC在处理垃圾的时候,如果Eden中的对象没有被清除掉,就会进入幸存区,在伊甸园区和幸存区满了的情况下,经过Full GC的垃圾回收机制,还有没有被清除掉的对象,就会从幸存区进入到老年代。
2、GC常用算法
新生代的垃圾较多,对象存活率较低。
老年代对象存活率较高,垃圾较少。
引用计数算法
假设有一个对象A,任何一个对象对A的引用,那么对象A的引用计数器+1,当引用消失时,对象A的引用计数器就-1,如果对象A的计数器的值为0,就说明对象A没有引用了,可以被回收。
优点:
- 实时性较高,无需等到内存不够的时候,才开始回收,运行时根据对象的计数器是否为0,就可以直接回收。
- 在垃圾回收过程中,应用无需挂起。如果申请内存时,内存不足,则立刻报outofmember 错误。
- 区域性,更新对象的计数器时,只是影响到该对象,不会扫描全部对象。
缺点:
- 每次对象被引用时,都需要去更新计数器,有一点时间开销。
- 浪费CPU资源,即使内存够用,仍然在运行时进行计数器的统计。
- 无法解决循环引用问题。(最大的缺点)
复制算法(适合新生代)
当Eden空间将要满的时候第一次触发YGC,将还有引用的对象复制到from区同时每个对象的年龄将会+1,等到了默认值15岁的时候就会被移入到old区,此时to区还是空的,同时清空Eden区,接下来再进行YGC的时候会将Eden区和from区还存活着的对象移入到to区,同时清空Eden区和from区,然后将form区和to进行交互,谁是空的谁变为to区。如果内存中的垃圾对象较多,需要复制的对象就较少,这种情况下适合使用该方式并且效率比较高,反之,则不适合。
据统计,新生代的对象朝生夕死,90%以上的对象都无法活过eden区。
优点:
- 在垃圾对象多的情况下,效率较高
- 清理后,内存无碎片
缺点:
- 在垃圾对象少的情况下,不适用,如:老年代内存
- 分配的2块幸存内存空间,在同一个时刻,只能使用一半,内存使用率较低
-XX:PretenureSizeThreshold (默认值为0)的意思是超过这个值的时候,对象直接在old区分配内存
-XX:MaxTenuringThreshold (默认值为15) 年龄阈值 ,每个对象的前面都会有4个bit位的大小来存储他的年龄,最大为1111转为十进制就为15
标记清除算法(适合老年代)
标记-清除算法分为两个阶段,标记(mark)和清除(sweep)
在标记阶段,GC从根对象开始进行遍历,对从根对象可以访问到的对象都打上一个标识,一般是在对象的header中,将其记录为可达对象。
而在清除阶段,GC对堆内存(heap memory)从头到尾进行线性的遍历,如果发现某个对象没有标记为可达对象-通过读取对象的header信息,则就将其回收;如果发现某个对象有标记为可达对象,那么就清除标记位(为下一次标记做准备)。
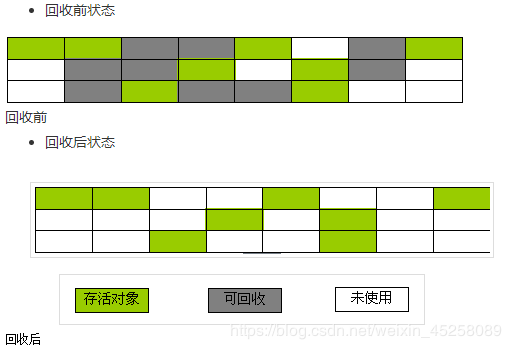
优点:
- 解决了引用计数法中无法解决的循环引用问题
缺点:
- 效率较低,标记和清除两个动作都需要遍历所有的对象,并且在GC时,需要停止应用程序,对于交互性要求比较高的应用而言这个体验是非常差的。
- 通过标记清除算法清理出来的内存,碎片化较为严重,因为被回收的对象可能存在于内存的各个角落,所以清理出来的内存是不连贯的。
标记整理算法(适合老年代)
标记压缩算法是在标记清除算法的基础之上,做了优化改进的算法。和标记清除算法一样,也是从根节点开始,对对象的引用进行标记,在清理阶段,并不是简单的清理未标记的对象,而是将存活的对象压缩到内存的一端,然后清理边界以外的垃圾,并且清除存活对象的标记位(为下一次标记做准备),从而解决了碎片化的问题。

分代算法
因为
新生代的垃圾较多,对象存活率较低。
老年代对象存活率较高,垃圾较少。
所以
新生代适合 复制算法,因为存活的对象低,复制速度快。
老年代适合 标记清除算法+标记整理算法混合使用,当内存碎片过多时使用一次标记整理算法。
总结
内存效率(时间复杂度):复制算法 > 标记清除算法 > 标记整理算法
内存整理:复制算法 = 标记整理算法 > 标记清除算法
内存利用率:标记整理算法 = 标记清除算法 > 复制算法
八、引用
1、强引用
是指创建一个对象并把这个对象赋给一个引用变量。比如:
Object object =new Object(); String str ="hello";
强引用有引用变量指向时永远不会被垃圾回收,JVM宁愿抛出OutOfMemory错误也不会回收这种对象。
如果想中断强引用和某个对象之间的关联,可以显示地将引用赋值为null,这样一来的话,JVM在合适的时间就会回收该对象。
2、软引用
如果一个对象具有软引用,内存空间足够,垃圾回收器就不会回收它;
如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
软引用可用来实现内存敏感的高速缓存,比如网页缓存、图片缓存等。使用软引用能防止内存泄露,增强程序的健壮性。
SoftReference的特点是它的一个实例保存对一个Java对象的软引用, 该软引用的存在不妨碍垃圾收集线程对该Java对象的回收。
也就是说,一旦SoftReference保存了对一个Java对象的软引用后,在垃圾线程对 这个Java对象回收前,SoftReference类所提供的get()方法返回Java对象的强引用。
另外,一旦垃圾线程回收该Java对象之 后,get()方法将返回null。
3、弱引用
弱引用也是用来描述非必需对象的,当JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference类来表示。
4、虚引用
虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期,不能通过虚引用去访问引用的对象。在java中用java.lang.ref.PhantomReference类表示。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。
要注意的是,虚引用必须和引用队列关联使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会把这个虚引用加入到与之 关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。