我如何用飞桨复现了ICCV 2019 ACNet模型?

【飞桨开发者说】尚方信,某一线互联网公司计算机视觉算法开发者

ACNet源于ICCV 2019的一篇文章:
https://arxiv.org/abs/1908.03930v3

其核心思想是通过非对称卷积块增强CNN的核骨架。即使用非对称的卷积核组,替换目前CNN架构中常用的3x3 / 5x5 / 7x7方形卷积核,以支持网络对某些非对称的图像特征实现更有效的特征提取。这样的非对称卷积核组,可以即插即用地与任何卷积神经网络架构结合。

模型结构
此外,这样的非对称卷积核,其卷积结果不受图像水平/垂直翻转的影响。

非对称卷积核
进一步地,所有的非对称卷积核可以合并为一个方形卷积核,因此在部署上线的模型中,多个非对称卷积分支并不会带来更多的运算量。
关于论文的更多介绍,可以阅读论文或查看这篇博客:
https://zhuanlan.zhihu.com/p/93966695
近日,我们基于飞桨(PaddlePaddle)复现了ACNet,并被飞桨官方模型库收录。下面和大家分享下模型复现的技术细节。
搭建ACNet
ACNet模型结构定义请查看:
https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/resnet_acnet.py
我们基于飞桨官方实现的ResNet模型结构,实现了ResNet结构+非对称卷积核。
具体来说,是将ResNet中每一个【Conv+BN+Relu】模块,替换为【非对称卷积核组 + BN组 + Relu + Add】的组结构。
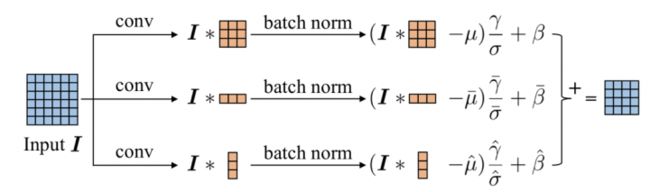
不对称卷积核组结构
首先考虑训练模式的模型结构,代码如下:
square_conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=padding,
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_acsquare_weights"),
bias_attr=None,
name=name + '.acsquare.conv2d.output.1')
飞桨的语法和TensorFlow比较类似,如上的代码片段,即定义了一个卷积层。
具体参数含义如下:
Input:传入待卷积处理的张量对象
num_filters:卷积核数量(输出的卷积结果的通道数)
filter_size:卷积核形状
stride:卷积步长
padding:卷积时边缘填充像素个数
groups:分组卷积的组数量
act:激活函数,由于后面还要接BN,这里给None代表不激活
param_attr:卷积核参数对象的属性,这里指定对象张量的名称
bias_attr:偏置参数对象属性,给None代表不需要bias
name:当前卷积层作为一个整体,在运算图中的对象名称
squareconv代表方形对称的卷积核,同理,改变filtersize、padding和stride参数,可以定义水平/垂直两个方向的非对称卷积核(1x3, 3x1等)。
# 垂直方向,vertical
ver_conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=(filter_size, 1),
stride=stride,
padding=(padding, 0),
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_acver_weights"),
bias_attr=False,
name=name + '.acver.conv2d.output.1')
# 水平方向,horizontal
hor_conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=(1, filter_size),
stride=stride,
padding=(0, padding),
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_achor_weights"),
bias_attr=False,
name=name + '.achor.conv2d.output.1')
接着可以定义BN和Relu结构,调用batch_norm API定义批归一化层,对方形卷积核的输出进行批归一化。
square_bn = fluid.layers.batch_norm(
input=square_conv,
act=None,
name=bn_name + '.acsquare.output.1',
param_attr=ParamAttr(name=bn_name + '_acsquare_scale'),
bias_attr=ParamAttr(bn_name + '_acsquare_offset'),
moving_mean_name=bn_name + '_acsquare_mean',
moving_variance_name=bn_name + '_acsquare_variance', )
同理,可以定义不对称卷积核输出结果的批归一化层。
# 垂直方向批归一化
ver_bn = fluid.layers.batch_norm(
input=ver_conv,
act=None,
name=bn_name + '.acver.output.1',
param_attr=ParamAttr(name=bn_name + '_acver_scale'),
bias_attr=ParamAttr(bn_name + '_acver_offset'),
moving_mean_name=bn_name + '_acver_mean',
moving_variance_name=bn_name + '_acver_variance', )
# 水平方向批归一化
hor_bn = fluid.layers.batch_norm(
input=hor_conv,
act=None,
name=bn_name + '.achor.output.1',
param_attr=ParamAttr(name=bn_name + '_achor_scale'),
bias_attr=ParamAttr(bn_name + '_achor_offset'),
moving_mean_name=bn_name + '_achor_mean',
moving_variance_name=bn_name + '_achor_variance', )
最后,将三个批归一化结果张量相加,并进行ReLU激活。
output = fluid.layers.elementwise_add(
x=square_bn, y=ver_bn + hor_bn, act="relu")
return output
如上,就完成了ResNet核心的非对称卷积 + BN + ReLU模块conv_bn_layer_ac()的定义。
由于ResNet中存在1x1卷积,不存在相应的不对称卷积核结构,因此1x1 conv + BN + ReLU结构被保持原状,未被修改为ACNet结构。
def conv_bn_layer(self, **kwargs):
"""
conv_bn_layer
"""
if kwargs['filter_size'] == 1:
# 原始卷积BN
return self.conv_bn_layer_ori(**kwargs)
else:
# 不对称卷积BN
return self.conv_bn_layer_ac(**kwargs)
部署模型(权值聚合)

权值聚合方案
上文中描述的ACNet结构(训练模式,下同)将每一个卷积拆分成了3个卷积的卷积组,显然,这样的结构成倍增加了运算量。
事实上,我们可以对多个卷积+BN的分支进行聚合处理,产生一个方形卷积核,其卷积输出与原先多个卷积+BN的输出一致(部署模式,下同),这样的聚合结果,可以从数学上证明,是与训练模式的运算过程等价的。
因此,模型部署工作需要分为两步,即定义部署模式的模型运算图结构和权值聚合。
部署形式的模型结构定义
训练模式和部署模式的ACNet均包含方形卷积核,但训练模式的方形卷积核不包含偏置项。
在部署模式下,根据推导,多个卷积分支的BN层bias偏置项将被融合为一,并作为方形卷积核的偏置项被纳入运算过程中。除此以外,训练模式下所有的BN层和不对称卷积层,在部署模式的运算图中均不被定义。(以上讨论均不涉及1x1卷积)
因此,模型运算图定义可被修改如下。当模型为部署模式时,模型类对象的deploy属性为True,将影响所有self.deploy相关的逻辑。
square_conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=padding,
groups=groups,
act=act if self.deploy else None,
param_attr=ParamAttr(name=name + "_acsquare_weights"),
bias_attr=ParamAttr(name=name + "_acsquare_bias") if self.deploy else None,
name=name + '.acsquare.conv2d.output.1')
if self.deploy:
return square_conv
else:
ver_conv = ...
hor_conv = ...
square_bn = ...
ver_bn = ...
hor_bn = ...
return fluid.layers.elementwise_add(
x=square_bn, y=ver_bn + hor_bn, act=act)
权值聚合
根据飞桨官方文档介绍,我们可以使用Numpy操作飞桨模型权值,即将运算图中特定权值张量读取为Numpy数组,或将Numpy数组赋值给运算图中特定权值张量。
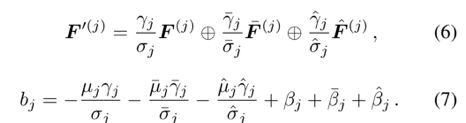
按照如上公式和图5,我们需要读取每一个卷积模块的卷积核权值、BN层scale,offset,running_mean和running_var,每一个卷积分支包含5个参数,我们的运算图中共3个卷积分支(方形、垂直、水平),因此共需要读取15个参数。
可以通过如下方式获取批归一化层的参数。
def get_ac_tensor(name):
gamma = fluid.global_scope().find_var(name + '_scale').get_tensor()
beta = fluid.global_scope().find_var(name + '_offset').get_tensor()
mean = fluid.global_scope().find_var(name + '_mean').get_tensor()
var = fluid.global_scope().find_var(name + '_variance').get_tensor()
return gamma, beta, mean, var
我们使用张量名称来获取具体的张量对象,需要与模型结构定义时的张量名称相对应。接着,我们获取一个卷积模块的15个参数。
def get_kernel_bn_tensors(name):
if "conv1" in name:
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
# 获取方形卷积核
ac_square = fluid.global_scope().find_var(name +
"_acsquare_weights").get_tensor()
# 获取垂直卷积核
ac_ver = fluid.global_scope().find_var(name + "_acver_weights").get_tensor()
# 获取水平卷积核
ac_hor = fluid.global_scope().find_var(name + "_achor_weights").get_tensor()
# 方形卷积结果归一化参数
ac_square_bn_gamma, ac_square_bn_beta, ac_square_bn_mean, ac_square_bn_var = \
get_ac_tensor(bn_name + '_acsquare')
# 垂直卷积结果归一化参数
ac_ver_bn_gamma, ac_ver_bn_beta, ac_ver_bn_mean, ac_ver_bn_var = \
get_ac_tensor(bn_name + '_acver')
# 水平卷积结果归一化参数
ac_hor_bn_gamma, ac_hor_bn_beta, ac_hor_bn_mean, ac_hor_bn_var = \
get_ac_tensor(bn_name + '_achor')
kernels = [np.array(ac_square), np.array(ac_ver), np.array(ac_hor)]
gammas = [
np.array(ac_square_bn_gamma), np.array(ac_ver_bn_gamma),
np.array(ac_hor_bn_gamma)
]
betas = [
np.array(ac_square_bn_beta), np.array(ac_ver_bn_beta),
np.array(ac_hor_bn_beta)
]
means = [
np.array(ac_square_bn_mean), np.array(ac_ver_bn_mean),
np.array(ac_hor_bn_mean)
]
var = [
np.array(ac_square_bn_var), np.array(ac_ver_bn_var),
np.array(ac_hor_bn_var)
]
return {"kernels": kernels, "bn": (gammas, betas, means, var)}
按照公式,基于Numpy进行权值聚合运算。
def kernel_fusion(kernels, gammas, betas, means, var):
"""fuse conv + BN"""
kernel_size_h, kernel_size_w = kernels[0].shape[2:]
square = (gammas[0] / (var[0] + 1e-5)
**0.5).reshape(-1, 1, 1, 1) * kernels[0]
ver = (gammas[1] / (var[1] + 1e-5)**0.5).reshape(-1, 1, 1, 1) * kernels[1]
hor = (gammas[2] / (var[2] + 1e-5)**0.5).reshape(-1, 1, 1, 1) * kernels[2]
b = 0
for i in range(3):
b += -((means[i] * gammas[i]) / (var[i] + 1e-5)**0.5) + betas[i] # eq.7
square[:, :, :, kernel_size_w // 2:kernel_size_w // 2 + 1] += ver
square[:, :, kernel_size_h // 2:kernel_size_h // 2 + 1, :] += hor
return square, b
完整权值聚合运算代码可参考链接:
https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/utils/acnet/weights_aggregator.py
复现效果
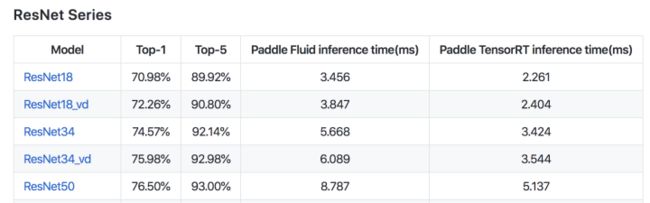
我们的复现方案基于ResNet50在ImageNet上进行了验证,可以观察到精度所有提升,且聚合后的运算量与原版ResNet50结构接近。

如在使用过程中有问题,可加入飞桨官方QQ群交流:1108045677
如果您想详细了解更多飞轮的相关内容,请参见以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞轮开源框架项目地址:
的GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
