pytorch 模型加载与保存
翻译自https://pytorch.org/tutorials/beginner/saving_loading_models.html
保存和与加载模型,有三个核心函数需要熟悉:
torch.save: 保存一个序列化的对象至硬盘,。该函数使用了Python的pickle包用于序列化。模型、张量和各种对象的字典都可以使用该函数保存;torch.load:使用pickle的反序列化功能将序列化的对象文件反序列化到内存。这个功能可以用帮助设备加载数据。torch.nn.Module.load_state_dict:使用一个反序列化的state_dict加载一个模型的参数字典。
文章目录
- 什么是 state_dict
- 与parameters(),named_parameters()的区别
- 用于测试的模型加载与保存
- 保存/加载 `state_dict`(推荐)
- 保存/加载整个模型
- 用于一般checkpoint的模型加载与保存
- 在一个文件内保存多个模型
- 使用不同模型的参数预热模型
- 在设备间保存与加载模型
- GPU上保存,CPU加载
- GPU上保存,CPU加载
- CPU上保存,GPU加载
- 保存`torch.nn.DataParaller`模型
什么是 state_dict
在PyTorch中,一个torch.nn.Module模型的可训练参数(即权重与偏移项)保存在模型的参数(parameters,使用model.parameters()获得)中。一个state_dict就是一个简单的Python字典,将每层映射到其参数张量。注意:,只有具有可训练参数的层(卷积层、线性层等)和注册的缓存(batchnorm的running_running_mean)在模型的state_dict中有接口。优化器对象(torch.optim)也有一个state_dict,其中包含了优化器的信息,以及使用的超参数。
由于state_dict是Python字典,它们可以很容易被保存、更新、更新和加载,增加了PyTroch模型和优化器的组织模块性。
例子,一个分类器模型中的state_dict:
Define model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Initialize model
model = TheModelClass()
# Initialize optimizer
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Print model's state_dict
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# Print optimizer's state_dict
print("Optimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
运行结果:

与parameters(),named_parameters()的区别
model.parameters()和model.named_parameters()返回一个生成器,保存了模型参数。返回的每个元素是模型的一个参数,区别是前者是一个nn.parameter.Parameter的对象,后者是一个长度为2的tuple,(str, nn.parameter.Parameter),即参数的名字和参数):
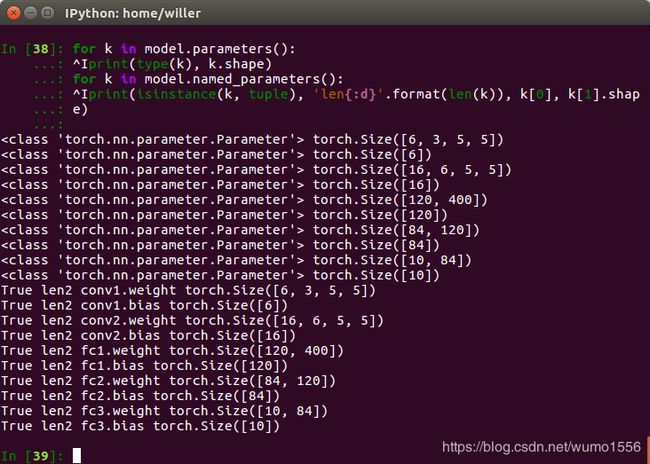
for k in model.parameters():
print(type(k), k.shape)
for k in model.named_parameters():
print(isinstance(k, tuple), 'len{:d}'.format(len(k)), k[0], k[1].shape)
输出为:
用于测试的模型加载与保存
保存/加载 state_dict(推荐)
保存:
torch.save(model.state_dict(), PATH)
加载:
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
当用于保存模型用于测试时,只需要保存模型的可训练参数。使用torch.save()保存模型的state_dict可以在加载模型时给予最大的灵活度,这也是为什么推荐使用的保存模型的方法。
PyTorch约定是使用.pt或.pth后缀命名保存文件。
**切记:**在测试之前, 必须调用model.eval()将dropout和batch normalization层设置为测试模式,不然会导致不一致的结果。
注意:load_state_dict()函数的参数是一个字典对象,不是保存对象的文件名。这意味着,在将保存的state_dict传递给load_state_dict()之前必须将其反序列化。
保存/加载整个模型
保存:
torch.save(model.state_dict(), PATH)
加载:
model = torch.load(PATH)
model.eval()
这种保存/加载的方法使用了最直观的语法,涉及到最少量的程序。使用这种方法保存整个模型使用了Python的pickle模块。这种方法的劣势是,序列化的数据被限制于模型包存时所使用的特定类型和准确的字典结构。这是因为pickle不能保存模型类型本身。而是保存一个加载时使用的包含类的文件的地址。因此,你的程序在其他项目中使用、或改变之后可能会各种崩溃。
PyTorch约定是使用.pt或.pth后缀命名保存文件。
**切记:**在测试之前, 必须调用model.eval()将dropout和batch normalization层设置为测试模式,不然会导致不一致的结果。
用于一般checkpoint的模型加载与保存
保存:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, PATH)
加载:
model = TheModelClass(*args, **kwargs)
optimizer = TheOptimizerClass(*args, **kwargs)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
# - or -
model.train()
当保存一般的、用于恢复训练或测试的checkpoint时,你必须保存比模型的stae_dict更多的内容。保存优化器的stae_dict也很重要,它包含了在模型训练期间更新的缓存和参数。其他希望保存的内容有结束上次训练时的epoch,最新记录的训练损失,以及外部的torch.nn.Embedding层等。
为了保存多个组件,将其组织在字典内,然后使用torch.save()将字典序列化。这样,当你希望是,可以通过查询字典轻松得到保存的组件。
**切记:**在测试之前, 必须调用model.eval()将dropout和batch normalization层设置为测试模式,不然会导致不一致的结果。如果你想恢复训练,可以调用model.train()保证这些层都在训练模式。
在一个文件内保存多个模型
保存:
torch.save({
'modelA_state_dict': modelA.state_dict(),
'modelB_state_dict': modelB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
...
}, PATH)
加载:
modelA = TheModelAClass(*args, **kwargs)
modelB = TheModelBClass(*args, **kwargs)
optimizerA = TheOptimizerAClass(*args, **kwargs)
optimizerB = TheOptimizerBClass(*args, **kwargs)
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict'])
modelB.load_state_dict(checkpoint['modelB_state_dict'])
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])
modelA.eval()
modelB.eval()
# - or -
modelA.train()
modelB.train()
当保存的模型由多个torch.nn.Modules组成时,例如GAN,一个序列到序列的模型,或多个模型的集合,你可以安装保存为checkpoint的方法保存模型。即,保存每个模型的state_dict和对应的优化其组成的字典。之前提到了,你可以通过向字典中添加对恢复训练有帮助的任何项,以保存它们。
PyTorch的约定是使用.tar后缀命名保存这种checkpoint。
**切记:**在测试之前, 必须调用model.eval()将dropout和batch normalization层设置为测试模式,不然会导致不一致的结果。如果你想恢复训练,可以调用model.train()保证这些层都在训练模式。
使用不同模型的参数预热模型
保存:
torch.save(modelA.state_dict(), PATH)
加载:
modelB = TheModelBClass(*args, **kwargs)
modelB.load_state_dict(torch.load(PATH), strict=False)
部分地加载一个模型,或者加载模型的一部分在迁移学习或训练一个新的复杂模型时经常用到。利用训练的参数,即使只有少部分可用,将有助于预热训练模型,并有希望有助于加快模型的收敛速度。
无论记载一个缺少部分keys的部分state_dict,还是加载一个比模型有更多keys的stat_dict,你可以将load_state_dict()中的strict参数设置为False,以忽略没有匹配到的key。
如果你想把一个层参数加载到到其他层,但是一些key并不匹配,你可以改变加载的state_dict中参数key的名字为加载的模型中的对应的key的名字。
在设备间保存与加载模型
GPU上保存,CPU加载
保存:
torch.save(model.state_dict(), PATH)
加载:
device = torch.device('cpu')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location=device))
当在CPU上加载在GPU上训练的模型时,将torch.load()函数中的map_location参数设置为torch.device('cpu')。在这种情况下,保存这些张量的内存被自动重新映射到CPU上。
GPU上保存,CPU加载
保存:
torch.save(model.state_dict(), PATH)
加载:
device = torch.device('cuda')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.to(device)
当在GPU上加载一个在GPU上训练并保存的模型时,使用model.to(torch.device('cuda')将初始化的模型转换为CUDA优化的模型。同样,确保在所有模型的输入上使用.to(torch.device('cuda'))函数以为模型准备数据。注意:,调用my_tensor.to(device)返回一个在GPU上my_tensor的拷贝。这没有覆盖my_tensor。因此,记得手动覆盖张量:
my_tensor = my_tensor.to(torch.device('cuda'))
CPU上保存,GPU加载
保存:
torch.save(model.state_dict(), PATH)
加载:
device = torch.device('cuda')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location='cuda:0'))
model.to(device)
当在GPU上加载一个在CPU上训练并保存的模型是,将torch.load()中的map_location参数设置为cuda:device_id。这将模型加载到给定的GPU设备。然后,切记调用model.to(torch.device('cuda'))以将模型的参数张量转换为CUAD张量。最后,确保在所有模型的输入上使用.to(torch.device('cuda'))函数以为模型准备数据。注意:,调用my_tensor.to(device)返回一个在GPU上my_tensor的拷贝。这没有覆盖my_tensor。因此,记得手动覆盖张量:
my_tensor = my_tensor.to(torch.device('cuda'))
保存torch.nn.DataParaller模型
保存:
torch.save(model.module.state_dict(), PATH)
加载:
# load to whatever device you want
torch.nn.DataPatallel是一个模型的wrapper,保证了并行GPU的使用。为了一般地保存DtaParallel模型,保存model.module.state_dict(). 这样,你有将模型加载至任意设备的灵活性。