MySql存储引擎和索引原理
转载 https://blog.csdn.net/tongdanping/article/details/79878302
注意:
1、索引需要占用磁盘空间,因此在创建索引时要考虑到磁盘空间是否足够
2、创建索引时需要对表加锁,因此实际操作中需要在业务空闲期间进行
MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,B+Tree索引,哈希索引,全文索引等等,
索引实现的原理:
1.哈希索引:
只有memory(内存)存储引擎支持哈希索引,哈希索引用索引列的计算该值的hashCode,然后在hashCode相应的位置存执
该值所在行数据的物理位置,因为使用散列算法,所以访问速度非常快,但是一个值只能对应一个hashCode,
而且是散列的分布方式,因次哈希索引不支持范围查找和排序的功能
2.全文索引:
仅用于MyISAM和InnoDB,针对较大的数据,生成全文索引非常消耗时间和控件,对于文本的大对象,如果使用普通索引,
那么匹配文本前几个字符还是可行的,但是要匹配文本中间的几个单词,就要使用like,这样会需要很长的时间来执行
(由于前面是模糊的,所以不能利用索引的顺序,必须一个个去找,看是否满足条件。这样会导致全索引扫描或者全表扫描)
这个时候就需要使用全文索引,再生成全文索引时候,会为文本生成一份单词的清单,在索引时候根据这个单词的清单来索引
全文索引的查询也有自己特殊的语法,而不能使用LIKE %查询字符串%的模糊查询语法
SELECT * FROM table_name MATCH(ft_index) AGAINST('查询字符串');3. BTree索引和B+ Tree索引 转载https://www.jianshu.com/p/0371c9569736
叶子节点就是没有子节点的节点,非叶子节点就是有子节点的节点
① BTree索引
B树是一种多路自平衡搜索树,它类似普通的二叉树,但是B书允许每个节点有更多的子节点。B树示意图如下:
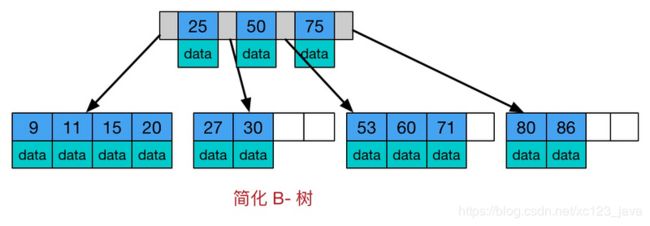
B树的特点:
(1)所有键值分布在整个树中
(2)任何关键字出现且只出现在一个节点中
(3)搜索有可能在非叶子节点结束
(4)在关键字全集内做一次查找,性能逼近二分查找算法
为了提升效率,要尽量减少磁盘IO的次数。实际过程中,磁盘并不是每次严格按需读取,而是每次都会预读。
磁盘读取完需要的数据后,会按顺序再多读一部分数据到内存中,这样做的理论依据是计算机科学中注明的局部性原理:
(1)由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),
因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
(2)MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改)。
linux 默认页大小为4K。
B-Tree借助计算机磁盘预读机制:
每次新建节点的时候,都是申请一个页的空间,所以没查找一个节点只需要一次I/O;因为实际应用当中,节点深度会很少,
所以查找效率很高.

查找数字29: 原文:https://blog.csdn.net/endlu/article/details/51720299
(1) 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作1次】
(2) 此时内存中有两个文件名17,35和三个存储其他磁盘页面地址的数据。根据算法我们发现17<29<35,
因此我们找到指针p2。
(3) 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作2次】
(4) 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现26<29<30,
因此我们找到指针p2。
(5) 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作3次】
(6) 此时内存中有两个文件名28,29。根据算法我们查找到文件29,并定位了该文件内存的磁盘地址。
从图中也可以看到,B+树与B树的不同在于:
(1)所有关键字存储在叶子节点,非叶子节点不存储真正的data
(2)为所有叶子节点增加了一个链指针
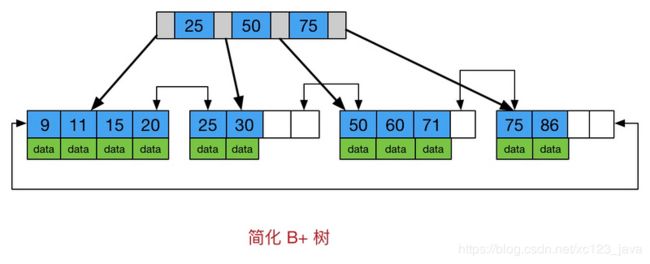
为什么mysql的索引使用B+树而不是B树呢??
(1)B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。
(2)mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。
聚集索引
InnoDB存储引擎表是索引组织表,即数据按照主键顺序存放。而聚集索引就是按照每张表的主键构造一棵B+树,同时叶子节点存放的是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。索引聚集索引可以在B+树索引的叶子节点上直接找到数据。由于定义了数据的逻辑顺序,聚集索引能够特别快的访问针对范围值的查询。

辅助索引
对于辅助索引,叶子节点并不包含的是行记录的全部数据。叶子节点除了包含键值之外,每个叶子结点的索引行中还包含了一个书签。这个书签就是相对应行数据的聚集索引键。
辅助索引的存在不会影响数据在聚集索引中的组织,因此每张表可以有多个辅助索引。

联合索引
联合索引是指对表上的多个列进行索引。
例
create tablebuy_log (
user_id int Unsigned not null,
num int,
buy_date Date
)
//创建两个索引:user_id,user_id_2
Alter table buy_log add key(user_id); //user_id
Alter table buy_log add (user_id,num,buy_date) //userid_2
1、select * from buy_log where user_id=2;,经过EXPLAIN分析会使用user_id索引,因为该辅助索引叶子节点包含单个键值,理论上一个页能存放更多的记录
2、select * from buy_log where user_id =1 and num=2 order by buy_date Desc limit 3,经过EXPLAIN分析会使用(user_id,num,buy_date)联合索引user_id_2,因为联合索引已经对buy_date排好序了,不要再对buy_date做一次额外的排序了。如果强制索引索引userid,经过分析,会做一次排序操作Useing filesort,即对buy_date排序,因为userid索引中的buy_date是无序的
3、select * from buy_log where user_id =1 order by buy_date Desc limit 3,经过EXPLAIN分析会使用user_id索引,不会使用联合索引,并进行一次排序操作,因为(user_id,buy_date)是无序的(虽然存在两个索引都可以用的情况,但是sql优化器选择了user_id,因为该索引只包含一个键值,理论上一个页能存放更多的记录)
优化器选择不适用索引
即不使用索引去查找数据,而是通过扫描聚集索引,即直接进行全表的扫描得到数据。这种情况多发生于范围查找,join链接等情况.下面通过订单表举例说明一下:
select * from order_details where order_id > 10000 and order_id<102000;
该表有1个联合索引(order_id,product_id),还有1个单个索引(order_id)
即查找订单号大于10000小于102000的订单详情,,上面这句话显然可以通过索引(order_id)进行数据的查找,但是经过EXPLAIN分析,优化器并没有选择order_id索引查数据,而是选择了primary聚集索引,也就是表扫描。因为用户选择的数据是整行数据,辅助索引不能覆盖我们要查询的信息,因为对orderorder_idid索引查询到指定数据后,还需要进行一次书签访问来查找整行数据信息。虽然order_id索引中的数据是顺序存放的,但是再一次书签查找的数据是无序的了,因此变为了磁盘上的离散读操作。如果访问的数据量很少(20%左右),优化器还是会选择聚集索引来查找数据的。因为顺序读远远快于离散度
不能进行索引覆盖的情况下,优化器选择辅助索引的情况为:通过辅助索引查找的数据是少量的,但是如果磁盘是固态磁盘,随机读操作很快,并且确认辅助索引可带来更好的性能,可使用关键字FORCE INDEX来强制使用某个索引
8、其他不使用索引的情况
- Like的参数以通配符开头时 like '%你好%'
- 使用!= 或 <> 操作符时
- 索引列参与计算
- 使用is not null
- 使用or来连接条件
MySql存储引擎 转载 https://blog.csdn.net/qq_34417408/article/details/80957620
(1):MyISAM存储引擎
不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用
基本上可以用这个引擎来创建表
(2)InnoDB存储引擎*
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM引擎,写的处理效率会差一些,
并且会占用更多的磁盘空间以保留数据和索引。
InnoDB存储引擎的特点:支持自动增长列,支持外键约束
(3):MEMORY存储引擎
Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的
表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
(4)MERGE存储引擎
Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,
对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。