Python3爬虫学习-爬取图片批量下载 XPATH
最近在研究爬虫,爬取好多网站的数据,下面就以爬取图片网站照片为例,来让大家学习,希望大家多交流。总的来说爬虫不难,会python的简单语法,会xpath提取网页需要的信息,就可以很快的爬取网站的图片,同时也希望以此来激起大家学习的兴趣。
文章导航
- 一、环境
- 二、源码
- 三、部分源码分析
- 3.1 获取网站html网页数据源码
- 3.2 返回网页源码信息数据
- 3.3 提取网页中自己需要的信息--有多少页
- 3.4 循环进入某一页
- 3.5 创建文件夹,循环进入每一个图片的第二层页面
一、环境
**目标网站:**图片网
**环境:**Python3.0以上版本 windows亲测可以,linux下应该也是没有问题
**第三方模块:**requests、xpath
**测试:**保存下面代码为xx.py,使用 python xx.py 或IDE或者pycharm直接运行即可。
二、源码
如需完整的工程源码请点击此处===》
# -*- coding: utf-8 -*-
# 作者: 废人一枚
# 出自: 北京
# 创建时间: 12:22
import requests
import os
import time
from lxml import etree
requests.adapters.DEFAULT_RETRIES = 5
s = requests.session()
s.keep_alive = False
all_url = 'http://www.tupian.com'
# 图片保存地址,修改为你保存的路径
#path = 'D:/python/爬虫/MZ/'
# 获取每一类的网址
same_url = 'http://www.tupian.com/page/' # 也可以指定其它的路径下的图片
# http请求头 User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36
Hostreferer = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Referer': 'http://www.tupian.com'
}
# 此请求头Referer破解盗图链接
Picreferer = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Referer': 'http://i3.mmzztt.com'
}
# 对mzitu主页所有url发起请求,将返回的HTML数据保存,便于解析
index_html = requests.get(all_url, headers=Hostreferer)
#print(index_html.text)
# 获取最大页数
content = etree.HTML(index_html.text)
page_num = content.xpath("//div[@class='nav-links']/a/text()")
max_page = page_num[-2]
print("图片总共页码为:"+max_page)
for n in range(1, int(max_page) + 1):
# 拼接当前url eg:https://www.tupian.com/page/1
ul = same_url + str(n)
print(ul)
time.sleep(1)
# 分别对当前类每一页第一层url发起请求,进入第n页
two_html = requests.get(ul, headers=Hostreferer)
#print(two_html.text)
content = etree.HTML(two_html.text)
urls = content.xpath("//div[@class='postlist']/ul/li/a/@href")
names = content.xpath("//div[@class='postlist']/ul/li/a/img/@alt")
k = 0
for title in names:
print(title)
print("@@@@@@@@@2")
print(k)
print(urls[k])
url_jpg = urls[k]
k = k + 1
if k <=2:
continue
print("准备抓取:" + str(title))
# windows不能创建带?的目录,添加判断逻辑
if (os.path.exists(path + title.strip().replace('?', ''))):
# print('目录已存在')
flag = 1
else:
os.makedirs(path + title.strip().replace('?', ''))
flag = 0
# 切换到上一步创建的目录
os.chdir(path + title.strip().replace('?', ''))
# 每个图片对应的url
print(url_jpg)
three_html = requests.get(url_jpg, headers=Hostreferer)
#获取当前页图片的张数
content = etree.HTML(three_html.text)
page_num = content.xpath("//div[@class='pagenavi']/a/span/text()")
print(page_num[-2])
pic_max = page_num[-2]
# for i in page_num:
# print(i)
print("总共找到有" + pic_max + "张图片")
# 遍历每张图片的url
for num in range(1, int(pic_max) + 1):
#time.sleep(2)
# 拼接每张图片的url
pic = url_jpg + '/' + str(num)
print(pic)
#发起请求
try:
html = requests.get(pic, headers=Hostreferer, timeout=15)
except requests.exceptions.RequestException as e:
print(e)
continue
content = etree.HTML(html.text)
urls_jpg = content.xpath("//div[@class='main-image']/p/a/img/@src")
time.sleep(2)
print(urls_jpg[0])
try:
html = requests.get(urls_jpg[0], headers=Picreferer, timeout=15)
except requests.exceptions.RequestException as e:
print(e)
continue
file_name = urls_jpg[0][-9:]
# 保存图片
with open(file_name, 'wb') as f:
f.write(html.content)
f.flush()
f.close()
print('下载全部完成')
三、部分源码分析
3.1 获取网站html网页数据源码
# -*- coding: utf-8 -*-
# 作者: 废人一枚
# 出自: 北京
# 创建时间: 22:42
import os, traceback
import requests
if __name__ == '__main__':
# 获取每一类的网址
same_url = 'https://www.tupian.com/page/' # 也可以指定其它的路径下的图片
# http请求头 User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36
Hostreferer = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Referer': 'http://www.tupian.com'
}
# 用get方法打开url并发送headers
html = requests.get(same_url, headers=Hostreferer)
# 打印结果 .text是打印出文本信息即源码
print(html.text)
其中 User-Agent 的获取可以参考以下链接进行修改自己浏览器的信息
https://blog.csdn.net/xunxue1523/article/details/104579264
3.2 返回网页源码信息数据

3.3 提取网页中自己需要的信息–有多少页
- xpath获取
xpath路径://div[@class='nav-links']/a/text()

# -*- coding: utf-8 -*-
# 作者: 废人一枚
# 出自: 北京
# 创建时间: 22:42
import os, traceback
import requests
from lxml import etree
if __name__ == '__main__':
# 获取每一类的网址
same_url = 'http://www.tupian.com' # 也可以指定其它的路径下的图片
# http请求头 User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36
Hostreferer = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Referer': 'http://www.tupian.com'
}
# 用get方法打开url并发送headers
index_html = requests.get(same_url, headers=Hostreferer)
# 打印结果 .text是打印出文本信息即源码
print(index_html.text)
# 获取最大页数
content = etree.HTML(index_html.text)
page_num = content.xpath("//div[@class='nav-links']/a/text()")
max_page = page_num[-2]
print("图片总共页码为:" + max_page)

3.4 循环进入某一页
-
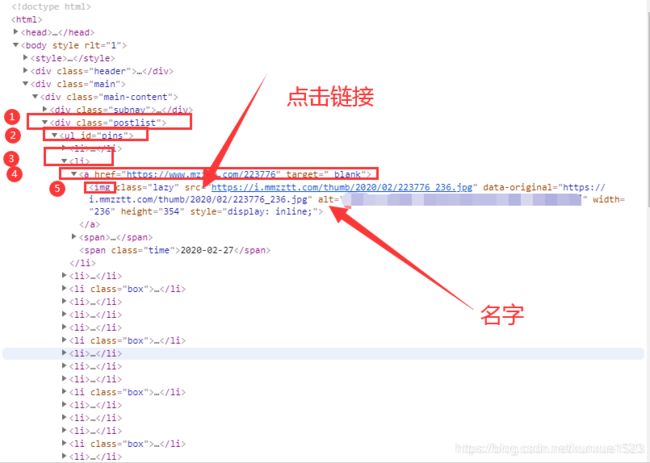
提取一页上面图片的链接地址:
//div[@class='postlist']/ul/li/a/@href -
提取一页上面图片的链接地址:
//div[@class='postlist']/ul/li/a/img/@alt
-
源码:
# -*- coding: utf-8 -*-
# 作者: 废人一枚
# 出自: 北京
# 创建时间: 22:42
import os, traceback
import requests
from lxml import etree
import time
if __name__ == '__main__':
# 获取每一类的网址
all_url = 'http://www.tupian.com'
same_url = 'http://www.tupian.com/page/' # 也可以指定其它的路径下的图片
# http请求头 User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36
Hostreferer = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Referer': 'http://www.tupian.com'
}
# 用get方法打开url并发送headers
index_html = requests.get(all_url, headers=Hostreferer)
# 打印结果 .text是打印出文本信息即源码
print(index_html.text)
# 获取最大页数
content = etree.HTML(index_html.text)
page_num = content.xpath("//div[@class='nav-links']/a/text()")
max_page = page_num[-2]
print("图片总共页码为:" + max_page)
for n in range(1, int(max_page) + 1):
# 拼接当前url eg:https://www.mzitu.com/page/1
ul = same_url + str(n)
print(ul)
time.sleep(1)
# 分别对当前类每一页第一层url发起请求,进入第n页
two_html = requests.get(ul, headers=Hostreferer)
# print(two_html.text)
content = etree.HTML(two_html.text)
urls = content.xpath("//div[@class='postlist']/ul/li/a/@href")
names = content.xpath("//div[@class='postlist']/ul/li/a/img/@alt")
k = 0
for title in names:
print(title)
print("@@@@@@@@@2")
print(k)
print(urls[k])
url_jpg = urls[k]
print("准备抓取:" + str(title))
print('下载全部完成')
3.5 创建文件夹,循环进入每一个图片的第二层页面
- 创建目录 os.makedirs
- 获取页面 requests.get
-源码:
# windows不能创建带?的目录,添加判断逻辑
if (os.path.exists(path + title.strip().replace('?', ''))):
# print('目录已存在')
flag = 1
else:
os.makedirs(path + title.strip().replace('?', ''))
flag = 0
# 切换到上一步创建的目录
os.chdir(path + title.strip().replace('?', ''))
# 每个图片对应的url
print(url_jpg)
three_html = requests.get(url_jpg, headers=Hostreferer)
点进一个图之后,发现他是每个页面显示一个图片,这时我们需要知道总页数,eg:http://www.tupian.com/216244是某个图的第一页,后面的页数都是再后面跟/和数字http://www.tupian.com/216244/2 (第二页),那么很简单了,我们只需要找到他一共多少页,然后用循环组成页数就可以了。
- xpath获取第二页面的图片数 :
//div[@class='pagenavi']/a/span/text()
- xpath获取第二页面所有图片的每个图片链接:
//div[@class='main-image']/p/a/img/@src

- 保存图片至文件
with open(file_name, 'wb') as f:
f.write(html.content)
f.flush()
f.close()
基本的代码分析完了,这里核心就是是xpath代码分析,详细xpath点击进入学习
如果大家喜欢,麻烦给个关注,欢迎大家一起交流,谢谢。