adaboost + cascade 以及在 opencv 中的使用 ------ 模型训练
本文主要说明如何时候用opencv中自带的工具opencv_createsamples和opencv_traincascade训练adaboost + cascade模型
Boost
核心思想
通过对原始数据集采样时给之前分错的数据更大的比例,使得每级分类器更加关注于前面分类器分错的数据。最后多个弱分类器联合起来,产生一个强分类器。
主要过程 (DAB)
- 对原始数据集按一定权重(概率)进行采样,获得新的数据集,用新数据集训练弱分类器
- 使用弱分类器分类,分类错误的数据的权重调高,分类正确权重调低,再次按权重重新采样resample,训练弱分类器
- 重复过程2,直到分类器达到指定的个数或者识别绿率达到要求或其他终止条件
- 最终的分类器就是各个弱分类器加权求和获得最终结果
特点
- 串联训练,并联识别:训练的时候,下一个分类器以来上一个分类起训练的结果来调整权重,所以是串联结构(不可并行);识别的时候所有分类器一起识别,最后结果加权获得,是并联结构。
- 每级分类器都很简单:每级分类器通常使用stump分类器,就是只有一层的决策树。opencv使用决策树作为弱分类器。
- Boost的很多版本: DAB,RAB,GAB,Logit Boost 它们的区别主要在于弱分类器(主要是 返回的结果是离散还是连续的 和 权重是用来resample还是做分类器拟合时的加权 这两点)和 权重的权重的更新公式上。具体内容参考 http://www.cnblogs.com/jcchen1987/p/4581651.html
Cascade
基本思想
cascade通过若各干个 adaboost强分类器 串联得到一个新的分类器,只有所有的adaboost分类器都认为是positive,最终结果才是positive,否则都是negative,以此大幅降低FP rate,而TP rate基本不变。
目标
二类分类器识别出是positive的可能有两种情况,一种是原本图像就是positive的,这种为TP(true positive),另一种是原本是negative的被错识别了,这种为FP(false positive)。
TP rate = TP的图片数 / positive的图片总数
FP rate = FP的图片数 / negative的图片总数
直观上理解,如果分类器宽松一点,那么不论正样本还是负样本都更容易通过分类器(被识别为positive),FP 和 TP 都会很大,反之有可能都会很小。cascade一定程度上可以解决这个矛盾。
过程
- 从总数据集中选择 numPos 个positive数据和 numNeg 个negative数据集一起构成训练数据集,训练adaboost强分类器,保证它的 TP rate 很大(比如min_TP_rate=0.995),但是 FP rate 却不是很小(比如max_FP_rate=0.5)。
- 从训练数据集中删除上一个adaboost识别错误的positive数据,从总数据集中加入与删除数据数量相同的新的positive数据,训练adaboost强分类器,同样保证TP rate很大,而FP rate不是很小。
- 重复第2步,直到达到指定的级数(numStages,比如为20)或其他终止条件(达到acceptanceRatioBreakValue)
- 最终串联获得分类器 TP > (min_TP_rate)^numStages = (0.995)^20 = 0.9046; FP < (max_FP_rate)^numStages = (0.5)^20 = 9.5e-7
opencv中的特点
- opencv中cascade的每一级被称为一个stage,每个stage都要训练一个adaboost分类器。
- opencv训练中的参数minHitRate和输出的HR就是指TP rate; maxFalseAlarmRate 和 FA 就是FP rate
- 由于cascade每个阶段都要引入新的positive数据,所以总数据集中positve数据的数量要符合一下公式。
numPos + (1-minHitRate) * numPos * (numStages - 1) + s <= 总的positve数据数1). 由于所有的positive数据都存在于vec file中,所以所有的positive数据的数量就是vec文件中的数据数
2). 每一个stage删除的数据最大为(1-minHitRate) * numPos个
3). s 是skipped positive data就是因为图片质量不合格而被忽略的positive数据的数量
opencv 中的 boost + cascade的工具的使用
可以参考官方文档
1. http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html
2. http://docs.opencv.org/2.4.13/doc/user_guide/ug_traincascade.html#creating-training-set-as-a-collection-of-png-images
opencv_createsamples
opencv_createsamples 有以下三个作用:
- 从一张object图片和一个背景图片(negative)集中创建一个positive数据集,生成png/jpg的图片或包含全部图片数据的二进制vec文件
- 转化标记好的 positive 图片数据文件为vec文件,(vec格式是opencv训练用得到的数据格式)
- 显示vec文件中的内容
opencv_createsamples 使用的例子:
- 比如要识别某个logo,通过一张logo图片和一个背景图片(neg)数据集生成一个带logo的图片数据集(pos),原理是通过logo图片经过一定的变换后(比如旋转),嵌入到背景图片中,获得不同背景下的logo图片。
opencv_createsamples -img logo.png -bg bg.txt -info output/annotations.lst -maxxangle \
0.1 -maxyangle 0.1 -maxzangle 0.1 -num 100 -w 200 -h 200 -show-img: 指定输入的logo图片
-bg: bg.txt里面每行记录着一个背景图片的相对路径(可以在背景图片数据集目录中使用 ls > bg.txt 生成)
-info: 指定生成的label文件的位置,注意必须要有一层父目录,不能是./annotations.lst
-maxxangle: 指定在x方向上的最大旋转角
-num: 指定生成的带logo图片的数量,因为logo图片可以旋转,插入背景图片的位置也不确定,所以这个数可以大于背景图片数量
-w -h: logo图片被放缩到的宽和高
-show: 一张一张显示生成的图片,会把整个背景图和插入的logo图片一起显示出来,点击图片后按ESC退出查看- 上面方法获得是一个jpg格式的的postive数据集,如果要生成png格式的要加一个-pngout的参数,另外生成的label文件(annotations.lst)的格式也不一样。
opencv_createsamples -img logo.png -bg bg.txt -info output/annotations.lst -maxxangle \
0.1 -maxyangle 0.1 -maxzangle 0.1 -num 2 -w 200 -h 200 -show -pngout- 由于 opencv_traincascade 或 opencv_haarcascade 训练模型的输入的positve数据格式是.vec格式,所以可以在这里直接选择创建vec格式的postive数据集。
opencv_createsamples -img logo.png -bg bg.txt -vec img.vec -maxxangle 0.1 -maxyangle \
0.1 -maxzangle 0.1 -num 100 -show- 有些时候我们是直接获取的postive数据集,而不是通过opencv_createsamples生成的,就要自己写label文件(info.dat)生成vec了。
opencv_createsamples -info info.dat -vec pos.vec -num 111info.dat的格式如下:
pos/img1.jpg 1 140 100 45 45
pos/img2.jpg 2 100 200 50 50 50 30 25 25每一行代表一张图片,第一列是图片相对info.dat文件的相对路径,第二列是该图片里有多少个需识别的物体(ROI),
后面每四列表示一个ROI的rect区域(左上角x, 左上角y, weight, height)
5. 显示vec文件中的内容
opencv_createsamples -vec pos.vecopencv_createsamples 参数的解释
# 参数
# [-info ] 记录生成图片对应的的annotation文件位置,记录生成的pos图片中log.png插入的位置.
注意该文件必须指定到上一层目录,比如/home/user/output/annotations.lst 或者 output/annotations.lst,
而不能./annotations.lst. 不指定将不会生成
# [-img ] 只包含要识别的object的小图片,就是将该图片插入背景图片中
# [-vec ] 生成的.vec文件的名称,默认不生成。是opencv_traincascade. opencv_traincascade 输入文件的格式
# [-bg ]
# [-num ]生成图片的个数,默认一个bg生成一个
# [-bgcolor ]
# [-inv] [-randinv] [-bgthresh ]
# [-maxidev ] 亮度参数
# [-maxxangle ] object最大的x方向上旋转的角度
# [-maxyangle ]
# [-maxzangle ]
# [-show []] 是否显示生成图片,默认不显示
# [-w ] 生成图片的大小w
# [-h ]
# [-pngoutput] 是否生成png图片,默认生成jpg格式的图片
# 准备的文件只有背景图片和指定它们路径的bg.txt以及object的图片logo.png
# 生成文件和是否使用-pngout参数相关,具体参考官方说明opencv_traincascade
opencv_traincascade 作用
使用它训练 adaboost + cascade 的模型
opencv_traincascade 使用实例
下面是个最简单的使用,这几个参数一般是一定要使用的
opencv_traincascade -data model/ -vec plane.vec -bg bg.txt -numPos 6750 -numNeg 6750-data: 生成的模型和记录每个stage的xml文件(可以断点继续训练)的目录,不存在会报错
-vec: postive图片集生成的vec文件
-bg: 和前面的一样,用于指定背景图片集(negative)位置的文件,每一行是一个图片的相对位置
-numPos: 每个stage(cascade的一级即一个adaboost强分类器)中参与训练的正样本数量,要满足上面所说的公式
-numNeg: 每个stage中参与训练的负样本的数量,负样本是从bg.txt中指定的背景图片中截取的,所以大小可以比背景图片的总数大然后可以看到输出
---------------------------------------------------------------------------------
PARAMETERS:
cascadeDirName: model/
vecFileName: plane.vec
bgFileName: bg.txt
numPos: 6750
numNeg: 6750
numStages: 20
precalcValBufSize[Mb] : 1024
precalcIdxBufSize[Mb] : 1024
acceptanceRatioBreakValue : -1
stageType: BOOST
featureType: HAAR
sampleWidth: 24
sampleHeight: 24
boostType: GAB
minHitRate: 0.995
maxFalseAlarmRate: 0.5
weightTrimRate: 0.95
maxDepth: 1
maxWeakCount: 100
mode: BASIC以上各参数除了指定的几个以外都是默认值,含义可以参见 参数说明
opencv_traincascade参数说明
官方文档
# -data: 生成的模型和记录每个stage的xml文件(可以断点继续训练)的目录,不存在会报错
# -vec: postive图片集生成的vec文件
# -bg: 和前面的一样,用于指定背景图片集(negative)位置的文件,每一行是一个图片的相对位置
# -numPos: 每个stage(cascade的一级即一个adaboost强分类器)中参与训练的正样本数量,要满足公式:
# numPos + (1-minHitRate) * numPos * (numStages - 1) + s <= 总的positve数据数
# -numNeg: 每个stage中参与训练的负样本的数量,负样本是从bg.txt中指定的背景图片中截取的,所以大小可以比背景图片的总数大
# [-numStages ] cascade的级数
# [-precalcValBufSize ] 缓存大小,用于存储预先计算的特征值
# [-precalcIdxBufSize ] 缓存大小,用于存储预先计算的特征索引
# [-baseFormatSave] 是否保存按opencv_haarcascade的格式(old format)保存model文件
# [-acceptanceRatioBreakValue = -1>]
#--cascadeParams--
# [-stageType ] 级别(stage)参数。目前只支持将BOOST分类器作为级别的类型。
# [-featureType <{HAAR(default), LBP, HOG}>] 提取的特征类型
# [-w ] 训练窗口的大小,必须跟vec中训练样本的大小一致
# [-h ]
#--boostParams--
# [-bt <{DAB, RAB, LB, GAB(default)}>] adaboost的种类
# [-minHitRate = 0.995>] adaboost要达到的min TP rate
# [-maxFalseAlarmRate ] adaboost要达到的max FP rate
# [-weightTrimRate ] 影响参与训练的样本,不管是正样本还是负样本,当更新完样本权重之后,
# 将样本权重按照从小到大的顺序排列,当从后累加样本权重不小于weightTrimWeight时前面的样本就不参与后面的训练了
# [-maxDepth ] adaboost里每个弱分类器(决策树)的最大深度
# [-maxWeakCount ] adaboost里弱分类器的最大个数
#--haarFeatureParams--
# [-mode
# ALL 使用所有右上特征和45度旋转特征
#--lbpFeatureParams--
#--HOGFeatureParams-- 当 opencv_traincascade 程序训练结束以后,训练好的级联分类器将存储于文件cascade.xml中,这个文件位于 -data 指定的目录中。这个目录中的其他文件是训练的中间结果,当训练程序被中断后,再重新运行训练程序将读入之前的训练结果,而不需从头重新训练。训练结束后,你可以删除这些中间文件。
参数选择
- 正负样本比例问题:1:4或者1:5训练出来的分类器要优于1:1或者1:10
- numPos+(numStages-1)numPos(1-minHitRate)《= 准备的positive样本总数
常见错误
- numPos设置不能使用vec中全部的样本,必须满足上面说的公式,比如,vec中positive的总样本数为7000, numStages=20, minHitRate=0.995,由于numPos + numPos*(1-minHitRate)* (numStages-1) + s <= 总数,计算可得 numPos <= 6392。
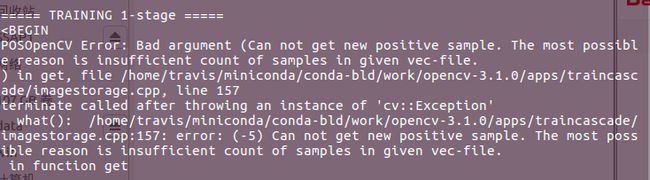
- bg.txt读取错误,因为windows下的换行符是\r\n,而linux是\n,可能是这个原因导致。又或者是相对路径出了问题,报错如下:

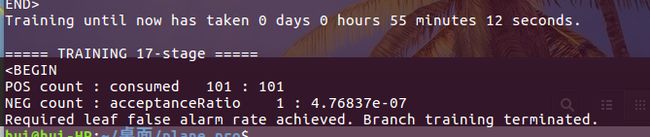
- 如果出现下面的问题应该是训练的结果很OK,没有达到指定的stage数就停止了,输出如下:
visit
http://blog.csdn.net/liulina603/article/details/8479338
http://blog.csdn.net/xidianzhimeng/article/details/42147601
http://blog.csdn.net/njzhujinhua/article/details/38377191
http://docs.opencv.org/2.4.13/modules/ml/doc/boosting.html
http://www.cnblogs.com/jcchen1987/p/4581651.html
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html
http://docs.opencv.org/2.4.13/modules/ml/doc/boosting.html
<<统计学习方法>> adaboost
<<机器学习实战>> adaboost