Python语法细节
一:2.X和3.X
1:raw_input和input
help(raw_input)
Help on built-in function raw_input in module __builtin__:
raw_input(...)
raw_input([prompt]) -> string
Read a string from standard input. The trailing newline is stripped.
If the user hits EOF (Unix: Ctl-D, Windows: Ctl-Z+Return), raise EOFError.
On Unix, GNU readline is used if enabled. The prompt string, if given,
is printed without a trailing newline before reading.
help(input)
Help on built-in function input in module builtins:
input(prompt=None, /)
Read a string from standard input. The trailing newline is stripped.
The prompt string, if given, is printed to standard output without a
trailing newline before reading input.
If the user hits EOF (*nix: Ctrl-D, Windows: Ctrl-Z+Return), raise EOFError.
On *nix systems, readline is used if available.
细节:和print不一样,这两兄弟不会自动给你输出一个换行。(这个东西一般拿来读取用户输入,比如您的名字:___,本来就不需要回车嘛)
这两兄弟也不会读入用户最后敲的换行。
读入的只有字符串,如果要用户输入个整数怎么办?可以用eval函数执行以下那个字符串,就得到整数了嘛:
a = input("输入一个数")
b = eval(a)
print(b + 5)2.print和print()
在2.X里面print是一个语句,3.X里面print是一个函数。但是在2.X里面你用print(a)也会奏效,原因是解释器把后面的括号当做元组了,但是这个元组只有一个元素还没有逗号,不是个合格的元组,所以括号被忽略。这算是意外实现的“向后兼容”吧……
Tips:无论是2.X还是3.X,print作用于一个没有括号的元组的效果都是用空格分隔各个元素。
3.截尾除法
2.X里面/就是截尾除法,3.X里面//才是截尾除法。
2.X : 3 / 5 == 0
3.X : 3 // 5 == 0, 3 / 5 = 0.6
(Python真是任性啊,这种东西都敢改动,真是仗着用户多啊……)
死记吧,3 > 2, 所以3.X是两个/……
4.round函数
整数的强制类型转换int()对于浮点数是直接截尾,要实现四舍五入到小数点后面几位就要用round函数了。
3.X里面如果没有指明保留几位,那么round会返回四舍五入到整数位的整数。
2.X里面如果没有指明保留到几位,返回的是四舍五入到整数的数,不过是以浮点数的形式……真无语,就是要写一个3.0……
如果指明了保留到几位,那么就是一样的了。
顺版说一下,事实上,要实现保留到整数位的四舍五入,其实只要用int(x + 0.5)就可以了……
二:Python的下标
Python下标的有效范围是[-len, len),len是list、tuple、string的长度。
在分片操作slice中,负数的下标总会先转为正的(加上len),然后再进行运算。
之所以在下标里面引入负数,估计是为了利用-1来得到最后的一个元素。"helo"[-1]写起来简洁。
但是这样也存在一个问题:
-1在很多时候是查找失败的标志。
print("hi".find('o'))的结果是-1.如果有人用find的返回值来作为下标,那就悲剧了。
难道是因为这个原因,str.index(element)在没找到的时候就会抛出异常?
有得必有失吧……
三:序列的分片
分片操作得到的永远是一个序列,即使只有一个元素。
[1, 3, 6][1:2] ==> [3]
另外,只有一个元素的list没有逗号,而只有一个元素的元组必须有逗号:
isinstance((1, ), tuple) == Trueisinstance((1 ), tuple) == False
另外,如果序列分片、索引操作出现在等号左侧,是在原处修改序列;如果序列分片、索引出现在等号右侧,是复制一个序列/序列片段(和原来的序列没有关系了,只是值 相等)


这就引发了一个问题:在for循环遍历一个链表且对它进行原处修改的时候,不能直接for x in L,只能for x in len(L),然后用L[x]进行操作。
有点像C++的范围for循环加不加引用的区别。
Tips:函数的参数传递的过程也就是一个赋值的过程
四:字符串是不可变的
字符串是不可变对象,看上去像是对字符串进行修改的split/replace/strip等函数,都是返回一个修改后的字符串,而原来的字符串保持不变。
元组tuple也是不可修改的。
列表是可以原处修改的,与字符串相反,所有改变列表的操作都不会返回什么(严格地说返回None……)
一个例外是作用于列表的内置函数sorted([1, 3, 2, 4]) ==> [1, 2, 3, 4],既然它返回一个排好了序的列表,我们也就知道它不会改变原来的列表了。
一个Tricky的题:
([3, 2, 1, 4].sort() == sorted([3, 2, 1, 4])) == False
Tips:由于字符串是不可变对象,如果经常改动字符串,效率会很低。这个时候可以先把字符串打散成列表,操作完之后再拼接起来。
打散:list("hello)或者"hello, world".split()
拼接:"".join(list)
五:逗号即是元组
x, y, z ==> (x, y, z)
这个东西在两个地方用到:
交换引用x, y = y, x就回达到交换的效果,不需要再设置中间变量了。(我猜对于元组的赋值,解释器会先为第二个元组全部建立中间变量)
返回元组:在函数末尾直接return x, y, z <==> return (x, y, z)
六:if-else配对
Python的缩进有语法意义(所以就不需要分号结尾了,但是,没有分号的后果就是要引入pass来占位),if-else的配对是按照缩进来的,而不是像C/C++一样就近配对。
if 3 > 5:
if 5 < 9:
print(1)
else:
print(2)(其实看起来也简洁明了,符合WYSIWYG原则)
七:再见了,= 和 ==
C/C++里面的一个臭名昭著的bug就是if(x == y)写成了if (x = y),这个bug不会再出现在Python里面了!因为Python的赋值语句并不返回赋值后的对象。
Python解释器不允许if x = y的语句。
有得必有失,少了这个臭名昭著的bug,Python的代价就是不能写类似于while(cin>>aInt)的语句了。
八:while和for里面的else
Python在while和for里面加入了else元素,减少了标志位的使用。
for x in L:
if y:
break
else:
……
这样我就能区分for循环结束是因为遍历结束还是因为break出来了。(在C++里面就要设置个)
八:一切都是类
Python是单根继承结构,一切类都是object的派生类,函数也不例外。Python内部定义了一个类function,用户定义的每个函数都是function类的一个实例,function类比较特别的地方就是它重载了()运算符,并且构造function对象的方式不是调用其构造函数。

上述函数定义可以看作是f = function(),由于Python的变量名都是引用,f 就是一个function实例的引用,所以也就不难理解a = f这样的语法了。
更劲爆的是:类的名称也是引用了一个类的实例而已。

这就有点绕了,一个类是另一个类的实例,而两个类都继承自object?鸡生蛋?蛋生鸡?……
九:Special Variables
很多程序会把调试代码放在if __name == "__main__"后面。
其实,__name__就是解释器在运行这个文件的时候预先定义的一个变量名而已,完全可以被改掉。(但是大概不会有人去改动吧……)
其他一些解释器预定义的变量如下图所示:
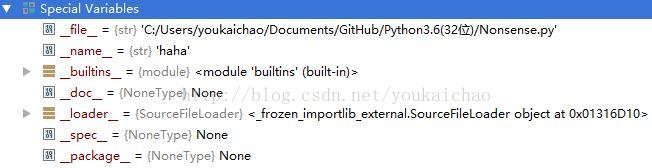
导入其他文件的时候,我们会import a(如果同级目录有个a.py),其实这时候也就是在这个文件里创建了一个名为a的变量,
a.__name__ == "a", a.__file__ == "(a.py的绝对路径)".不过在执行一个文件的时候,解释器会修改__name__ = "__main__".
十:左闭右开区间
在很多地方的区间都是左闭右开的,如range的范围。C++的STL里面的很多函数接受两个迭代器表示的范围,这个范围也是左闭右开的(C++本来就有end表示尾后迭代器)。
左闭右开区间有哪些好处?
1:区间可加性[a, b) + [b, c) ==> [a, c)
2.元素个数表示方法简单。如果是双闭区间[a, b],ab都是整数,那么元素个数是 b - a + 1,如果是多个区间的元素个数,那就要搞死人了。中学数学里面,加一减一可是个严重失分点!而左闭右开区间[a, b)的元素个数就好数了,就是b - a了。