jvm 优化记录
1.背景
敏感词服务拆分后,在staging 环境压测。发现cpu 和 内存监控都飙高。在单机qps 200左右的情况下,cpu 使用率平均80+,young gc 次数平均200+ ,平均一次gc 耗时 20ms 左右 。
注:YGC是JVM GC 最为频繁的一种GC,一个高并发的服务在运行期间,会进行大量的YGC,发生YGC时,会进行STW,一般时间都很短。 不过如果次数太多,势必会影响服务所能承担的理论qps上限。同时如果再未来引入更高的业务复杂度时,很有可能会影响old 区,进而影响整个服务的可用性。
2. 过程
首先cpu 问题定位热点代码
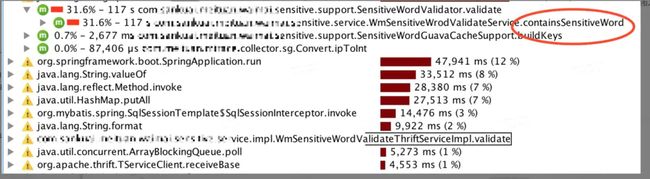
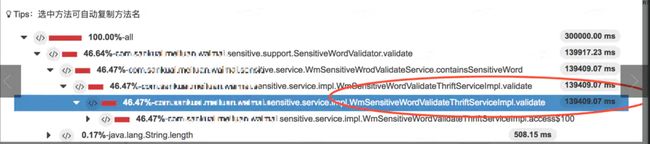
通过工具定位到热点代码,containsSensitiveWord 。定位到代码中发现,这个方法一共做了两件事 1. 全表contains (index of )2. 正则表达式匹配。
初步怀疑是正则表达式比较消耗cpu 资源。
定位: 注释掉正则表达式的代码,观察压测报告,发现cpu load 和 young gc 基本没有变化。 再注释掉contains 的代码之后发现cpu 明显降低。
由此可以得到的结论是:cpu load 高的罪魁祸首是contains 的 index of 导致的。这部分可以通过未来的DFA算法优化,或者接入nlp 自然语言处理解决,暂时可以先放一放。
但是一个比较奇怪的现象是。注释掉contains 之后young gc 只降低了20% 左右,还是每秒150次。
indexof 没有使用kmp 算法https://www.zhihu.com/question/27852656
2. 内存消耗
一分钟将近200 次的young gc 显然是不合理的,那么下一步就是排查到底哪里消耗的内存资源。
首先观察 gc 日志
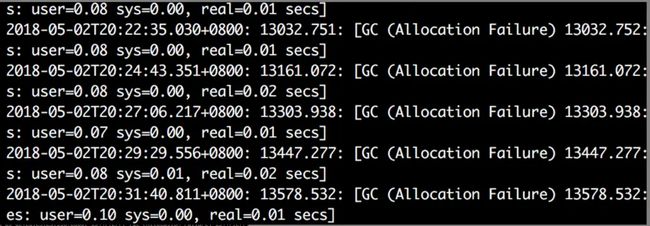
发现在没有访问量的时候,平均两分钟一次young gc。
怀疑1:
eden 区使用率飙高,最直接的想法是内存不够,目前压测机器模仿线上机器采用的是8核8g ,其中堆内存大小为6g,young 区默认1/3,也就是2g,eden 区 与survive区默认 8:1 ,eden 区约为1.7g 左右。
所以首先怀疑是堆内存不够。
证明:申请更大内存的机器,堆内存调整为12g。
预期:young 区 使用率与 young gc 会大幅降低,理论上至少是之前的一半左右。
结果:调整之后,在相同qps 200左右的时候,young gc 频率降低的十分不明显,从之前的200次,降低到160次左右。远达不到预期效果。
结论:看起来内存小并不是造成young区使用飙高的原因,暴力扩容虽然能缓解一些问题,也只是治标不治本。而且目前线上机器资源不足,如此高配的机器资源根本申请不下来。
怀疑2:
观察gc 日志,发现在无流量的情况下每 2-3分钟会发生一次young gc。
首先想到业务代码中的定时任务每分钟会到数据库load 全量数据,是不是这个过程中创建的大量临时变量,充斥内存。导致请求量上来以后频繁gc。
证明:观察jstat gc状态看是不是每一分钟定时跑的任务触发的young 区飙升。
预期:每隔5s 观察一次内存状况,应该每隔一分钟,内存有一个激增,两到三次左右会激增达到eden 区的临界点,导致一次young gc 。
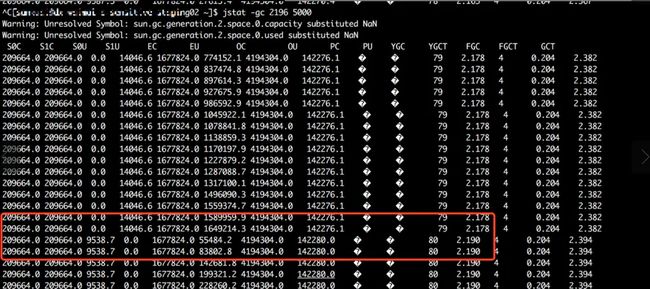
结果: 长期观察jvm 堆内存状态,发现是在平稳增长,并没有预期的每过一分钟会有一个Eden 区的激增。配合查看线程堆栈信息,发现都是cat 埋点和jmonitor 监控相关的线程,没有发现有业务代码。
结论: 基本可以排除这种情况。
怀疑3:
当压测时,模拟单机qps 200,敏感词的校验逻辑是:每个关键字跟全量的敏感词做比对,这时候会根据用户的区域信息,门店信息等筛选出一个map,根据这个临时生成的map,跟全量的敏感词做比对。所以怀疑是在此过程中的临时变量创建占用大量的Eden 区。 由于map 内的数据结构只支持对象,所以在基本数据类型到对象类型转化的时候,涉及到java 内存的自动装箱,拆箱机制,这个过程会有临时变量的建立的销毁,有至少两倍的内存浪费。
java 装箱/拆箱原理请自行google
2. 同时根据map 默认大小16,所以构建一个10000+ 大小的map 至少需要扩容10次。每次扩容涉及到map 的复制,所以内存的消耗,远大于实际的String 大小。
证明:在压测场景下dump 内存。通过工具分析。
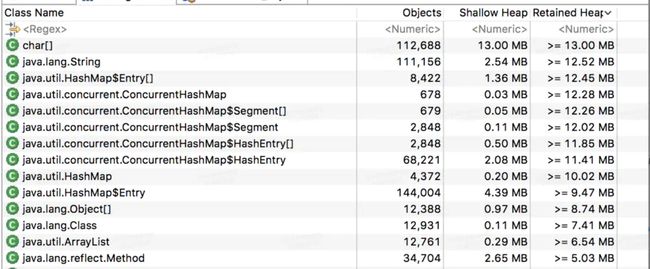
暂时先忽略排在前面的char String 等基本类型数据,可以看到后面的几个都是map 数据,间接从侧面证明了,内存疯涨跟map 有关系。
解决方案:1.尽量复用代码中的map,不要每个请求过来都组装一个新的map。 具体操作:因为校验大体按照两部分来做,一部分是根据每个商家的tag 类型和区域来做差异化的敏感词校验。另一部分是全量商家都需要做的校验。 目前db 中的存量数据有百分之七十五以上是走的全量校验,考虑可以缓存这部分数据,不用每次请求来了都去构建新的map,避免内存浪费。
2. 根据目前业务量预估map 的初始容量大小,避免频繁扩容与内存浪费。 这个大小可以放到mcc中根据业务的变化手动配置一下。
预期:如果eden区内存飙高是由这个map 构造导致的,那么复用一部分map ,预期可以降低大部分的内存消耗,理论上可以大幅降低young gc 次数。
效果
多次压测平均,young gc 减少了40% 左右 ,在 110 次左右,有了一个明显的降低。cpu load 降低20%左右 ,同时响应时间减少20%左右。
虽然有大幅的降低,但是young gc 依然在一个高位,所以还有进一步优化的空间。
进一步观察dump 下来的内存。刚刚的内存报告有一个奇怪的地方,为什么dump 下来的内存如此少呢,最大也就几十兆。 打开unreachable object 观察:
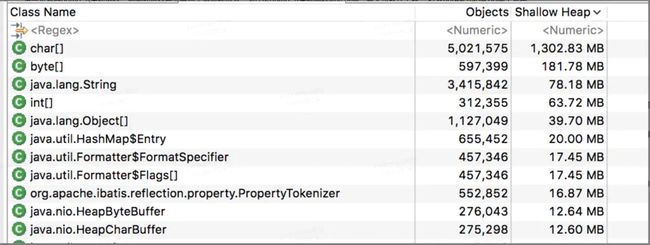
可以看到在unreachable 里面有1.5g 左右的内存,这样加起来正好就是eden 区的内存总和。那么这些内存是什么呢,所谓的unreachable 并不是内存泄漏,而是已经被垃圾回收器标记为不可达的对象,这部分对象即将在下一次的gc 回收,也就是那部分朝生夕死的对象。所以问题的症结还是在校验的逻辑里面。只能再从头过一遍代码。
校验的逻辑其实十分简单,就是一个 万级别数据的全量contains ,打开jdk 源码,观察contains 并没有使用比较流行的KMP 算法,而是选择了滑动窗口的方式,但是这种方式对cpu 是一个消耗,但是空间复杂度并不高,为了验证,注释掉了 contains 的代码,继续观察压测报告,发现cpu 使用率大幅降低,但是young gc 进一步减少了25% 左右,依然保持100左右的频率。
怀疑4:
观察代码中还有一个 String 的 split 操作,split 里面支持了正则表达式,同时split 源码是通过 substring 截取字符串,subString 空间复杂度是O(N) , 然后外层通过 subList 方法从新拼接成list ,
subList 的空间复杂度也是O(N),所以合起来空间复杂度就是O(N2)。
解决:通过list 替换String 拼接。
压测实验: young gc 大幅降低到原来的20% ,同时响应时间降低1.5 倍左右
压测报告:
附:《常见性能优化策略的总结》https://tech.meituan.com/performance_tunning.html