【TensorFlow-windows】keras接口——卷积核可视化
前言
在机器之心上看到了关于卷积核可视化相关理论,但是作者的源代码是基于fastai写的,而fastai的底层是pytorch,本来准备自己用Keras复现一遍的,但是尴尬地发现Keras还没玩熟练,随后发现了一个keras-vis包可以用于做卷积核可视化。以下理论是在不熟悉fastai的运行机制的基础上做的简单理解,可能有误,欢迎指正。
国际惯例,参考博客:
40行Python代码,实现卷积特征可视化
github:visualizing-cnn-feature-maps
Keras Visualization Toolkit
理论
简单概率为一句话就是:优化输入以最大化指定层特征图的平均激活。
先贴一下GitHub上的可视化部分代码:
class FilterVisualizer():
def __init__(self, size=56, upscaling_steps=12, upscaling_factor=1.2):
self.size, self.upscaling_steps, self.upscaling_factor = size, upscaling_steps, upscaling_factor
self.model = vgg16(pre=True).cuda().eval()
set_trainable(self.model, False)
def visualize(self, layer, filter, lr=0.1, opt_steps=20, blur=None):
sz = self.size
img = np.uint8(np.random.uniform(150, 180, (sz, sz, 3)))/255 # generate random image
activations = SaveFeatures(list(self.model.children())[layer]) # register hook
for _ in range(self.upscaling_steps): # scale the image up upscaling_steps times
train_tfms, val_tfms = tfms_from_model(vgg16, sz)
img_var = V(val_tfms(img)[None], requires_grad=True) # convert image to Variable that requires grad
optimizer = torch.optim.Adam([img_var], lr=lr, weight_decay=1e-6)
for n in range(opt_steps): # optimize pixel values for opt_steps times
optimizer.zero_grad()
self.model(img_var)
loss = -activations.features[0, filter].mean()
loss.backward()
optimizer.step()
img = val_tfms.denorm(img_var.data.cpu().numpy()[0].transpose(1,2,0))
self.output = img
sz = int(self.upscaling_factor * sz) # calculate new image size
img = cv2.resize(img, (sz, sz), interpolation = cv2.INTER_CUBIC) # scale image up
if blur is not None: img = cv2.blur(img,(blur,blur)) # blur image to reduce high frequency patterns
self.save(layer, filter)
activations.close()
def save(self, layer, filter):
plt.imsave("layer_"+str(layer)+"_filter_"+str(filter)+".jpg", np.clip(self.output, 0, 1))
很容易发现,可视化流程为:
- 载入训练好的模型,设置权重为不可训练
- 随机初始化一个噪声,预处理一下,并将其转换为可训练张量,也就是可以对这个输入求梯度,我们以前的神经网络是对权重求梯度去优化权重,这里刚好反过来,是对输入求梯度去优化梯度
- 目标损失就是想要可视化的卷积核对应的特征图的平均激活值。额外多一句嘴,都知道卷积核的大小是 ( m , n , s 1 , s 2 ) (m,n,s1,s2) (m,n,s1,s2)大小,其中 m m m是上一层特征图数目, n n n是卷积核个数也是下一层特征图的个数,所以每一个卷积核对应下一层特征图其中的一个,也就说每个特征图都是独立的,只和与它相关的那一个卷积核有关,我们想可视化第几个卷积核,平均激活就这个卷积核对应的特征图的平均值。
- 接下来就是在一定迭代次数内不断更新对输入求梯度并更新输入值,这就是输入从噪声到特征响应图的可视化过程。
如果用公式表示就是:
i n p u t = i n p u t − l e a r n _ r a t e × ∂ l o s s ∂ i n p u t input=input - learn\_rate\times\frac{\partial loss}{\partial input} input=input−learn_rate×∂input∂loss
区分于传统的训练神经网络时候的:
w = w − l e a r n _ r a t a × ∂ l o s s ∂ w w=w-learn\_rata\times \frac{\partial loss}{\partial w} w=w−learn_rata×∂w∂loss
至于外层还有一个循环是,迭代完opt_steps后,将当前更新完的输入resize成一个大点的尺寸,再迭代,如此反复折腾,至于原因,在机器之心的文章上有写:
我们现在有了一个分辨率好得多的低频模式,并且没有太多的噪音。为什么这样做会有用呢?我的想法是:当我们从低分辨率开始时,我们会得到低频模式。放大后,放大后的模式图相比直接用大尺度图像优化生成的模式图有较低的频率。因此,在下一次迭代中优化像素值时,我们处于一个更好的起点,看起来避免了局部最小值。这有意义吗?为了进一步减少高频模式,我在放大后稍微模糊了图像。
我发现以 1.2 的倍数放大 12 次之后得到的结果不错。
Keras-vis工具包的使用
预备工作
-
导入模型与载入权重
from keras.applications import VGG16 model=VGG16(weights='imagenet',include_top=True)查看模型每层的名字,以便后续可视化
model.summary()输出
Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0
可视化最后一层全连接层
因为最后一层是全连接层,使用softmax激活,本质是将最后一层归一化得到属于每一类的概率,所以他的每个节点与其它节点相关,这就是softmax的特殊性。反观其它层,每个特征图或者全连接的节点都是互相独立的。所以为了消除最后一层受到softmax导致各节点不独立的影响,在优化的时候使用线性激活替代softmax激活,方法如下:
引入相关包:
from vis.utils import utils
from keras import activations
用名字找到最后一层的索引,并更改它的激活函数
layer_idx=utils.find_layer_idx(model=model,layer_name='predictions')
model.layers[layer_idx].activation=activations.linear
model=utils.apply_modifications(model)
接下来就可以可视化了
引入相关包
from vis.visualization import visualize_activation
import matplotlib.pyplot as plt
不迭代可视化,结果不太整洁
img=visualize_activation(model,layer_idx=layer_idx,filter_indices=20)
plt.imshow(img)

迭代可视化,结果会整洁一点
img=visualize_activation(model,layer_idx=layer_idx,filter_indices=20,max_iter=500,verbose=False)
plt.imshow(img)

加入Jitter,获得更好的可视化结果:
#得到更加干净的可视化结果图
from vis.input_modifiers import Jitter
img=visualize_activation(model=model,layer_idx=layer_idx,filter_indices=20,max_iter=500,verbose=False,input_modifiers=[Jitter(16)])
plt.imshow(img)

可视化任意层卷积核
以block3_conv3的第56个卷积核为例
layer_idx=utils.find_layer_idx(model=model,layer_name='block3_conv3')
img=visualize_activation(model=model,layer_idx=layer_idx,filter_indices=56,verbose=False,input_modifiers=[Jitter(16)])
plt.imshow(img)

看着像饼干。
可视化响应热度图
通过最后一层全连接层可视化可以发现,第20个权重会响应鸟嘴和上半身的羽毛,试试将一只鸟丢进去,看看最终响应的部位。
先引入对应包:
import numpy as np
import matplotlib.cm as cm
from vis.visualization import visualize_cam,overlay
读取图像,以及三种显示方案(区别我也不清楚,没看):
img=utils.load_img('ouzel1.jpg',target_size=(224,224))
modifier=[None,'guided','relu']

可视化
i=0
for m in modifier:
plt.subplot(str(13)+str(i))
layer_idx=utils.find_layer_idx(model=model,layer_name='predictions')
grads=visualize_cam(model,layer_idx,filter_indices=20,seed_input=img,backprop_modifier=modifier[0])
jet_heatmap=np.uint8(cm.jet(grads)[...,:3]*255)
plt.imshow(overlay(jet_heatmap,img))
i=i+1

不太放心,再试试第379个节点响应的什么,从类别标签上看,第379个标签是howler_monkey,应该是一种猴子,可视化响应内容看看:
img=visualize_activation(model=model,layer_idx=layer_idx,filter_indices=379,max_iter=300,verbose=False,input_modifiers=[Jitter(16)])
plt.imshow(img)
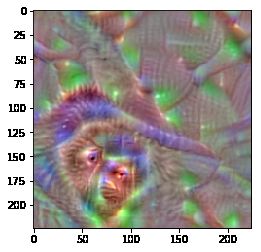
看着像猴子,应该有猴脸和尾巴。
找一张猴子

看看响应情况:
img=utils.load_img('monkey.jpg',target_size=(224,224))
i=0
for m in modifier:
plt.subplot(str(13)+str(i))
layer_idx=utils.find_layer_idx(model=model,layer_name='predictions')
grads=visualize_cam(model,layer_idx,filter_indices=379,seed_input=img,backprop_modifier=modifier[0])
jet_heatmap=np.uint8(cm.jet(grads)[...,:3]*255)
plt.imshow(overlay(jet_heatmap,img))
i=i+1

Bingo~~!!响应了猴子脸
后记
此博客只介绍了Keras_vis包中的部分功能,其余功能以后有机会再探索,博客介绍的卷积核可视化与响应热度图还是比较有用的。
博客代码:
百度网盘链接:https://pan.baidu.com/s/1SpcSoPkQE6aWx2HfoXX-Aw
提取码:xuox
好久没写博客, 逃~~