Elasticsearch 入门学习
没有聚餐和旅游的春节假期,正好学习一下阮一鸣老师的《Elasticsearch 核心技术与实战》,下面是对 Elasticsearch 里的一些入门知识的学习和总结:
什么是 Elasticsearch ?
- 使用 java 语言开发的一套开源的全文搜索引擎
- 用于搜索、日志管理、安全分析、指标分析、业务分析、应用性能监控等多个领域
- 底层基于 Lucene 开源库开发,提供 restAPI,可以被任何语言调用
- 支持分布式部署,可水平扩展
- 更新迭代快、社区活跃、文档丰富
什么是 ELK ?
Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案,可以使用它来搭建可视化的日志分析平台。其中 Elasticsearch 就是本文要讲的开源分布式搜索引擎,经常和它一起使用还有 Logstash,Kibana,Beats,Cerebro,这些工具是用来做什么的呢?
应用程序 -> beats -> [redis | kafka | rabbitMQ] -> logstash -> elasticSearch -> [grafana | kibana]
Logstash
Logstash 是一个用于管理日志的工具,可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如将数据提供给 Elasticsearch 使用。
- 实时解析和数据转换
- IP 地址解析,隐藏敏感信息
- 扩展性强,有丰富的插件
- 安全性强,可以对数据传输进行加密
Kibana
Kibana 也是一个开源和免费的数据可视化工具,可以为 ElasticSearch 提供友好的日志分析 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
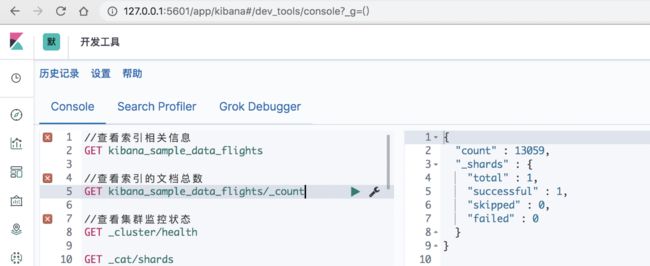
Kibana 还提供了一个非常友好的开发工具,是学习 Elasticsearch 必备的 repl 工具,大家可以使用该工具尝试测试和验证 Elasticsearch 中的一些 restAPI 是如何工作的。
Beats
beats 是一组轻量级采集程序的统称,由 go 语言开发,负责日志收集,并将将收集到的数据发送给 Logstash 或者 Elasticsearch。elastic 官方支持的 5 种 Beats:
- filebeat: 进行文件和目录采集,主要用于收集日志数据。
- metricbeat: 进行指标采集,指标可以是系统的,也可以是众多中间件产品的,主要用于监控系统和软件的性能。
- packetbeat: 通过网络抓包、协议分析,对一些请求响应式的系统通信进行监控和数据收集,可以收集到很多常规方式无法收集到的信息。
- Winlogbeat: 专门针对 windows 的 event log 进行的数据采集。
- Heartbeat: 系统间连通性检测采集,比如 icmp, tcp, http 等系统的连通性监控。
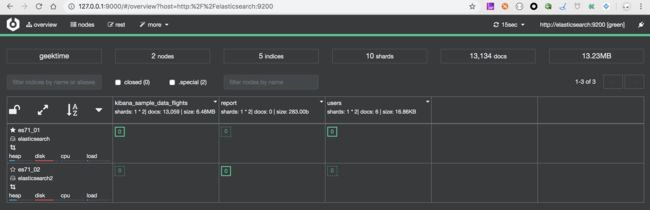
Cerebro
Cerebro 是 Elasticsearch 集群的监控管理工具,使用 Cerebro 我们可以 Elasticsearch 的节点运行情况,磁盘占用情况,并进行实时报警
Elasticsearch 的基础概念
集群(Cluster)
- Elasticsearch 集群部署使其可以随时可用和并按需扩容,并保证数据的安全性
- 通过启动参数 cluster.name 修改集群名称,默认名称为 elasticsearch
- 下面我们部署一个集群,包括三个节点,默认是 9200 端口启动,启动后通过 http://127.0.0.1:9200 可以查看运行情况
bin/elasticsearch -E node.name=node1 -E cluster.name=myEs -d
bin/elasticsearch -E node.name=node2 -E cluster.name=myEs -d
bin/elasticsearch -E node.name=node3 -E cluster.name=myEs -d
节点(Node)
- 一个节点是一个 Java 进程实例,一台机器可以运行多个实例,一般情况下一台机器只允许一个节点
- 一个集群有一个或者多个节点
- 通过启动参数 node.name 定义节点名称
- 每个节点都保存了集群的状态信息,只有 Master 节点可以修改集群的状态信息
- 集群状态信息包括:所有节点信息、索引、Mapping、Settings、分片路由等信息
- Master-eligible 节点:
- 每个节点启动,默认自己是一个 Master-eligible 节点
- 可以通过启动参数 node.master: false 禁止当前启动节点是 Master-eligible 节点
- 所有 Master-eligible 都可以参与选主流程,成为 Master 节点
- Data 节点:
- 保存分片数据的节点
- 在数据扩展上起了很大的作用
- 通过启动参数 node.data 设置
- Coordinating 节点
- 接收客户端请求,将请求分发到合适的节点,最终再对结果进行汇集
- 每个节点默认都是 Coordinating 节点
- Hot & Warm 节点:硬件配置不同的节点
- Machine Learning 节点:机器学习,用来自动异常检测,自动报警,通过启动参数 node.ml 进行设置
索引(Index)
- 一个集群下面可以新建多个索引,索引体现了逻辑空间概念
- 索引是一类相似文档的集合,是文档的容器,类比关系型数据库中的一张表的 Schema 的概念
- 每个索引有自己的 Mapping 用于定义文档的字段名和字段类型
- 每个索引有自己的 Settings 用于定义不同的数据分布,也就是索引使用分片的情况
分片(Shard)
- 分片是物理空间概念,索引中的数据都分布在分片上
- 一个分片就是运行的一个 Lucene 的实例
- 分片分为主分片和副分片,一般主分片和副分片应该分布在不同的节点上
- 主分片用于解决数据水平扩展的问题,主分片的数目在索引创建后指定,后续不容许修改(number_of_shards)
- 副分片用来解决数据高可用问题,是主分片的拷贝,数量可以动态调整(number_of_replicas)
- 分片数的设定
- 分片数设置太小,影响后续水平扩展,单个分片数据量太大将导致数据重新分配耗时
- 分片数设置过大,影响搜索结果的相关性打分,影响搜索结果数据准确性
- 分片数设置过大,导致单个节点上会有过多的分片,资源浪费,浪费性能
文档(Document)
- 文档是所有可搜索数据的最小单位,类似关系数据库中某张表中的一行记录
- 文档会被序列化成 JSON 格式,JSON 对象由字段组成
- 每个字段都有对应的字段类型,类型可以自己指定,也可以使用 ElasticSearch 自动推算
- JSON 文档支持数组和嵌套
- 每个文档都有一个唯一性 ID,可以自己指定,也可以系统自动生成
- 一个文档主要的元信息如下:
1. _index: 文档所属的索引名
2. _type: 文档所属的类型名
3. _id: 文档的唯一ID
4. _source: 文档存储的 Json 数据
5. _version:文档的版本信息
6. _score: 相关性打分
Elasticsearch 插件
Elasticsearch 还提供了插件功能,用户可以根据自己的需求安装相应的插件满足搜索,分析,安全,管理,数据备份等功能,比如我们可以安装 elasticsearch-analysis-ik 来满足我们的中文分词功能。
- bin/elasticsearch-plugin install 安装插件
- bin/elasticsearch-plugin list 展示插件列表
- 可以访问 localhost:9200/_cat/plugins 接口显示已经安装的插件
Elasticsearch 类比关系型数据库
Elasticsearch 相对关系型数据库,更适合相关性、高性能全文检索,并且支持 restAPI 调用,而关系型数据库更适合事务性要求较强的场景,以下是两者概念上的类比:
| 关系型数据库 | ElasticSearch |
|---|---|
| Table | Index |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL(domain-specific language) |
倒排索引
Elasticsearch 使用一种称为”倒排索引"的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表,这样可以通过某个单词快速的找到其所在的文档:
- 倒排索引包含两部分:单词词典(Team Dictionary)和倒排列表(Posting List)
- 单词词典记录单词到倒排列表的关联关系,一般通过 B+ 树或者哈希链表实现
- 倒排列表记录单词对应的文档结合,由倒排索引项组成
- 倒排索引项由文档ID(docId),词频(term frequencies),单词位置(term postion),偏移量(character offsets)组成
- ElasticSearch 中默认会对文档中的每个字段做倒排索引,可以强行指定不对某些字段设置倒排索引
分词器
- Analysis 是把全文本转换为一系列单词的过程,也叫分词
- Analysis 通过 Analyzer 分词器实现,可以使用 ElasticSearch 内置的分词器或者定制化分词器
- 在写入文档和搜索查询时都需要用到分词器
- 在写入文档数据时,需要对 TEXT 字段做分词然后建立倒排索引
- 在搜索查询时,需要对输入的查询语句进行分词,然后通过倒排索引进行搜索
- Analyzer 分词器的组成:
1. Character Filters: 对原始文本进行预处理,比如去除 HTML,字符串替换,正则匹配替换
2. Tokenizer: 按照规则切分单词,ES 内置的有 whitespace/standard/uax_url_email/pattern/keyword/path hierarchy 等 Tokenizer
3. Token Filter: 对切分的单词进行加工,例如小写转换(Lowercase),删除 stopwords(stop),增加同义词(synonym)等
- ElasticSearch 内置分词器有:
Standard Analyzer:默认分词器,按词切换,小写处理
Simple Analyzer: 按照非字母切分,小写处理
Stop Analyzer: 小写处理,停用词过滤
Whitespace Analyzer:按照空格切分,不转换小写
Keyword Analyzer: 不分词,直接将输入当作输出
Patter Analyzer: 正则表达式分词
Language Analyzer:提供 30 多种常见语言的分词器
Customer Analyzer:自定义分词器
- 常用的中文分词器:
- icu_analyzer: bin/elasticsearch-plugin install analysis-icu
- ik: bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip
- thulac: https://github.com/microbun/elasticsearch-thulac-plugin
关于 Mapping
Mapping 主要用于定义索引的字段名称和数据类型以及倒排索引等相关配置,Mapping 可以系统自动推断生成,也可以由用户自己定义,下面我们看一个简单 Mapping 的格式:
//该索引包含三个字段
//name,类型是 long,不支持索引搜索
//phone,类型是 keyword,对于值为空的情况可以使用"NULL"字符串来搜索
//name,类型是 text,并定义了索引级别,以及自定义的分词器
{
"mappings" : {
"properties" : {
"id" : {
"type" : "long",
"index": false
},
"name" : {
"type" : "text",
"index_options": "positions",
"copy_to": "fullName",
"fields": {
"english_comment":{
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
}
}
},
"phone" : {
"type" : "keyword",
"null_value": "NULL"
}
}
}
}
字段的属性
- type:字段的数据类型,并没有提供专门数组类型,通过 TEXT 字段实现,Elasticsearch 主要支持以下几种数据类型:
- Text:默认情况下会进行分词
- Keyword:不会进行分词,全文本匹配
- Date:日期类型
- Integer/Floating:整数/浮点数
- Boolean:布尔类型
- IPv4 & IPv6
- 特殊类型:geo_point & geo_shape & percolator
- index:表示该字段是否可以被搜索,是否需要建立倒排索引
- index_options 属性:控制倒排索引记录的内容,内容越多,占用空间越大,text 类型默认是 positions,其它默认是 docs
- docs: 记录 docId
- freqs:记录 docId 和 term frequencies
- positions:记录 docId 和 term frequencies 和 term postion
- offsets:记录 docId 和 term frequencies 和 term postion 和 character offsets
- null_value:默认情况下 null 是无法被直接搜索的,如果需要对 Null 值进行搜索,可以设置该属性,表示 null 值被当成什么来搜索
- copy_to:将值拷贝到对应的字段上,多个字段可以同时 copy_to 到同一个字段上,用于对于多个字段同时查询,目标字段不会出现在 mapping 的定义中,但是可以用于搜索
- fields: 多字段特性,可以增加一个 keyword 字段,可以为搜索和索引指定不同的分词器等
Index Template
PUT _template/test_template
{
"index_patterns": ["test*"], // 什么样的 index 会使用这个模板
"order": 1, // 设置模板的优先级
"settings": {
"number_of_shards": 1, // shard 的数量
"number_of_replicas": 2 //replication 的数量
},
"mappings": {
"date_detection": false, //字符串的日期类型是否自动转换
"numeric_detection": true //字符串的数字类型是否自动转换
}
}
- 帮助你设定 Mappings 和 Settings,并按照一定的规则,自动匹配到新创建的索引之上
- Index Template 只是对于一个新创建的索引才起作用
- 可以通过 order 参数来控制模板的优先级
- 一个 Elasticsearch 可以设置多个 Index Template
- 创建一个索引时,按照以下顺序配置其 Settings 和 Mappings,后面的覆盖前面的配置
- ES 默认的 Settings 和 Mappings
- order 数值低的 Index Template
- order 数值高的 Index Template
- 用户对于当前索引指定的 Settings 和 Mappings
Dynamic Mapping
在写入文档时,如果索引不存在 ES 会自动创建索引,并且会根据用户写入的数据按照上面介绍的逻辑自动推断每个字段的类型和配置,每个索引有一个 dynamic 属性来控制动态推断逻辑,该属性只会对新增数据写入起作用:
- 当 dynamic 属性 true 时,当有有新字段的文档写入时,Mapping 也会同时被按照推荐自动更新
- 当 dynamic 属性 false 时,当有有新字段的文档写入时,Mapping 不会被更新,新增字段无法被索引,但是信息会出现在文档的 _source 属性中
- 当 dynamic 属性是 Strict 时,文档不可以被写入,当然字段也不可以被索引,数据写入时直接报错
- 对已有字段,一旦有数据写入,就不再支持修改字段定义,因为建立了倒排索引后就不允许修改了,如果希望修改字段类型,必须 Reindex API,重建索引
同时 Elasticsearch 还支持用户定义 Dynamic Template 来通过字段名称来动态设置字段类型:
PUT my_test_index
{
"mappings":{
"dynamic_template": {
"path_match": "name.*", //字段以 name 开头
"path_unmatch": "*.middle", //字段以 middle 结尾
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
}
- 根据 ES 识别的数据类型,结合字段名称来动态设置字段类型
- 与 Index Template 不同,Dynamic Template 是定义在某个具体的索引下的
常用的 RestAPI
文档的 CURD
- PUT {index_name}/_create/{id}:增加一条文档记录,必须保证对应 ID 的文档不存在
- POST {index_name}/_update/{id}:不会删除原先文档,实现真正的数据更新,可以增加字段或者修改某些字段
//对索引 users 中 ID = 1 的文档进行更新操作
POST users/_update/1
{
"doc": {
"user": "chenmangmanga",
"message": "learning elasticSearch",
"class": "one",
"age": 30
}
}
- PUT {index_name}/_doc/{id}:新增一条文档记录,如果记录已经存在,则删除原先文档,版本信息会加 1
- POST {index_name}/_doc/:新增一条文档记录,ID 会自动生成
- GET {index_name}/_doc/{id}:根据 ID 获取某一文档记录
- DELETE {index_name}/_doc/{id}:根据删除一条文档
- POST _bulk:文档的批量增删改
/*
- 支持在一次 API 调用中对不同的索引进行操作
- 支持 INDEX/Create/Update/Delete 四种类型的操作
- 单条记录操作失败,并不会影响其它操作
- 返回结果中包括了每一条操作执行的结果
*/
POST _bulk
{"index": {"_index": "users", "_id": "1"}}
{"user": "yangzhiwei2"}
{"delete":{"_index": "users", "_id": "2"}}
{"create":{"_index": "users", "_id": "3"}}
{"user": "zhuweilin","message": "learning elasticSearch","age": 35}
{"update":{"_index":"users","_id": "1"}}
{"doc":{"user": "helloworld"}}
- GET _mget: 批量读取文档数据
GET _mget
{
"docs": [{
"_index": "users",
"_id": 1
},{
"_index": "users",
"_id": 3
},{
"_index": "users",
"_id": 2
}]
}
文档的搜索
文档的搜索分为 URI Search 和 Request Body Search 两种方式,URI Search 主要在 URL 中通过 query string 的方式传参进行查询,方便简单;Request Body Search 是通过 POST 的请求体 Body 的方式传参进行搜索,支持丰富的搜索格式,下面是搜索相关的 rest API 如下:
- POST|GET /_search: 对集群中所有的索引进行搜索
- POST|GET /index1,index2/_search:搜索索引 index1 和 index2
- POST|GET /index*/_search: 搜索以 index 开头命名的索引
搜索结果的是否合理,主要取决于搜索的相关性,搜索相关性由下面三个属性决定:
- 查准率:尽可能返回较少的无关文档
- 查全率:尽量返回较多的相关文档
- 排名:是否可以按照相关度进行排序
URI Search 相关示例
//搜索 users 索引下,user 字段包含 chenmangmanga,并对搜索结果按照 year 降序,获取前 10 个搜索结果,搜索超时时间为 1 秒
GET users/_search?q=user:chenmangmanga&sort=year:desc&from=0&size=10&timeout=1s
{
"profile": true
}
- q: 指定查询语句
- df: 指定查询的默认字段
- sort:按照什么字段进行排序
- from/size:用于分页
- profile:可以查看查询是如何被执行的
- timeout:查询超时时间
Query String Syntax
对于上面查询查询语句 q 字段,Elasticsearch 支持丰富的搜索格式:
- 普通查询
1. q=status:active:表示搜索 status 字段中包含 active 的文档
- 布尔查询
1. q=title:(quick OR brown): 表示搜索 title 字段中包含 quick 或者 brown 的文档,等同于 q=title:(quick brown) 或者 q=title:(quick || brown)
2. q=title:(quick AND brown): 表示搜索 title 字段中包含 quick 并且包含 brown 的文档,等同于 q=title:(quick && brown) 或者 q=title:(quick +brown)
3. q=author:"John Smith": 表示搜索 author 字段中包含 John Smith 的文档
4. q=_exists_:title:表示搜索 title 字段为非 null 的文档
5. q=title:(quick NOT brown): 表示搜索 title 字段中包含 quick 并且不包含 brown 的文档,q=title:(quick ! brown) 或者 q=title:(quick -brown)
- 范围查询
1. q=date:[2012-01-01 TO 2012-12-31]:查询 date 字段在 2012-01-01 和 2012-12-31 之间的文档
2. q=count:[10 TO *]:count 字段大于 10 的范围查询
3. q=age:(>=10 AND <20):查询 age 字段大于等于 10 且小于 20 的文档
- 通配符查询
通配符占用内存大,一般情况下不建议使用
1. q=status:act?ve*a:“?”表示匹配一个任意字符,“*”表示匹配0个或者多个任意字符
- 正则查询
1. q=name:/joh?n(ath[oa]n)/
- 模糊查询和近似查询
1. q=title:befutifl~1 : 表示增加,删除,替换,或者字符位置转换不超过1的模糊匹配
2. q=title:"lord rings"~2:表示lord 和 rings 中间不超过2个字符的模糊匹配情况
Request Body Search 示例
将查询语句通过 HTTP Request Body 的形式发送给 Elasticsearch,支持非常丰富的查询格式,详情请参考官方文档
POST users/_search
{
"profile": "true", //输出ES是如何执行查询的
"query": {
"match": { //user字段匹配 chenmangmanga 或者 zhuweil
"user": {
"query": "chenmangmanga, zhuweil",
"operator": "OR"
}
}
},
"_source": ["user", "age"], //只返回部分字段
"from": 0, //分页
"size": 2,
"sort": [{"age": "desc"}], //排序,支持多个字段排序
"script_fields": {
"newField": { //通过脚本生成新的字段
"script": {
"lang": "painless",
"source": "doc['age'].value + '_hello'"
}
}
}
}
聚合分析
类似关系型数据库,Elasticsearch 同样支持丰富的聚合运算,可以根据某个维度对数据进行求和,平均值,最大值等运算,并可以进行二次聚合运算:
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs":{
"flight_dest":{
"terms":{
"field":"DestCountry" //根据字段 DestCountry 进行聚合
},
"aggs":{
"avg_price":{ // 求 AvgTicketPrice 的平均值
"avg":{
"field":"AvgTicketPrice"
}
},
"wather":{
"terms": {
"field": "DestWeather", // 二次聚合,求每个 DestCountry 下每个 DestWeather 的情况
"size": 5
}
}
}
}
}
}
Elasticsearch 中聚合主要分为以下几类:
- Bucket Aggregation: 对满足特定条件的文档的聚合,分成不同的桶,类似关系型数据库中的 Group By
- Metric Aggregation:一些数学运算,可以对文档字段进行统计分析,比如最大值,最小值,平均值的计算等
- Pipeline Aggregation:对其它的聚合结果进行二次聚合
- Matrix Aggregation:支持对多个字段的操作并提供一个结果矩阵
其它 API
- GET _cluster/health: 查看集群的健康状态
- GET {index_name}: 查看对应索引的状态
- GET {index_name}/_count:查看索引的文档总数
- POST /_analyze: 使用某个分词器对文本进行分词
POST /_analyze
{
"analyzer": "standard",
"text": "hello world, you are right"
}
- GET {index_name}/_mapping:查看 mapping 定义
- DELETE {index_name}:删除索引
- PUT {index_name}:修改 mapping 定义
PUT users/_mapping
{
"dynamic": "false"
}
- PUT /_template/template_test:定义 Index Template
参考文献
- Elasticsearch从入门到放弃:文档CRUD要牢记
- 全文搜索引擎 Elasticsearch 入门教程
- ELK和beats