深度学习初学的一些理解感悟
阅读目录
- 深度学习初学的一些概念
- 张量
- 模型
- batch
- epochs
- 有监督学习
- 无监督学习
- 回归
- Relevant Link
- 深度学习小例子(1)
- 深度学习小例子(2)
深度学习初学的一些概念
常见的深度学习框架有 TensorFlow 、Caffe、Theano、Keras、PyTorch、MXNet等,本文后续代码主要在keras框架基础;
神经网络的主要任务:是在学习时找到最优的参数(权重和偏置)
张量
张量的阶数有时候也称为维度,或者轴,轴这个词翻译自英文axis。譬如一个矩阵[[1,2],[3,4]],是一个2阶张量,有两个维度或轴,沿着第0个轴(为了与python的计数方式一致,本文档维度和轴从0算起)你看到的是[1,2],[3,4]两个向量,沿着第1个轴你看到的是[1,3],[2,4]两个向量。
import numpy as np
a = np.array([[1,2],[3,4]])
# axis=0 就是普通的相加
sum0 = np.sum(a, axis=0) #output array([4, 6])
# axis=1以后就是将一个矩阵的每一行向量相加
sum1 = np.sum(a, axis=1) #output array([3, 7])
模型
只要这个东西接收一个或一些张量作为输入,然后输出的也是一个或一些张量。
batch
深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这称为Batch gradient descent,批梯度下降。
缺点: 计算量开销大,计算速度慢,不支持在线学习。
第二种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。
缺点: 这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,找不到最优点。
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
基本上现在的梯度下降都是基于mini-batch的,所以Keras的模块中经常会出现batch_size,就是指这个。
epochs
epochs指的就是训练过程中数据将被“轮”多少次
有监督学习
在有监督学习中,每一个例子都是一对由一个输入对象(通常是一个向量)和一个期望的输出值(也被称为监督信号)
无监督学习
无监督学习里典型例子是聚类。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
回归
回归,指研究一组随机变量(Y1 ,Y2 ,…,Yi)和另一组(X1,X2,…,Xk)变量之间关系的统计分析方法
Relevant Link
keras文档: https://keras-cn.readthedocs.io/en/latest/
python和numpy: https://zhuanlan.zhihu.com/p/20878530
深度学习小例子(1)
import keras
from keras.layers import Dense, Activation, Dropout
from keras.models import Sequential
import numpy as np
import matplotlib.pyplot as plt
# 创建数据
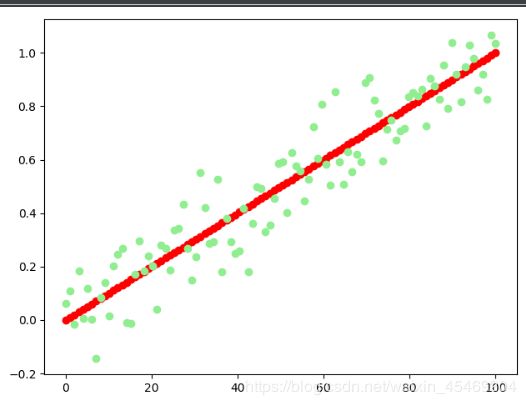
# y_train的值为x_train的1倍,但增加了一些随机扰动
# X1用于绘制数据关系坐标轴
X1 = np.linspace(0, 100, 100)
x_train = np.linspace(0, 1, 100)
y_train = x_train + np.random.randn(*x_train.shape) * 0.1
# 训练数据关系可视化
plt.plot(X1, x_train, 'o', color='red')
plt.plot(X1, y_train, 'o', color='lightGreen')
plt.show()
# 创建模型
# 序贯模型(Sequential)是多个网络层的线性堆叠,也就是“一条路走到黑”。
# 上一层layer的output 是下一层layer的input
model = Sequential()
# Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。
model.add(Dense(1, input_shape=(1,)))
model.add(Activation('linear'))
# 通过compile来对学习过程进行配置
# 优化器optimize
# 损失函数loss
# 指标列表metrics
model.compile(loss='mean_squared_error', optimizer='sgd')
model.summary()
# 训练模型
# 上面模型创建好之后还只是一个空壳子,我们还需要加入训练数据训练神经网络
# 训练模型的作用就是在找最优的参数(权重和偏置)
# 训练数据的 周期 和 数据量可以改改再看看预测的效果
# 训练数据集里面的值的大小在 0 - 1 之间, 使用模型预测 一下 6 或者更大一些的数,模型的效果可能就不是很好了;
model.fit(x_train, y_train, nb_epoch=200, verbose=1)
# 使用模型预测
model.predict([1])
print(model.predict([1]))
# output [[0.692492]]
深度学习小例子(2)
例子参考 https://keras-cn.readthedocs.io/en/latest/getting_started/sequential_model/#_2
# 对于具有10个类的模型(分类):
import keras
from keras.layers import Dense, Activation, Dropout
from keras.models import Sequential
import numpy as np
import matplotlib.pyplot as plt
# 创建数据属于10个类
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Convert labels to categorical one-hot encoding
# 作用就是将 1,2,3...,10 转换为 一个shape为(10,10)的array;例如2 转化为-->[0,0,1,0,0,0,0,0,0,0]
# 应该 对训练模型有益...
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# 模型创建,就不再累述了
model = Sequential()
model.add(Dense(100, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(data, one_hot_labels, epochs=100, batch_size=32)
# 使用模型预测
print(model.predict(data[0:2]))
# output:
# [[4.1218773e-02 5.1796947e-02 2.4182981e-02 5.6548748e-04 4.3373513e-03
# 2.8838582e-02 3.0747369e-01 4.6388701e-02 6.6133025e-03 4.8858422e-01]
# [4.0255722e-02 1.1894414e-02 7.8763850e-02 6.7141401e-03 1.7611199e-03
# 1.4457579e-03 1.4719557e-02 8.1880512e-03 1.2570604e-02 8.2368684e-01]]
# 模型训练的最后准确率在80%左右
# 预测输出的第一行的最大值是第10个,查看labels的值,发现为9,说明预测正确;
# 同理输出的第二行的最大值也是第10个,查看labels的值,发现为9,说明预测正确;