使用Jsoup爬取网站信息(以天猫为例)
http://download.csdn.net/detail/lostchris/9432552
上面是案例。。。
过年的时候一直想弄点网络爬虫好为今年毕业论文提供数据准备。。。
楼主先后试过httpClient,jsoup,htmlunit发现还是jsoup好用,
httpClient用起来繁琐,还有个乱码问题要解决。。。
htmlunit虽然功能强大能获取执行JS后的网页内容,但是非常不稳定,加上htmlunit执行JS时间不可知,htmlunit对JS格式要求严格,部分网站采用的JS格式不太标准(不太碍事的那种),htmlunit就会抛错,还有一点htmlunit耗时太长。。。
相对其他两种,jsoup使用起来简洁容易上手,soup 也是一款基于Java 的HTML解析器,可直接解析某个URL地址或HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
使用jsoup一般来说需要注意的只有一点。。。就是要设置userAgent....在1.8.3版本里org.jsoup.Connection有单独的方法设置
例如Connection conn=Jsoup.connect(url).userAgent("");
如果没设置userAgent,可能会造成你有一些网站可以爬取,有些会抛错,应该是因为权限问题。。。你需要设置userAgent模拟浏览器去获取网页
关于案例并没有详细解析,注释。。。重点是要去分析别人的网站
天猫搜索商品的url一般为https://list.tmall.com/search_product.htm?q="+urlWord+"&type=p&redirect=notRedirect&sort=p (基本上适用)
urlWord是你要搜索商品的关键字...这里需要用URLEncoder.encode(word, "utf-8")将关键字转为url编码字符串
sort=p表示搜索结果按价格从低到高排序
爬取天猫搜索商品页面还需要referrer
HTTPReferrer是header的一部分,当浏览器向web服务器发出请求的时候,一般会带上Referer,告诉服务器用户从那个页面连接过来的,服务器藉此可以获得一些信息用于处理。
设置referrer跟userAgent一样 用conn.referrer(String)就可以了
天猫referrer "https://list.tmall.com/search_product.htm?q=" + urlWord
+ "&type=p&spm=a220m.1000858.a2227oh.d100&from=.list.pc_1_suggest"
这样我们就可以爬取天猫的页面了

下面就需要分析天猫的分页了
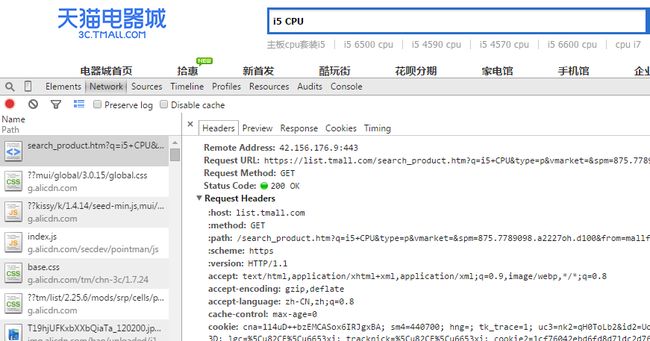
下面我们来看看参数
这是第一页的注意
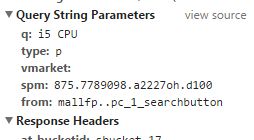
当我们点击第二页时
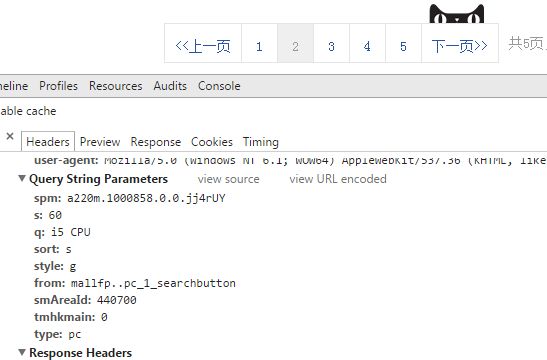
我们可以看见多了一个参数是数字的 s:60 没错这就是分页所需的参数,楼主已经验证过了,天猫分页每页是60
第一页s:0 第二页s:60 第三页s:120如此类推...
Jsoup设置参数非常简单直接conn.data(...)就OK
好了这里再发验证对比图
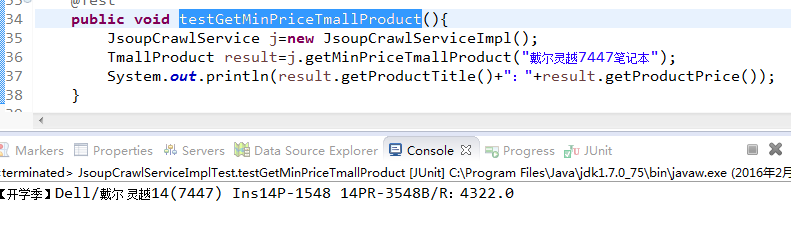
天猫里搜索结果
OK,详细实现请看案例项目。。。有什么问题欢迎留言