飞桨paddlepaddle强化学习打卡营
总体评价:课程的定位很精确,因为时间受限,不可能从理论推导开始教学。面向应用的方式,会积累一定学习的兴趣,也便于后续的学习。课程知识的分布也比较合理,分别是:面对离散动作的Q-learning和Sarsa;因为不可数的动作和状态组合与神经网络结合(拟合的方式),面向连续动作的DQN,采取随机策略的policy-gradient以及采取确定性策略的DDPG。这些只能算是RL最入门基础的算法(只包括应用),之后对原理的学习需要补齐。
个人感受:首先用PARL实现RL算法的框架性很强(针对每一类算法而言),对于初学者而言需要改变的决定算法本质的数行代码。其次,RL对复杂问题的训练时间真的很长,需要耐心。然后,相比于调参,算法或者技巧的作用要更大(在大作业中体现非常明显)。最后,科科老师天下第一。
Day1初步了解相关概念:
1.基本组成:所以本质就是agent做出与env的交互,通过其执行action和得到reward
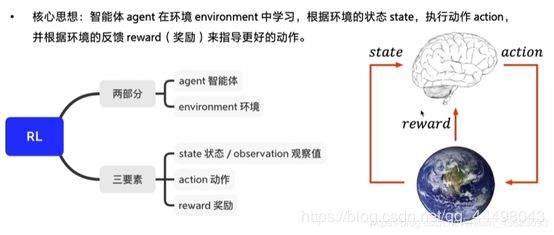
2.强化学习(RL)给的是延迟奖励,即机器做出预测后才会给出反馈。
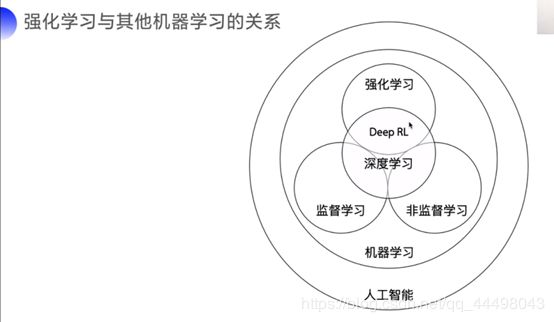
3.强化学习和深度学习的关系:两者有交集,即深度强化学习(DeepRL,利用类似supervised learning的模型结合RL的方法,输出action)
4.与监督学习的区别:强化学习是决策,监督学习是认知(比如遇到一头熊向你招手,RL给出装死或者快跑,监督学习说这就是头熊;当熊向你冲来,RL给你快装死(因为生存几率大),supervised learning给你说这还是头熊啊)
5.Agent学习的两种方案:基于价值(value-based)具体的算法有(确定性策略):Sarsa、DQN、Q-learning;基于策略(policy-based),具体的算法有(随机性策略):policy-gradient。
总体评价:
基于价值会向固定方向走,基于策略随机性更高一些。
6.gym是一个(可视化的)RL评估环境。核心接口是environment,核心的接口有以下:reset(),step(action),render()。
step(action)做的就是一步交互,返回observation(对环境的观察),reward(奖励,有正负),done(是否需要重置)和info(调试信息)。
7.PARL是百度的一个RL算法库,性能据说全世界领先。而且集群部署很灵活。

Day 2 可数动作
python基础相关:
1.np.random.uniform(0, 1) 在一定范围内,样点均匀分布,随机取样(定义是左开右闭)#常用于根据table的Q值选动作
2.np.random.choice(a, size=None, replace=True, p=None)从a中抽取size个,replace表示是否放回抽取 #用于有一定概率随机探索选取一个动作
1. Q-learning简介
• Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与Sarsa是一样的,采用ε-greedy方式增加探索。
• Q-learning跟Sarsa不一样的地方是更新Q表格的方式。
• Sarsa是on-policy的更新方式,先做出动作再更新。
• Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。
• Q-learning的更新公式为:
![]()
2. Sarsa 简介
• Sarsa全称是state-action-reward-state’-action’,目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
![]()
• Sarsa在训练中为了更好的探索环境,采用ε-greedy方式来训练,有一定概率随机选择动作输出。
ε-greed方法:
本质是一种以一定概率探索的策略,对应到代码中:首先,建立的agent包含此成员;其次,在采样输出动作的时候。

Q-learning和sarsa区别
简单讲就是Target_Q更新(分别是Q-learning和Sarsa)
Q-learning选的是Q的下一步观测值列最大值,(off-policy)不需要at+1(下一步实际执行的动作),默认下一个action就是最优的动作。(相当于就是“胆子更大”,表现为贴着悬崖走)
Sarsa选的是Q【下一步观测值】【下一步动作】,只优化策略(on-policy 离悬崖最远)
对应到代码中的区别就如下:
![]()

学习策略和与环境交互的策略上:
Q-learning:一个目标策略,一个行为策略
Sarsa:相同都是目标策略
Day3 DQN
为了解决Day2遇到的使用Q表格存储状态数量有限的问题,引出DQN的神经网络求解RL的方法。本质是用神经网络近似替代Q表格。
DQN本质还是Q-learning算法,也同样可以使用
ε-greedy的方法训练。
除此之外,DQN还使用了两个tricks使得网络的更新迭代更稳定。
1.
经验回放 Experience Replay:主要解决样本关联性和利用效率的问题。使用一个经验池存储多条经验s,a,r,s’,再从中随机抽取一批数据送去训练。
举个例子:类似于一个军师(traget policy)一个士兵(behavior policy),士兵通过战斗获取经验传给经验池(append方法),军师不断总结经验(sample方法取)更新Q表格。相当于是军师可以从replay memory随机取(消除时间关联)batch_size的经验。
2.固定Q目标 Fixed-Q-Target:主要解决算法训练不稳定的问题。复制一个和原来Q网络结构一样的Target Q网络,用于计算Q目标值。
Model 和target_Model(sync方法把model同步到targetmodel)
Q和target_Q
用Q网络产生action,targetQ产生Q目标值,网络就是优化二者之间的loss(learn函数的作用)#DQN的精髓
DQN训练模型的大体框架如下
1.模型训练的超参数:LEARN_FREQ(不是每个step都学习,这是一个积攒经验的做法)、
MEMORY_SIZE(replay占用内存,经验池,实现trick:经验回放)、
MEMORY_WARMUP_SIZE(预存的经验)、
BATCH_SIZE(从replay memory每次读取个数)、
LEARNING_RATE(学习率)、
GAMMA(reward的衰减因子)。
2.搭建model、Algorithm、Agent
Model:神经网络结构,包括网络结构定义,值传递(输入输出与网络结构的函数关系)
Algorithm:定义损失函数更新model。比如一个DQN算法类,参数有model,action空间的维度,gamma,lr。其中的predict函数就是通过model前向传播得到action。learn函数:先计算target_Q(记得阻止target_model的梯度传递,因为paddle优化器会找到并更新所有相关参数),获取预测Q,计算二者均方差的到loss,结果扔给优化方法。
Day4 Policy-gradient策略梯度求解策略
从这一节开始训练市场大幅度增加,老师说6h是正常情况。
1.基于策略(policy-based)直接输出动作概率。
区别:
value-based产生Q网络、优化Q网络,间接确定策略。输出的是确定策略。
policy-base 神经网络拟合policy直接输出动作概率,采样随机输出动作。
例如:石头剪刀布,训练好的Q网络输出的是固定的;而另一个不固定。
2.优化方向:每个episode总reward最大。
policy网络的action没有标签,用目标函数Rθ确定优化方向(梯度上升过程)。
- Loss函数类比cross entrophy(但是需要乘一个奖励回报Gt,根据这个标识优化力度)
需要注意,policy-gradient只是一种想法。在解决实际问题时,用的是算法。比如Day4解决Carpole问题时用的是REINFORCE算法。
Day5 DDPG
提出的目的是为了解决DQN无法输出连续动作。首先用于仿真的环境必然是连续动作的输入。其次,在继承DQN经验回放和固定Q网络的方法后,使用Actor-Critic的模型结构(这里的名字是一个形象地类比)
既然最后的大作业拿了第一,就来分析一下我的解决方法。我的探索过程大概持续了三天三夜(训练过程睡觉)。
首先,使用Day5给出的DDPG参考代码是无法达到老师给的效果的。最高的测试成绩大概在5600左右。可能有以下几种原因:输出的动作并不是相近的,收敛性真的不好;训练轮数或者超参数的原因(个人认为可以基本排除:大致50万步得到了100万步中最好的成绩,超参数也经过了调整,效果并不好)。
其次,老师提到当输出的4个动作值相近的时候比较容易收敛。这个在讨论区有同学做过了测试,完全相等没有这个效果。于是可以想到对于每一个动作,应该是基础值上加一个小的偏移量。我一开始的做法是对所有输出求平均再加上自己本身值的0.01倍,训练结果不是很好。反思可能的原因是:平均值由于是由4个动作的输出确定,网络在优化的时候无法跨过这个mean求梯度(不是针对性的优化)。
之后有大佬在群里说把网络输出size改成5。在与环境交互前,通过一个主值加上剩余四个的一定倍数(0.2),作为Actor输出的 动作。经过一晚上的训练,得到了最后9700的评分。这里对动作值调整的位置有一定的讲究:

这一步我测试过,要想达到如此效果必须加在探索前。(原因未知)
由于此时官方评分标准对100分的要求是过14000。所以我扒了以下PARL在Github中给的DDPG的demo。发现区别在于Model(actor和Critic)的结构不同,于是又去改这部分。结果没有简单结构的成绩高。(原因未知)