Hive常用函数整理
一、Hive
Hive是建立在 Hadoop 上的数据仓库基础架构,定义了简单的类 SQL 查询语言(HQL),以实现MR功能,其提供的一系列函数同样类似于SQL函数。
二、分类
函数分类方式很多,个人将其分为简单内置函数,高级内置函数以及自定义函数。简单内置函数包括一些运算符,如关系运算符、算术运算符、逻辑运算符,数学函数,日期函数,字符函数,类型转换函数,条件函数,聚合函数等。高级内置函数即由聚合函数等组成的具有一定分析性的函数(表达可能不是很准确)。自定义函数即通过自己写代码定义的具有特定功能的函数。本文挑一部分进行整理。
基本函数:
1.数学函数
round(double d, int n):返回保留n位小数的近似d值
floor(double d): 返回小于d的最大整值
ceil(double d): 返回大于d的最小整值
rand(int seed): 返回随机数,seed是随机因子
bin(int d): 计算二进制值d的string值
2.日期函数
to_date(string timestamp):返回时间字符串中的日期部分,如to_date('1970-01-01 00:00:00')='1970-01-01'
current_date:返回当前日期
year(date):返回日期date的年,类型为int如year('2019-01-01')=2019
month(date):返回日期date的月,类型为int,如month('2019-01-01')=1
day(date): 返回日期date的天,类型为int,如day('2019-01-01')=1
weekofyear(date1):返回日期date1位于该年第几周。如weekofyear('2019-03-06')=10
datediff(date1,date2):返回日期date1与date2相差的天数,如datediff('2019-03-06','2019-03-05')=1
date_add(date1,int1):返回日期date1加上int1的日期,如date_add('2019-03-06',1)='2019-03-07'
date_sub(date1,int1):返回日期date1减去int1的日期,如date_sub('2019-03-06',1)='2019-03-05'
months_between(date1,date2):返回date1与date2相差月份,如months_between('2019-03-06','2019-01-01')=2
add_months(date1,int1):返回date1加上int1个月的日期,int1可为负数。如add_months('2019-02-11',-1)='2019-01-11'
last_day(date1):返回date1所在月份最后一天。如last_day('2019-02-01')='2019-02-28'
next_day(date1,day1):返回日期date1的下个星期day1的日期。day1为星期X的英文前两字母如next_day('2019-03-06','MO') 返回'2019-03-11'
trunc(date1,string1):返回日期最开始年份或月份。string1可为年(YYYY/YY/YEAR)或月(MONTH/MON/MM)。如trunc('2019-03-06','MM')='2019-03-01',trunc('2019-03-06','YYYY')='2019-01-01'
unix_timestamp():返回当前时间的unix时间戳,可指定日期格式。如unix_timestamp('2019-03-06','yyyy-mm-dd')=1546704180
from_unixtime():返回unix时间戳的日期,可指定格式。如select from_unixtime(unix_timestamp('2019-03-06','yyyy-mm-dd'),'yyyymmdd')='20190306'
3.条件函数
if(boolean,t1,t2):若布尔值成立,则返回t1,反正返回t2。如if(1>2,100,200)返回200
case when boolean then t1 else t2 end:若布尔值成立,则t1,否则t2,可加多重判断
coalesce(v0,v1,v2):返回参数中的第一个非空值,若所有值均为null,则返回null。如coalesce(null,1,2)返回1
isnull(a):若a为null则返回true,否则返回false
4.字符串函数
length(string1):返回字符串长度
concat(string1,string2):返回拼接string1及string2后的字符串
concat_ws(sep,string1,string2):返回按指定分隔符拼接的字符串
lower(string1):返回小写字符串,同lcase(string1)。upper()/ucase():返回大写字符串
trim(string1):去字符串左右空格,ltrim(string1):去字符串左空格。rtrim(string1):去字符串右空格
repeat(string1,int1):返回重复string1字符串int1次后的字符串
reverse(string1):返回string1反转后的字符串。如reverse('abc')返回'cba'
rpad(string1,len1,pad1):以pad1字符右填充string1字符串,至len1长度。如rpad('abc',5,'1')返回'abc11'。lpad():左填充
split(string1,pat1):以pat1正则分隔字符串string1,返回数组。如split('a,b,c',',')返回["a","b","c"]
substr(string1,index1,int1):以index位置起截取int1个字符。如substr('abcde',1,2)返回'ab'
5.聚合函数
count():统计行数
sum(col1):统计指定列和
avg(col1):统计指定列平均值
min(col1):返回指定列最小值
max(col1):返回指定列最大值
6.表生成函数
与聚合函数相反,将字段内复杂的数据拆分成多行。
explode (array):返回多行array中对应的元素。如explode(array('A','B','C'))返回

explode(map):返回多行map键值对对应元素。如explode(map(1,'A',2,'B',3,'C'))返回

explode常用来做行列转换。
进阶函数:
1.窗口函数
常用的分析类函数有如下:
row_number() over(partitiion by .. order by .. ):根据partition排序,相同值取不同序号,不存在序号跳跃
rank() over(partition by .. order by .):根据partition排序,相同值取相同序号,存在序号跳跃
dense_rank() over(partition by .. order by ..):根据partition排序,相同值取相同序号,不存在序号跳跃
sum() over(partition by .. order by ..)
count() over(partition by .. order by ..)
lag(col,n) over(partition by .. order by ..) :查看当前行的上第n行
lead(col,n) over(partition by .. order by ..):查看当前行的下第n行
first_value() over(partition by .. order by ..):满足partition及排序的第一个值
last_value() over(partition by .. order by ..):满足partition及排序的最后值
ntile(n) over(partition by .. order by ..):满足partition及排序的数据分成n份
partition内更细的划分,可使用windows子句。常见子句为:
preceding:往前
following:往后
current row:当前行
unbounded:起点,unbounded preceding 表示从前面的起点, unbounded following:表示到后面的终点
使用如:
sum(col) over(partition by .. order by .. rows between 1 preceding and current row):当前行与前一行做聚合
2.高级聚合函数
grouping sets
cube
rollup
3.行列转换
concat_ws(sep, collect_set(col1)) :同组不同行合并成一列,以sep分隔符分隔。collect_set在无重复的情况下也可以collect_list()代替。collect_set()去重,collect_list()不去重
lateral view explode(split(col1,',')) :同组同列的数据拆分成多行,以sep分隔符区分
示例:
原表如下:
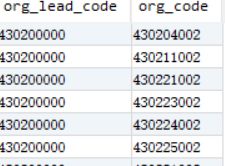
select org_lead_code,concat_ws(',',collect_set(org_code)) from tmp1 group by org_lead_code
合并后:

再拆分:
select org_lead_code,c2 from tmp2 lateral view explode(split(c1,',')) b as c2